 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStackelberg Punishment and Bully-Proofing Autonomous Vehicles
Aug 23, 2019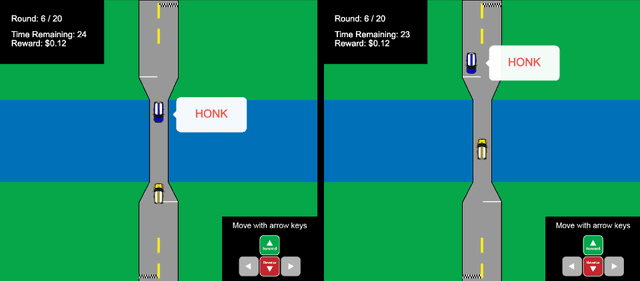
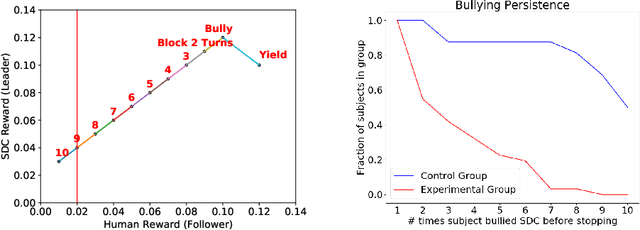
Mutually beneficial behavior in repeated games can be enforced via the threat of punishment, as enshrined in game theory's well-known "folk theorem." There is a cost, however, to a player for generating these disincentives. In this work, we seek to minimize this cost by computing a "Stackelberg punishment," in which the player selects a behavior that sufficiently punishes the other player while maximizing its own score under the assumption that the other player will adopt a best response. This idea generalizes the concept of a Stackelberg equilibrium. Known efficient algorithms for computing a Stackelberg equilibrium can be adapted to efficiently produce a Stackelberg punishment. We demonstrate an application of this idea in an experiment involving a virtual autonomous vehicle and human participants. We find that a self-driving car with a Stackelberg punishment policy discourages human drivers from bullying in a driving scenario requiring social negotiation.
Interactive Learning of Environment Dynamics for Sequential Tasks
Jul 19, 2019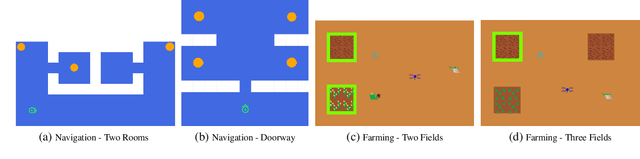
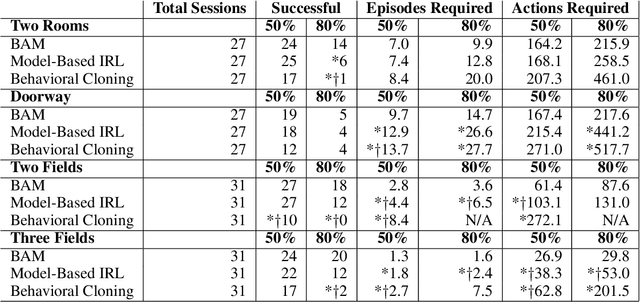
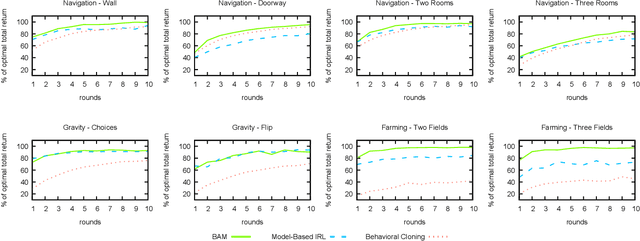
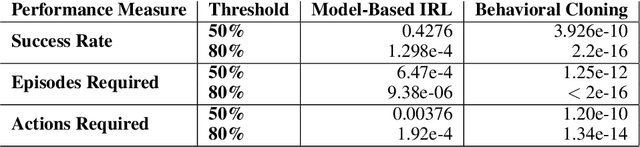
In order for robots and other artificial agents to efficiently learn to perform useful tasks defined by an end user, they must understand not only the goals of those tasks, but also the structure and dynamics of that user's environment. While existing work has looked at how the goals of a task can be inferred from a human teacher, the agent is often left to learn about the environment on its own. To address this limitation, we develop an algorithm, Behavior Aware Modeling (BAM), which incorporates a teacher's knowledge into a model of the transition dynamics of an agent's environment. We evaluate BAM both in simulation and with real human teachers, learning from a combination of task demonstrations and evaluative feedback, and show that it can outperform approaches which do not explicitly consider this source of dynamics knowledge.
Deep Reinforcement Learning from Policy-Dependent Human Feedback
Feb 12, 2019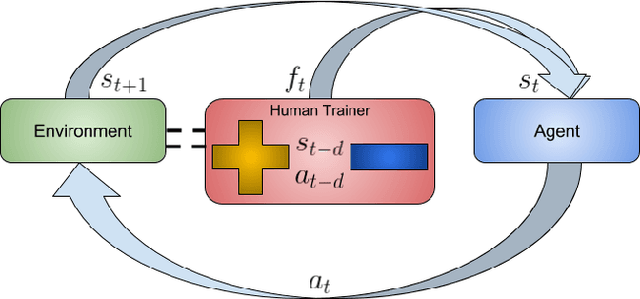
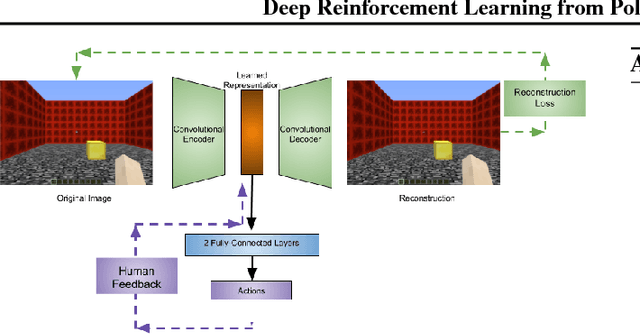

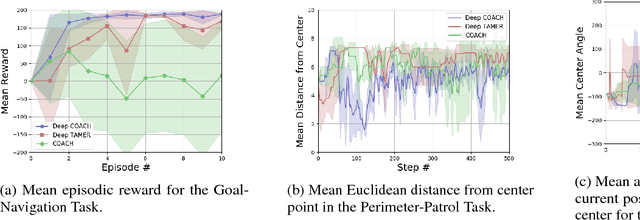
To widen their accessibility and increase their utility, intelligent agents must be able to learn complex behaviors as specified by (non-expert) human users. Moreover, they will need to learn these behaviors within a reasonable amount of time while efficiently leveraging the sparse feedback a human trainer is capable of providing. Recent work has shown that human feedback can be characterized as a critique of an agent's current behavior rather than as an alternative reward signal to be maximized, culminating in the COnvergent Actor-Critic by Humans (COACH) algorithm for making direct policy updates based on human feedback. Our work builds on COACH, moving to a setting where the agent's policy is represented by a deep neural network. We employ a series of modifications on top of the original COACH algorithm that are critical for successfully learning behaviors from high-dimensional observations, while also satisfying the constraint of obtaining reduced sample complexity. We demonstrate the effectiveness of our Deep COACH algorithm in the rich 3D world of Minecraft with an agent that learns to complete tasks by mapping from raw pixels to actions using only real-time human feedback in 10-15 minutes of interaction.
Successor Features Support Model-based and Model-free Reinforcement Learning
Jan 31, 2019
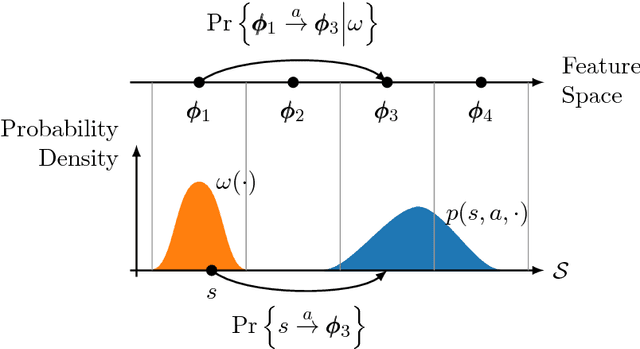
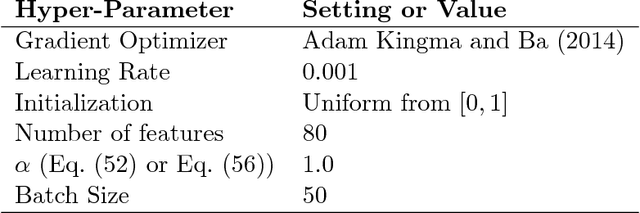
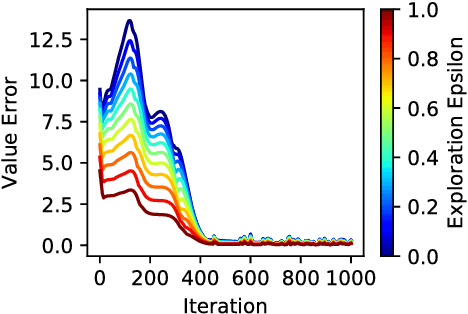
One key challenge in reinforcement learning is the ability to generalize knowledge in control problems. While deep learning methods have been successfully combined with model-free reinforcement-learning algorithms, how to perform model-based reinforcement learning in the presence of approximation errors still remains an open problem. Using successor features, a feature representation that predicts a temporal constraint, this paper presents three contributions: First, it shows how learning successor features is equivalent to model-free learning. Then, it shows how successor features encode model reductions that compress the state space by creating state partitions of bisimilar states. Using this representation, an intelligent agent is guaranteed to accurately predict future reward outcomes, a key property of model-based reinforcement-learning algorithms. Lastly, it presents a loss objective and prediction error bounds showing that accurately predicting value functions and reward sequences is possible with an approximation of successor features. On finite control problems, we illustrate how minimizing this loss objective results in approximate bisimulations. The results presented in this paper provide a novel understanding of representations that can support model-free and model-based reinforcement learning.
Theory of Minds: Understanding Behavior in Groups Through Inverse Planning
Jan 18, 2019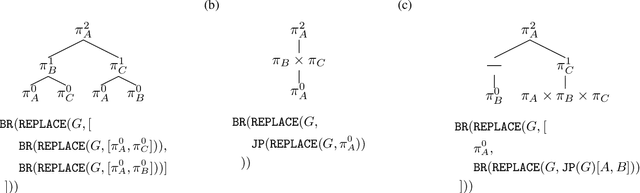
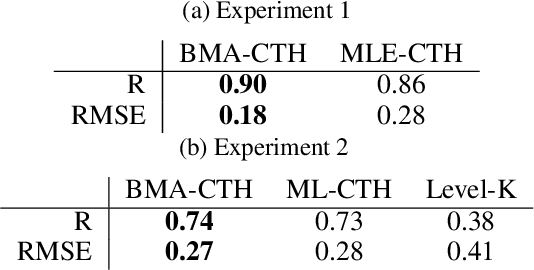
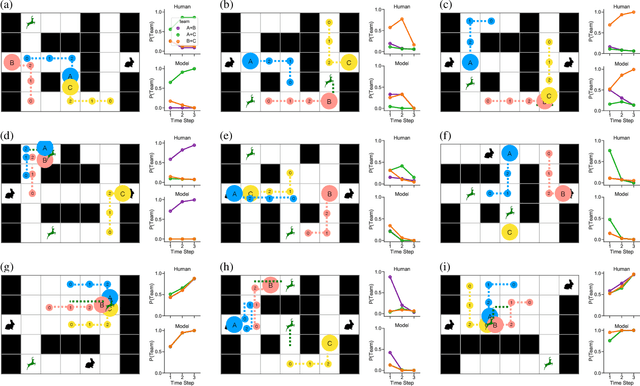
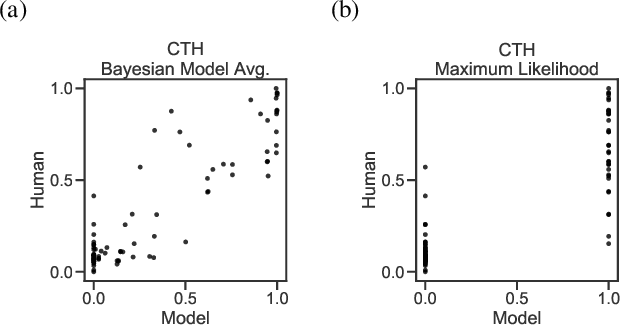
Human social behavior is structured by relationships. We form teams, groups, tribes, and alliances at all scales of human life. These structures guide multi-agent cooperation and competition, but when we observe others these underlying relationships are typically unobservable and hence must be inferred. Humans make these inferences intuitively and flexibly, often making rapid generalizations about the latent relationships that underlie behavior from just sparse and noisy observations. Rapid and accurate inferences are important for determining who to cooperate with, who to compete with, and how to cooperate in order to compete. Towards the goal of building machine-learning algorithms with human-like social intelligence, we develop a generative model of multi-agent action understanding based on a novel representation for these latent relationships called Composable Team Hierarchies (CTH). This representation is grounded in the formalism of stochastic games and multi-agent reinforcement learning. We use CTH as a target for Bayesian inference yielding a new algorithm for understanding behavior in groups that can both infer hidden relationships as well as predict future actions for multiple agents interacting together. Our algorithm rapidly recovers an underlying causal model of how agents relate in spatial stochastic games from just a few observations. The patterns of inference made by this algorithm closely correspond with human judgments and the algorithm makes the same rapid generalizations that people do.
Mitigating Planner Overfitting in Model-Based Reinforcement Learning
Dec 03, 2018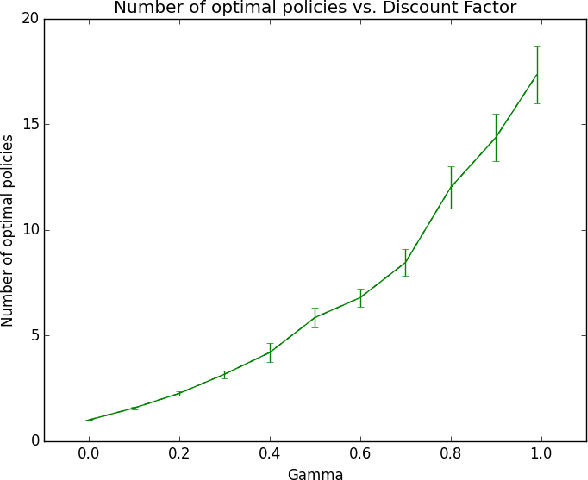
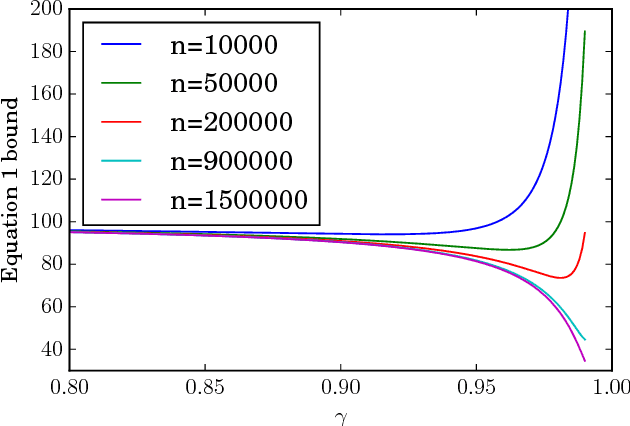
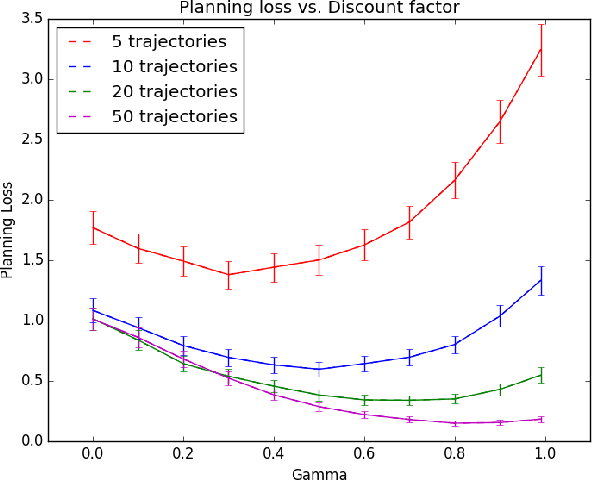
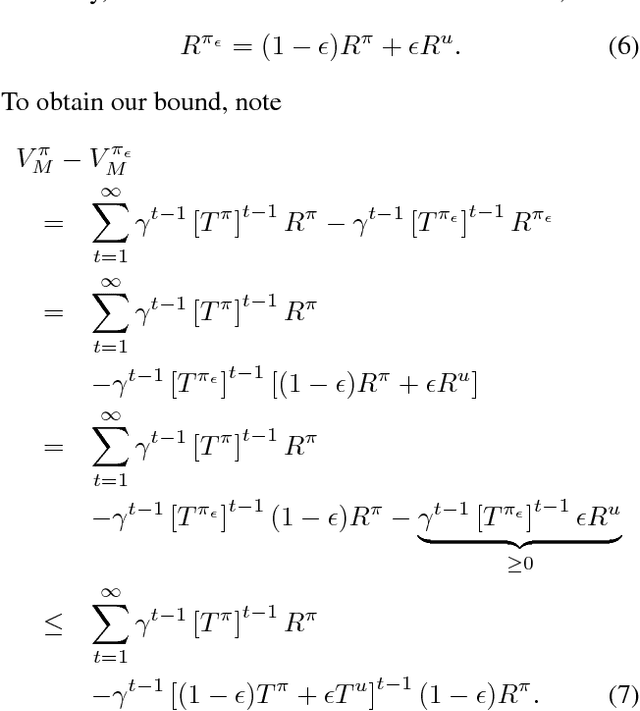
An agent with an inaccurate model of its environment faces a difficult choice: it can ignore the errors in its model and act in the real world in whatever way it determines is optimal with respect to its model. Alternatively, it can take a more conservative stance and eschew its model in favor of optimizing its behavior solely via real-world interaction. This latter approach can be exceedingly slow to learn from experience, while the former can lead to "planner overfitting" - aspects of the agent's behavior are optimized to exploit errors in its model. This paper explores an intermediate position in which the planner seeks to avoid overfitting through a kind of regularization of the plans it considers. We present three different approaches that demonstrably mitigate planner overfitting in reinforcement-learning environments.
Towards a Simple Approach to Multi-step Model-based Reinforcement Learning
Oct 31, 2018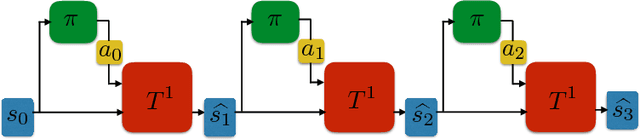
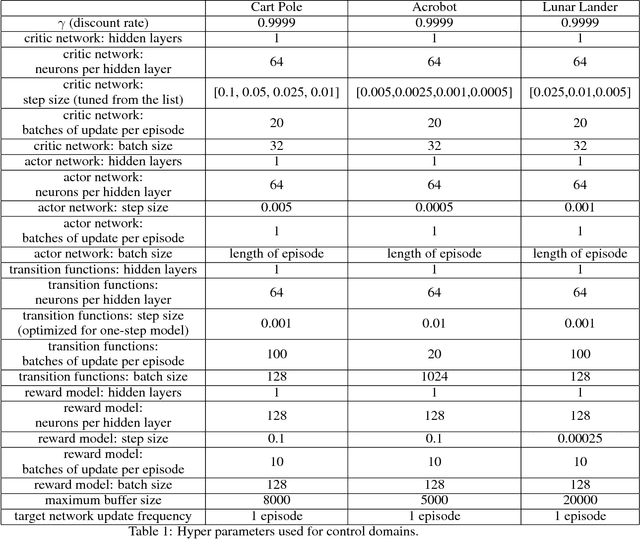
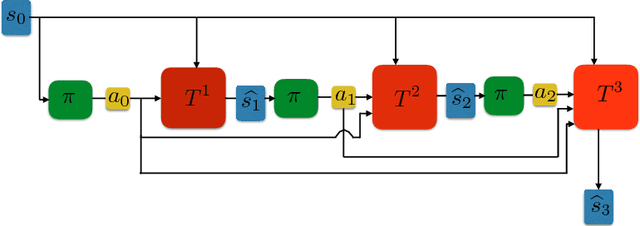
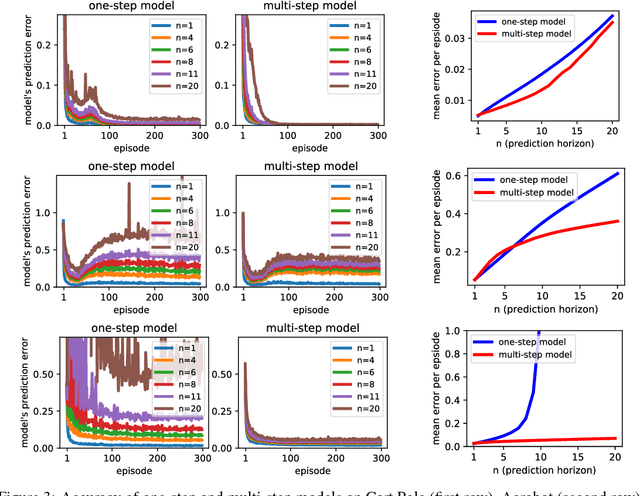
When environmental interaction is expensive, model-based reinforcement learning offers a solution by planning ahead and avoiding costly mistakes. Model-based agents typically learn a single-step transition model. In this paper, we propose a multi-step model that predicts the outcome of an action sequence with variable length. We show that this model is easy to learn, and that the model can make policy-conditional predictions. We report preliminary results that show a clear advantage for the multi-step model compared to its one-step counterpart.
Lipschitz Continuity in Model-based Reinforcement Learning
Jul 27, 2018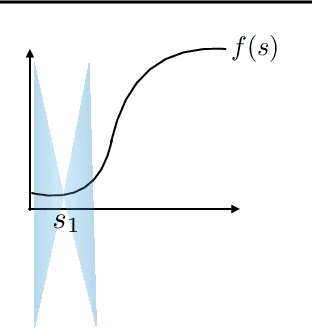

We examine the impact of learning Lipschitz continuous models in the context of model-based reinforcement learning. We provide a novel bound on multi-step prediction error of Lipschitz models where we quantify the error using the Wasserstein metric. We go on to prove an error bound for the value-function estimate arising from Lipschitz models and show that the estimated value function is itself Lipschitz. We conclude with empirical results that show the benefits of controlling the Lipschitz constant of neural-network models.
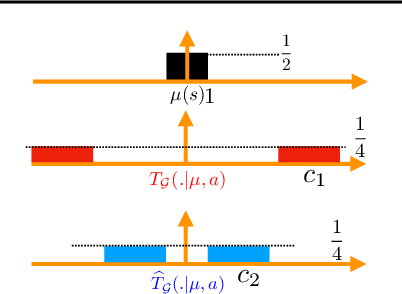
Equivalence Between Wasserstein and Value-Aware Loss for Model-based Reinforcement Learning
Jul 08, 2018Learning a generative model is a key component of model-based reinforcement learning. Though learning a good model in the tabular setting is a simple task, learning a useful model in the approximate setting is challenging. In this context, an important question is the loss function used for model learning as varying the loss function can have a remarkable impact on effectiveness of planning. Recently Farahmand et al. (2017) proposed a value-aware model learning (VAML) objective that captures the structure of value function during model learning. Using tools from Asadi et al. (2018), we show that minimizing the VAML objective is in fact equivalent to minimizing the Wasserstein metric. This equivalence improves our understanding of value-aware models, and also creates a theoretical foundation for applications of Wasserstein in model-based reinforcement~learning.
Transfer with Model Features in Reinforcement Learning
Jul 04, 2018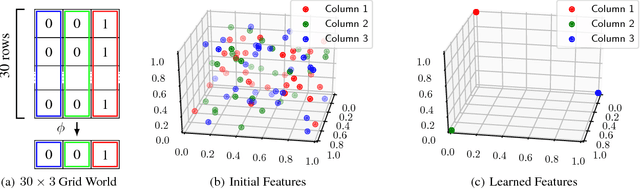
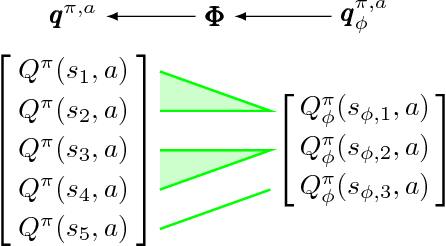
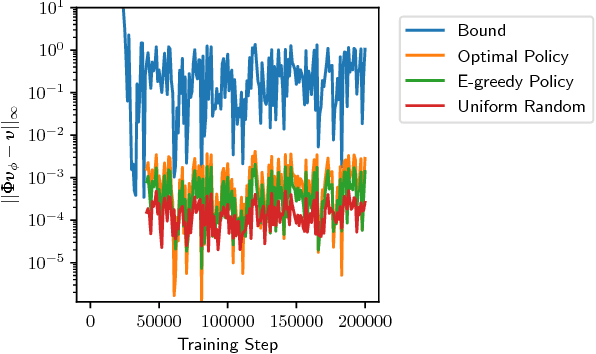
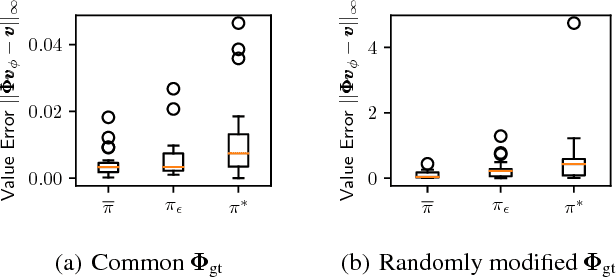
A key question in Reinforcement Learning is which representation an agent can learn to efficiently reuse knowledge between different tasks. Recently the Successor Representation was shown to have empirical benefits for transferring knowledge between tasks with shared transition dynamics. This paper presents Model Features: a feature representation that clusters behaviourally equivalent states and that is equivalent to a Model-Reduction. Further, we present a Successor Feature model which shows that learning Successor Features is equivalent to learning a Model-Reduction. A novel optimization objective is developed and we provide bounds showing that minimizing this objective results in an increasingly improved approximation of a Model-Reduction. Further, we provide transfer experiments on randomly generated MDPs which vary in their transition and reward functions but approximately preserve behavioural equivalence between states. These results demonstrate that Model Features are suitable for transfer between tasks with varying transition and reward functions.