 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Cartographer: From Mapping to Reasoning Over Counterfactual Worlds
May 20, 2025Causal world models are systems that can answer counterfactual questions about an environment of interest, i.e. predict how it would have evolved if an arbitrary subset of events had been realized differently. It requires understanding the underlying causes behind chains of events and conducting causal inference for arbitrary unseen distributions. So far, this task eludes foundation models, notably large language models (LLMs), which do not have demonstrated causal reasoning capabilities beyond the memorization of existing causal relationships. Furthermore, evaluating counterfactuals in real-world applications is challenging since only the factual world is observed, limiting evaluation to synthetic datasets. We address these problems by explicitly extracting and modeling causal relationships and propose the Causal Cartographer framework. First, we introduce a graph retrieval-augmented generation agent tasked to retrieve causal relationships from data. This approach allows us to construct a large network of real-world causal relationships that can serve as a repository of causal knowledge and build real-world counterfactuals. In addition, we create a counterfactual reasoning agent constrained by causal relationships to perform reliable step-by-step causal inference. We show that our approach can extract causal knowledge and improve the robustness of LLMs for causal reasoning tasks while reducing inference costs and spurious correlations.
Robust Domain Generalisation with Causal Invariant Bayesian Neural Networks
Oct 08, 2024



Deep neural networks can obtain impressive performance on various tasks under the assumption that their training domain is identical to their target domain. Performance can drop dramatically when this assumption does not hold. One explanation for this discrepancy is the presence of spurious domain-specific correlations in the training data that the network exploits. Causal mechanisms, in the other hand, can be made invariant under distribution changes as they allow disentangling the factors of distribution underlying the data generation. Yet, learning causal mechanisms to improve out-of-distribution generalisation remains an under-explored area. We propose a Bayesian neural architecture that disentangles the learning of the the data distribution from the inference process mechanisms. We show theoretically and experimentally that our model approximates reasoning under causal interventions. We demonstrate the performance of our method, outperforming point estimate-counterparts, on out-of-distribution image recognition tasks where the data distribution acts as strong adversarial confounders.
Counterfactual Causal Inference in Natural Language with Large Language Models
Oct 08, 2024



Causal structure discovery methods are commonly applied to structured data where the causal variables are known and where statistical testing can be used to assess the causal relationships. By contrast, recovering a causal structure from unstructured natural language data such as news articles contains numerous challenges due to the absence of known variables or counterfactual data to estimate the causal links. Large Language Models (LLMs) have shown promising results in this direction but also exhibit limitations. This work investigates LLM's abilities to build causal graphs from text documents and perform counterfactual causal inference. We propose an end-to-end causal structure discovery and causal inference method from natural language: we first use an LLM to extract the instantiated causal variables from text data and build a causal graph. We merge causal graphs from multiple data sources to represent the most exhaustive set of causes possible. We then conduct counterfactual inference on the estimated graph. The causal graph conditioning allows reduction of LLM biases and better represents the causal estimands. We use our method to show that the limitations of LLMs in counterfactual causal reasoning come from prediction errors and propose directions to mitigate them. We demonstrate the applicability of our method on real-world news articles.
Recurrence over Video Frames for the Re-identification of Meerkats
Jun 18, 2024



Deep learning approaches for animal re-identification have had a major impact on conservation, significantly reducing the time required for many downstream tasks, such as well-being monitoring. We propose a method called Recurrence over Video Frames (RoVF), which uses a recurrent head based on the Perceiver architecture to iteratively construct an embedding from a video clip. RoVF is trained using triplet loss based on the co-occurrence of individuals in the video frames, where the individual IDs are unavailable. We tested this method and various models based on the DINOv2 transformer architecture on a dataset of meerkats collected at the Wellington Zoo. Our method achieves a top-1 re-identification accuracy of $49\%$, which is higher than that of the best DINOv2 model ($42\%$). We found that the model can match observations of individuals where humans cannot, and our model (RoVF) performs better than the comparisons with minimal fine-tuning. In future work, we plan to improve these models by using pre-text tasks, apply them to animal behaviour classification, and perform a hyperparameter search to optimise the models further.
Can Large Language Models Learn Independent Causal Mechanisms?
Feb 04, 2024



Despite impressive performance on language modelling and complex reasoning tasks, Large Language Models (LLMs) fall short on the same tasks in uncommon settings or with distribution shifts, exhibiting some lack of generalisation ability. This issue has usually been alleviated by feeding more training data into the LLM. However, this method is brittle, as the scope of tasks may not be readily predictable or may evolve, and updating the model with new data generally requires extensive additional training. By contrast, systems, such as causal models, that learn abstract variables and causal relationships can demonstrate increased robustness against changes in the distribution. One reason for this success is the existence and use of Independent Causal Mechanisms (ICMs) representing high-level concepts that only sparsely interact. In this work, we apply two concepts from causality to learn ICMs within LLMs. We develop a new LLM architecture composed of multiple sparsely interacting language modelling modules. We introduce a routing scheme to induce specialisation of the network into domain-specific modules. We also present a Mutual Information minimisation objective that trains a separate module to learn abstraction and domain-invariant mechanisms. We show that such causal constraints can improve out-of-distribution performance on abstract and causal reasoning tasks.
Behaviour Modelling of Social Animals via Causal Structure Discovery and Graph Neural Networks
Dec 21, 2023

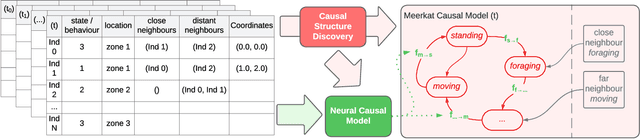
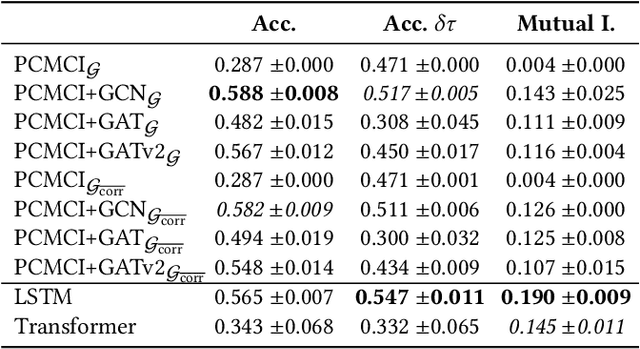
Better understanding the natural world is a crucial task with a wide range of applications. In environments with close proximity between humans and animals, such as zoos, it is essential to better understand the causes behind animal behaviour and what interventions are responsible for changes in their behaviours. This can help to predict unusual behaviours, mitigate detrimental effects and increase the well-being of animals. There has been work on modelling the dynamics behind swarms of birds and insects but the complex social behaviours of mammalian groups remain less explored. In this work, we propose a method to build behavioural models using causal structure discovery and graph neural networks for time series. We apply this method to a mob of meerkats in a zoo environment and study its ability to predict future actions and model the behaviour distribution at an individual-level and at a group level. We show that our method can match and outperform standard deep learning architectures and generate more realistic data, while using fewer parameters and providing increased interpretability.
Meerkat Behaviour Recognition Dataset
Jun 20, 2023


Recording animal behaviour is an important step in evaluating the well-being of animals and further understanding the natural world. Current methods for documenting animal behaviour within a zoo setting, such as scan sampling, require excessive human effort, are unfit for around-the-clock monitoring, and may produce human-biased results. Several animal datasets already exist that focus predominantly on wildlife interactions, with some extending to action or behaviour recognition. However, there is limited data in a zoo setting or data focusing on the group behaviours of social animals. We introduce a large meerkat (Suricata Suricatta) behaviour recognition video dataset with diverse annotated behaviours, including group social interactions, tracking of individuals within the camera view, skewed class distribution, and varying illumination conditions. This dataset includes videos from two positions within the meerkat enclosure at the Wellington Zoo (Wellington, New Zealand), with 848,400 annotated frames across 20 videos and 15 unannotated videos.
Large Language Models Are Not Abstract Reasoners
May 31, 2023Large Language Models have shown tremendous performance on a large variety of natural language processing tasks, ranging from text comprehension to common sense reasoning. However, the mechanisms responsible for this success remain unknown, and it is unclear whether LLMs can achieve human-like cognitive capabilities or whether these models are still fundamentally limited. Abstract reasoning is a fundamental task for cognition, consisting of finding and applying a general pattern from few data. Evaluating deep neural architectures on this task could give insight into their potential limitations regarding reasoning and their broad generalisation abilities, yet this is currently an under-explored area. In this paper, we perform extensive evaluations of state-of-the-art LLMs on abstract reasoning tasks, showing that they achieve very limited performance in contrast with other natural language tasks, and we investigate the reasons for this difference. We apply techniques that have been shown to improve performance on other NLP tasks and show that in most cases their impact on abstract reasoning performance is limited. In the course of this work, we have generated a new benchmark for evaluating language models on abstract reasoning tasks.
Disentanglement of Latent Representations via Sparse Causal Interventions
Feb 02, 2023



The process of generating data such as images is controlled by independent and unknown factors of variation. The retrieval of these variables has been studied extensively in the disentanglement, causal representation learning, and independent component analysis fields. Recently, approaches merging these domains together have shown great success. Instead of directly representing the factors of variation, the problem of disentanglement can be seen as finding the interventions on one image that yield a change to a single factor. Following this assumption, we introduce a new method for disentanglement inspired by causal dynamics that combines causality theory with vector-quantized variational autoencoders. Our model considers the quantized vectors as causal variables and links them in a causal graph. It performs causal interventions on the graph and generates atomic transitions affecting a unique factor of variation in the image. We also introduce a new task of action retrieval that consists of finding the action responsible for the transition between two images. We test our method on standard synthetic and real-world disentanglement datasets. We show that it can effectively disentangle the factors of variation and perform precise interventions on high-level semantic attributes of an image without affecting its quality, even with imbalanced data distributions.
A Survey of Methods, Challenges and Perspectives in Causality
Feb 02, 2023The Causality field aims to find systematic methods for uncovering cause-effect relationships. Such methods can find applications in many research fields, justifying a great interest in this domain. Machine Learning models have shown success in a large variety of tasks by extracting correlation patterns from high-dimensional data but still struggle when generalizing out of their initial distribution. As causal engines aim to learn mechanisms that are independent from a data distribution, combining Machine Learning with Causality has the potential to bring benefits to the two fields. In our work, we motivate this assumption and provide applications. We first perform an extensive overview of the theories and methods for Causality from different perspectives. We then provide a deeper look at the connections between Causality and Machine Learning and describe the challenges met by the two domains. We show the early attempts to bring the fields together and the possible perspectives for the future. We finish by providing a large variety of applications for techniques from Causality.