 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Simple Approach to Multi-step Model-based Reinforcement Learning
Oct 31, 2018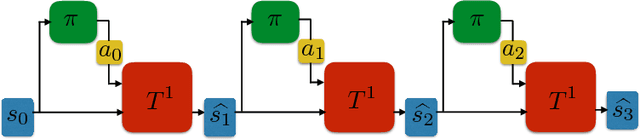
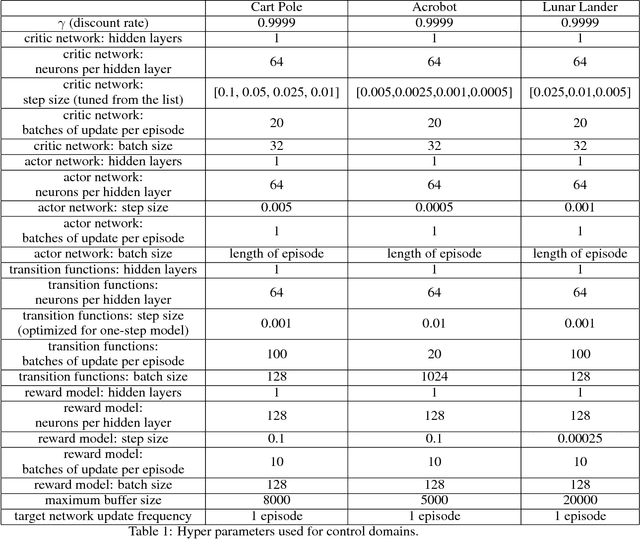
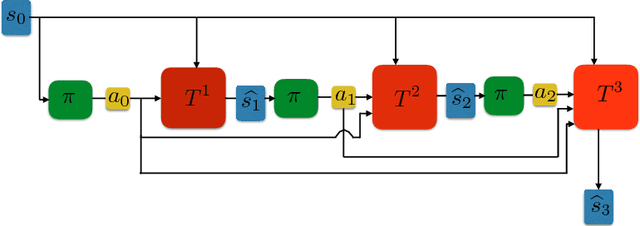
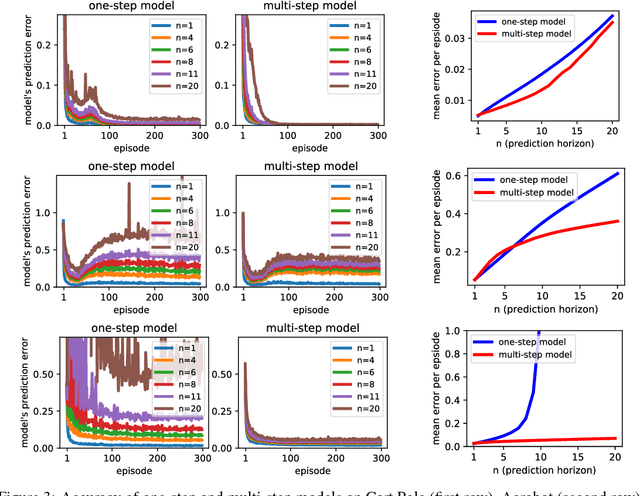
When environmental interaction is expensive, model-based reinforcement learning offers a solution by planning ahead and avoiding costly mistakes. Model-based agents typically learn a single-step transition model. In this paper, we propose a multi-step model that predicts the outcome of an action sequence with variable length. We show that this model is easy to learn, and that the model can make policy-conditional predictions. We report preliminary results that show a clear advantage for the multi-step model compared to its one-step counterpart.
Personalized Education at Scale
Sep 24, 2018Tailoring the presentation of information to the needs of individual students leads to massive gains in student outcomes~\cite{bloom19842}. This finding is likely due to the fact that different students learn differently, perhaps as a result of variation in ability, interest or other factors~\cite{schiefele1992interest}. Adapting presentations to the educational needs of an individual has traditionally been the domain of experts, making it expensive and logistically challenging to do at scale, and also leading to inequity in educational outcomes. Increased course sizes and large MOOC enrollments provide an unprecedented access to student data. We propose that emerging technologies in reinforcement learning (RL), as well as semi-supervised learning, natural language processing, and computer vision are critical to leveraging this data to provide personalized education at scale.
Equivalence Between Wasserstein and Value-Aware Loss for Model-based Reinforcement Learning
Jul 08, 2018Learning a generative model is a key component of model-based reinforcement learning. Though learning a good model in the tabular setting is a simple task, learning a useful model in the approximate setting is challenging. In this context, an important question is the loss function used for model learning as varying the loss function can have a remarkable impact on effectiveness of planning. Recently Farahmand et al. (2017) proposed a value-aware model learning (VAML) objective that captures the structure of value function during model learning. Using tools from Asadi et al. (2018), we show that minimizing the VAML objective is in fact equivalent to minimizing the Wasserstein metric. This equivalence improves our understanding of value-aware models, and also creates a theoretical foundation for applications of Wasserstein in model-based reinforcement~learning.