 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReNeg and Backseat Driver: Learning from Demonstration with Continuous Human Feedback
Paper and Code
Jan 16, 2019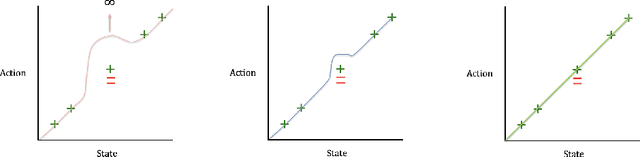
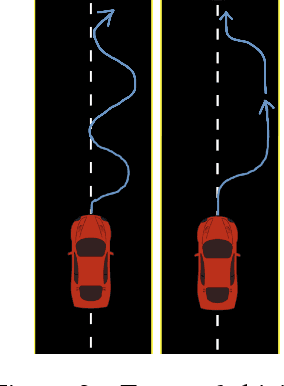
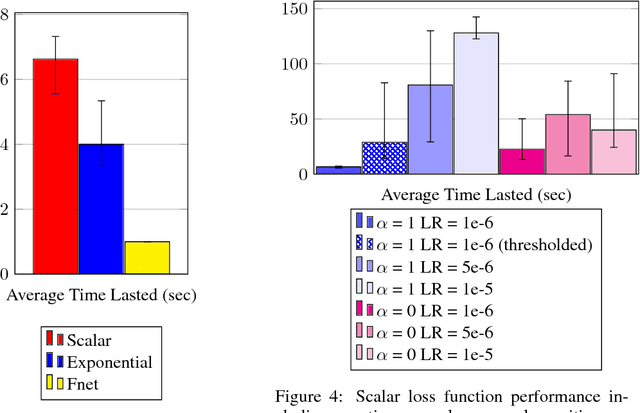
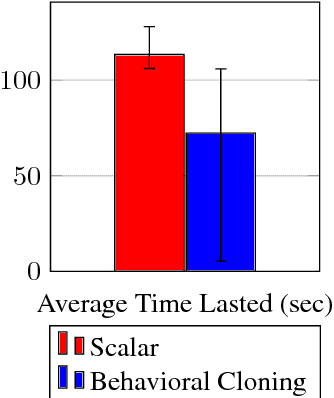
In autonomous vehicle (AV) control, allowing mistakes can be quite dangerous and costly in the real world. For this reason we investigate methods of training an AV without allowing the agent to explore and instead having a human explorer collect the data. Supervised learning has been explored for AV control, but it encounters the issue of the covariate shift. That is, training data collected from an optimal demonstration consists only of the states induced by the optimal control policy, but at runtime, the trained agent may encounter a vastly different state distribution with little relevant training data. To mitigate this issue, we have our human explorer make sub-optimal decisions. In order to have our agent not replicate these sub-optimal decisions, supervised learning requires that we either erase these actions, or replace these action with the correct action. Erasing is wasteful and replacing is difficult, since it is not easy to know the correct action without driving. We propose an alternate framework that includes continuous scalar feedback for each action, marking which actions we should replicate, which we should avoid, and how sure we are. Our framework learns continuous control from sub-optimal demonstration and evaluative feedback collected before training. We find that a human demonstrator can explore sub-optimal states in a safe manner, while still getting enough gradation to benefit learning. The collection method for data and feedback we call "Backseat Driver." We call the more general learning framework ReNeg, since it learns a regression from states to actions given negative as well as positive examples. We empirically validate several models in the ReNeg framework, testing on lane-following with limited data. We find that the best solution is a generalization of mean-squared error and outperforms supervised learning on the positive examples alone.