 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnecting Context-specific Adaptation in Humans to Meta-learning
Dec 01, 2020
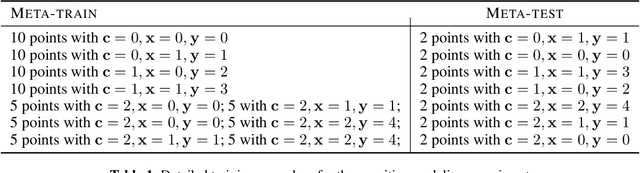


Cognitive control, the ability of a system to adapt to the demands of a task, is an integral part of cognition. A widely accepted fact about cognitive control is that it is context-sensitive: Adults and children alike infer information about a task's demands from contextual cues and use these inferences to learn from ambiguous cues. However, the precise way in which people use contextual cues to guide adaptation to a new task remains poorly understood. This work connects the context-sensitive nature of cognitive control to a method for meta-learning with context-conditioned adaptation. We begin by identifying an essential difference between human learning and current approaches to meta-learning: In contrast to humans, existing meta-learning algorithms do not make use of task-specific contextual cues but instead rely exclusively on online feedback in the form of task-specific labels or rewards. To remedy this, we introduce a framework for using contextual information about a task to guide the initialization of task-specific models before adaptation to online feedback. We show how context-conditioned meta-learning can capture human behavior in a cognitive task and how it can be scaled to improve the speed of learning in various settings, including few-shot classification and low-sample reinforcement learning. Our work demonstrates that guiding meta-learning with task information can capture complex, human-like behavior, thereby deepening our understanding of cognitive control.
Recovery RL: Safe Reinforcement Learning with Learned Recovery Zones
Oct 29, 2020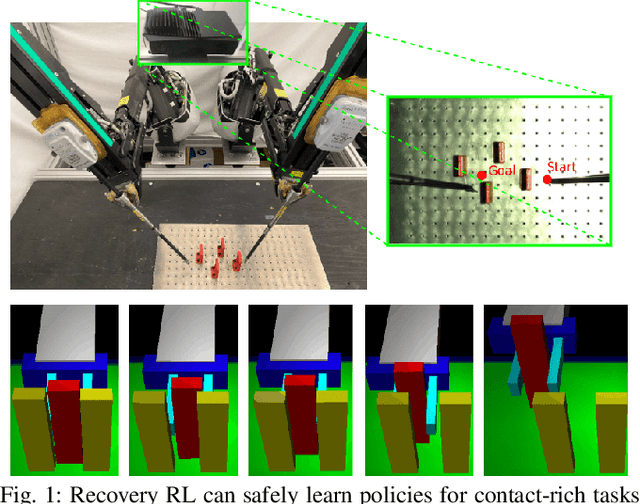
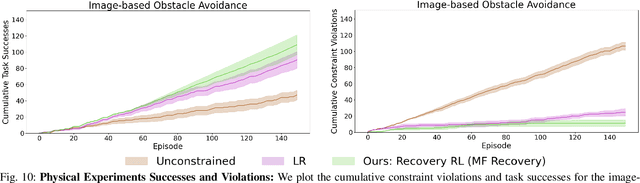
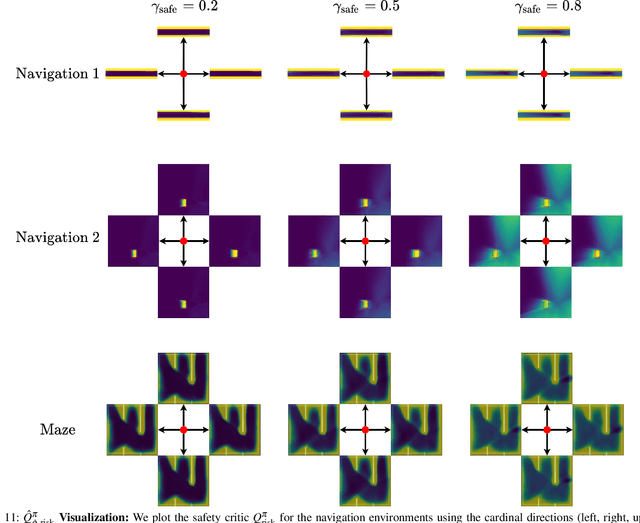
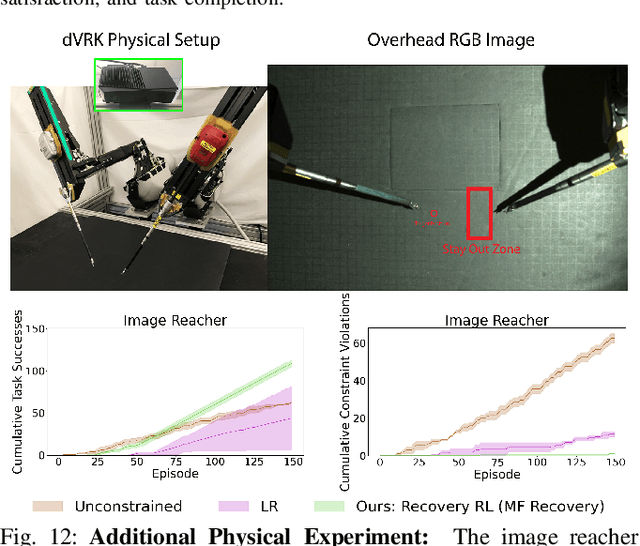
Safety remains a central obstacle preventing widespread use of RL in the real world: learning new tasks in uncertain environments requires extensive exploration, but safety requires limiting exploration. We propose Recovery RL, an algorithm which navigates this tradeoff by (1) leveraging offline data to learn about constraint violating zones before policy learning and (2) separating the goals of improving task performance and constraint satisfaction across two policies: a task policy that only optimizes the task reward and a recovery policy that guides the agent to safety when constraint violation is likely. We evaluate Recovery RL on 6 simulation domains, including two contact-rich manipulation tasks and an image-based navigation task, and an image-based obstacle avoidance task on a physical robot. We compare Recovery RL to 5 prior safe RL methods which jointly optimize for task performance and safety via constrained optimization or reward shaping and find that Recovery RL outperforms the next best prior method across all domains. Results suggest that Recovery RL trades off constraint violations and task successes 2 - 80 times more efficiently in simulation domains and 3 times more efficiently in physical experiments. See https://tinyurl.com/rl-recovery for videos and supplementary material.
IMPACT: Importance Weighted Asynchronous Architectures with Clipped Target Networks
Jan 23, 2020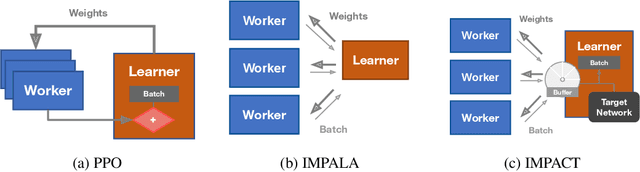
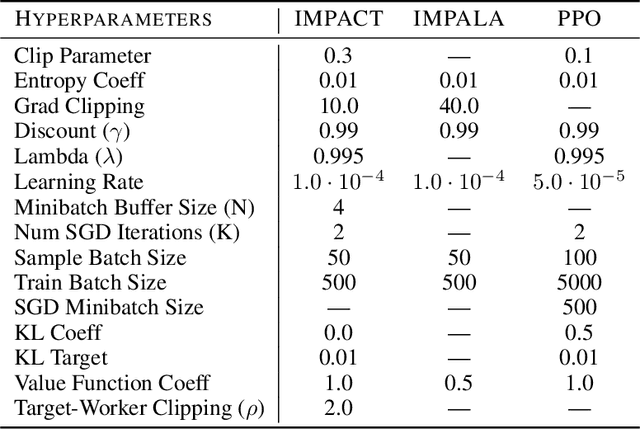
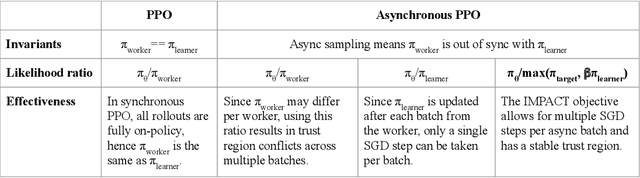
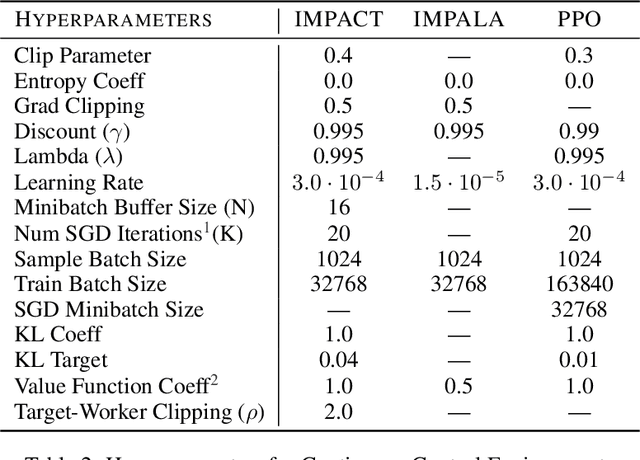
The practical usage of reinforcement learning agents is often bottlenecked by the duration of training time. To accelerate training, practitioners often turn to distributed reinforcement learning architectures to parallelize and accelerate the training process. However, modern methods for scalable reinforcement learning (RL) often tradeoff between the throughput of samples that an RL agent can learn from (sample throughput) and the quality of learning from each sample (sample efficiency). In these scalable RL architectures, as one increases sample throughput (i.e. increasing parallelization in IMPALA), sample efficiency drops significantly. To address this, we propose a new distributed reinforcement learning algorithm, IMPACT. IMPACT extends IMPALA with three changes: a target network for stabilizing the surrogate objective, a circular buffer, and truncated importance sampling. In discrete action-space environments, we show that IMPACT attains higher reward and, simultaneously, achieves up to 30% decrease in training wall-time than that of IMPALA. For continuous control environments, IMPACT trains faster than existing scalable agents while preserving the sample efficiency of synchronous PPO.