 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Scoping: Building Goal-Specific Abstractions for Planning in Complex Domains
Oct 17, 2020
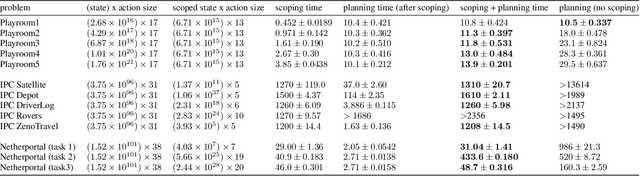
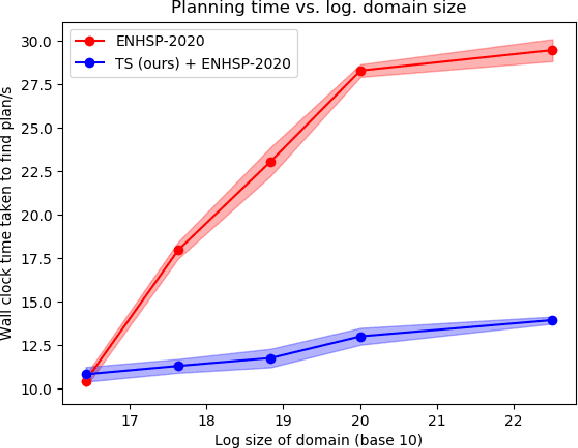
A generally intelligent agent requires an open-scope world model: one rich enough to tackle any of the wide range of tasks it may be asked to solve over its operational lifetime. Unfortunately, planning to solve any specific task using such a rich model is computationally intractable - even for state-of-the-art methods - due to the many states and actions that are necessarily present in the model but irrelevant to that problem. We propose task scoping: a method that exploits knowledge of the initial condition, goal condition, and transition-dynamics structure of a task to automatically and efficiently prune provably irrelevant factors and actions from a planning problem, which can dramatically decrease planning time. We prove that task scoping never deletes relevant factors or actions, characterize its computational complexity, and characterize the planning problems for which it is especially useful. Finally, we empirically evaluate task scoping on a variety of domains and demonstrate that using it as a pre-planning step can reduce the state-action space of various planning problems by orders of magnitude and speed up planning. When applied to a complex Minecraft domain, our approach speeds up a state-of-the-art planner by 30 times, including the time required for task scoping itself.
Teaching with IMPACT
Mar 14, 2019
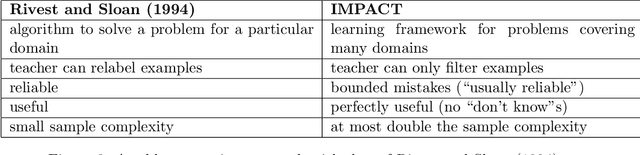
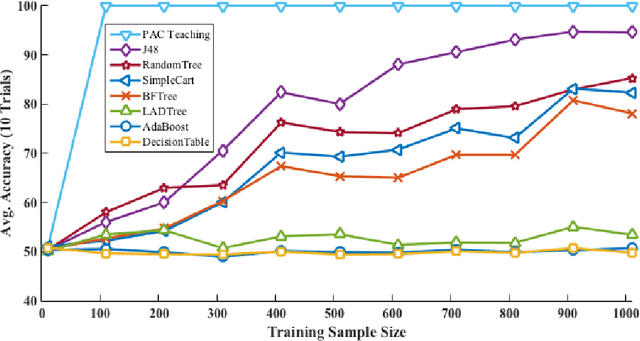
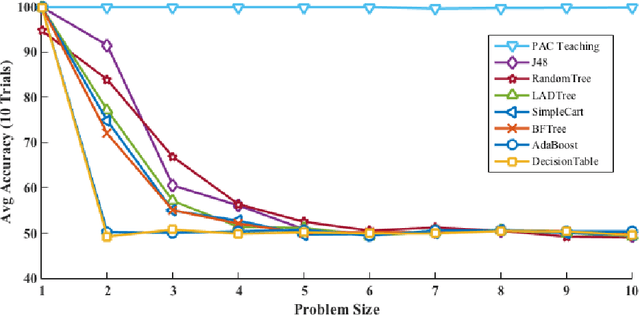
Like many problems in AI in their general form, supervised learning is computationally intractable. We hypothesize that an important reason humans can learn highly complex and varied concepts, in spite of the computational difficulty, is that they benefit tremendously from experienced and insightful teachers. This paper proposes a new learning framework that provides a role for a knowledgeable, benevolent teacher to guide the process of learning a target concept in a series of "curricular" phases or rounds. In each round, the teacher's role is to act as a moderator, exposing the learner to a subset of the available training data to move it closer to mastering the target concept. Via both theoretical and empirical evidence, we argue that this framework enables simple, efficient learners to acquire very complex concepts from examples. In particular, we provide multiple examples of concept classes that are known to be unlearnable in the standard PAC setting along with provably efficient algorithms for learning them in our extended setting. A key focus of our work is the ability to learn complex concepts on top of simpler, previously learned, concepts---a direction with the potential of creating more competent artificial agents.
ReNeg and Backseat Driver: Learning from Demonstration with Continuous Human Feedback
Jan 16, 2019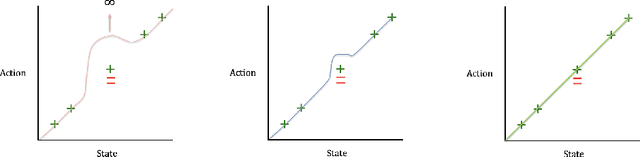
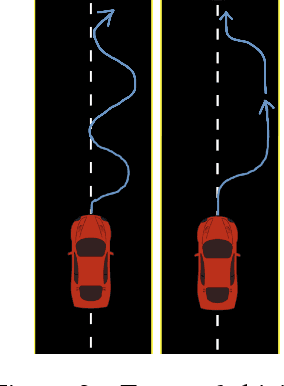
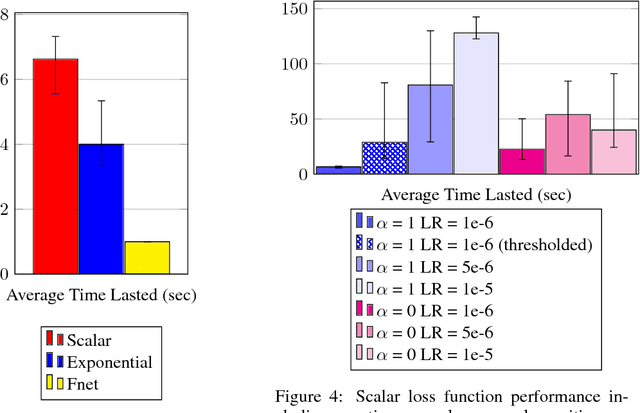
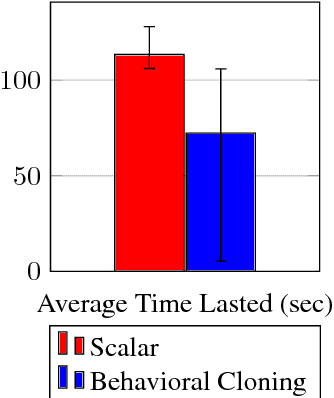
In autonomous vehicle (AV) control, allowing mistakes can be quite dangerous and costly in the real world. For this reason we investigate methods of training an AV without allowing the agent to explore and instead having a human explorer collect the data. Supervised learning has been explored for AV control, but it encounters the issue of the covariate shift. That is, training data collected from an optimal demonstration consists only of the states induced by the optimal control policy, but at runtime, the trained agent may encounter a vastly different state distribution with little relevant training data. To mitigate this issue, we have our human explorer make sub-optimal decisions. In order to have our agent not replicate these sub-optimal decisions, supervised learning requires that we either erase these actions, or replace these action with the correct action. Erasing is wasteful and replacing is difficult, since it is not easy to know the correct action without driving. We propose an alternate framework that includes continuous scalar feedback for each action, marking which actions we should replicate, which we should avoid, and how sure we are. Our framework learns continuous control from sub-optimal demonstration and evaluative feedback collected before training. We find that a human demonstrator can explore sub-optimal states in a safe manner, while still getting enough gradation to benefit learning. The collection method for data and feedback we call "Backseat Driver." We call the more general learning framework ReNeg, since it learns a regression from states to actions given negative as well as positive examples. We empirically validate several models in the ReNeg framework, testing on lane-following with limited data. We find that the best solution is a generalization of mean-squared error and outperforms supervised learning on the positive examples alone.
Measuring and Characterizing Generalization in Deep Reinforcement Learning
Dec 11, 2018
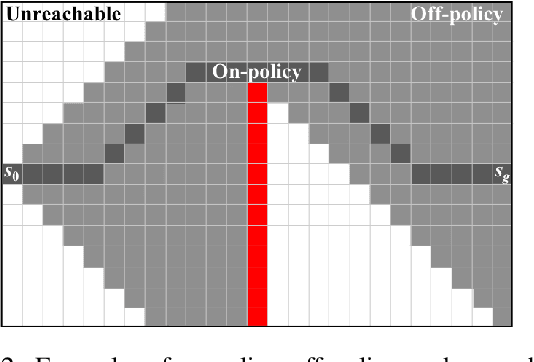
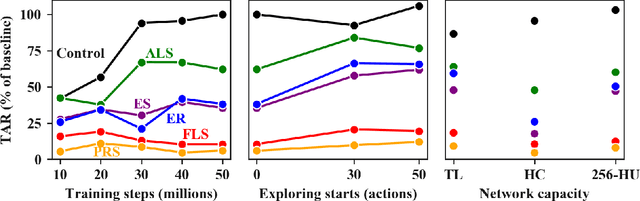
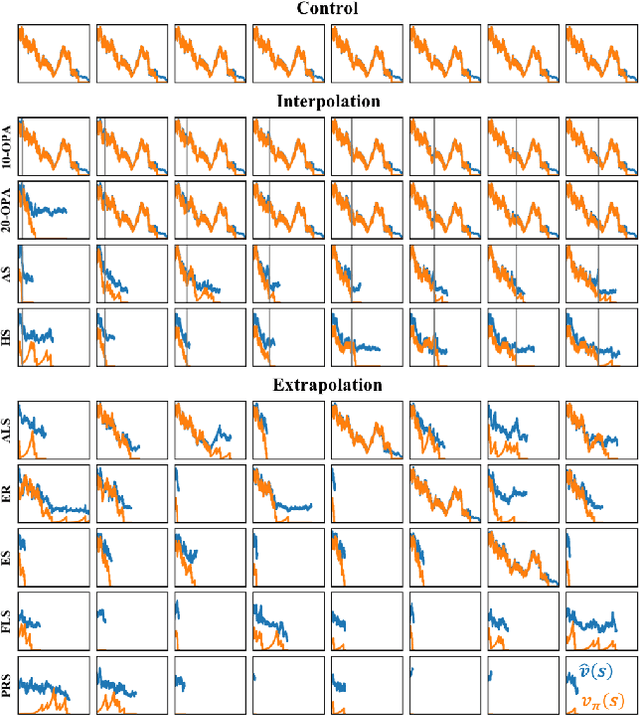
Deep reinforcement-learning methods have achieved remarkable performance on challenging control tasks. Observations of the resulting behavior give the impression that the agent has constructed a generalized representation that supports insightful action decisions. We re-examine what is meant by generalization in RL, and propose several definitions based on an agent's performance in on-policy, off-policy, and unreachable states. We propose a set of practical methods for evaluating agents with these definitions of generalization. We demonstrate these techniques on a common benchmark task for deep RL, and we show that the learned networks make poor decisions for states that differ only slightly from on-policy states, even though those states are not selected adversarially. Taken together, these results call into question the extent to which deep Q-networks learn generalized representations, and suggest that more experimentation and analysis is necessary before claims of representation learning can be supported.
Finding Options that Minimize Planning Time
Oct 16, 2018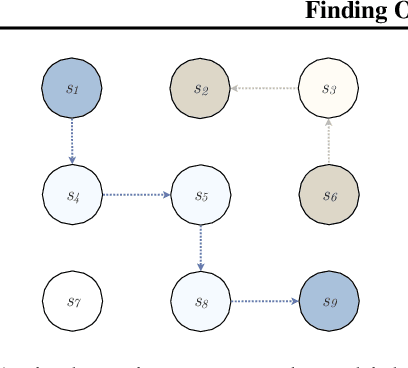
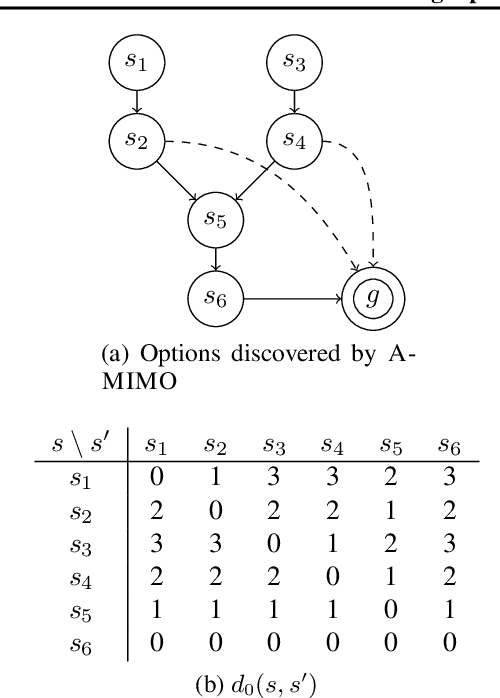
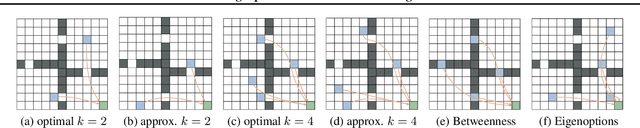
While adding temporally abstract actions, or options, to an agent's action repertoire can often accelerate learning and planning, existing approaches for determining which specific options to add are largely heuristic. We aim to formalize the problem of selecting the optimal set of options for planning, in two contexts: 1) finding the set of $k$ options that minimize the number of value-iteration passes until convergence, and 2) computing the smallest set of options so that planning converges in less than a given maximum of $\ell$ value-iteration passes. We first show that both problems are NP-hard. We then provide a polynomial-time approximation algorithm for computing the optimal options for tasks with bounded return and goal states. We prove that the algorithm has bounded suboptimality for deterministic tasks. Finally, we empirically evaluate its performance against both the optimal options and a representative collection of heuristic approaches in simple grid-based domains including the classic four rooms problem.
Personalized Education at Scale
Sep 24, 2018Tailoring the presentation of information to the needs of individual students leads to massive gains in student outcomes~\cite{bloom19842}. This finding is likely due to the fact that different students learn differently, perhaps as a result of variation in ability, interest or other factors~\cite{schiefele1992interest}. Adapting presentations to the educational needs of an individual has traditionally been the domain of experts, making it expensive and logistically challenging to do at scale, and also leading to inequity in educational outcomes. Increased course sizes and large MOOC enrollments provide an unprecedented access to student data. We propose that emerging technologies in reinforcement learning (RL), as well as semi-supervised learning, natural language processing, and computer vision are critical to leveraging this data to provide personalized education at scale.