 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Self-Constructing Graph Convolutional Networks with Adaptive Class Weighting Loss for Semantic Segmentation
Apr 21, 2020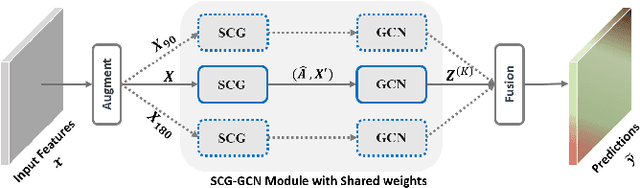
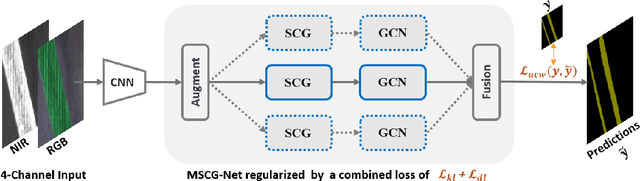


We propose a novel architecture called the Multi-view Self-Constructing Graph Convolutional Networks (MSCG-Net) for semantic segmentation. Building on the recently proposed Self-Constructing Graph (SCG) module, which makes use of learnable latent variables to self-construct the underlying graphs directly from the input features without relying on manually built prior knowledge graphs, we leverage multiple views in order to explicitly exploit the rotational invariance in airborne images. We further develop an adaptive class weighting loss to address the class imbalance. We demonstrate the effectiveness and flexibility of the proposed method on the Agriculture-Vision challenge dataset and our model achieves very competitive results (0.547 mIoU) with much fewer parameters and at a lower computational cost compared to related pure-CNN based work. Code will be available at: github.com/samleoqh/MSCG-Net
Code-Aligned Autoencoders for Unsupervised Change Detection in Multimodal Remote Sensing Images
Apr 15, 2020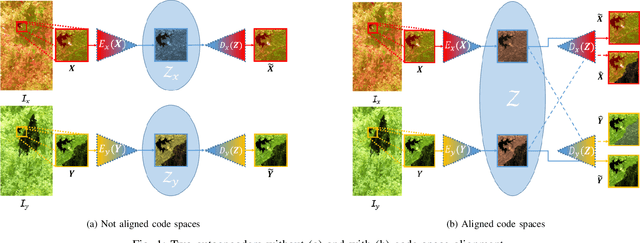

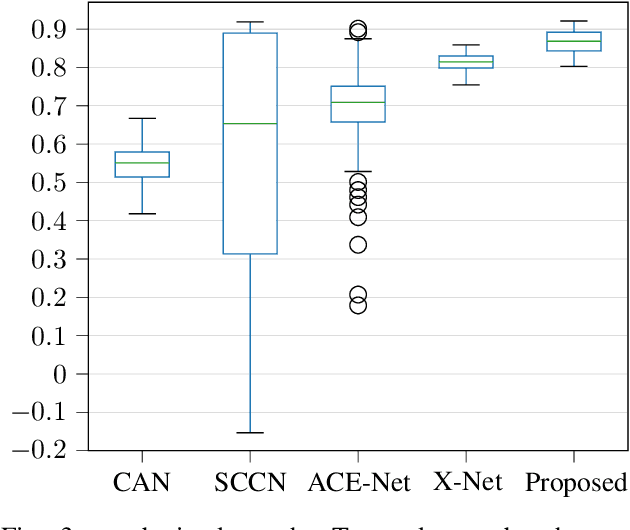
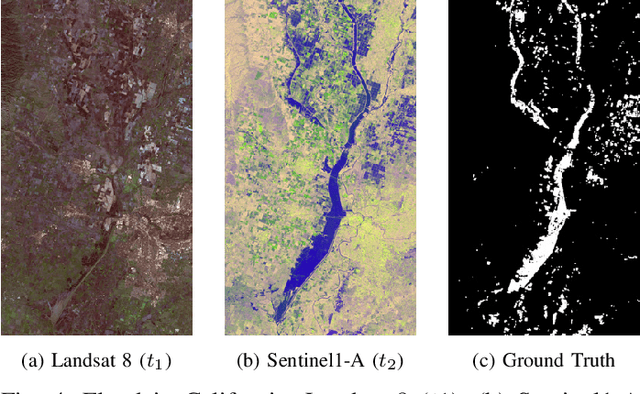
Image translation with convolutional autoencoders has recently been used as an approach to multimodal change detection in bitemporal satellite images. A main challenge is the alignment of the code spaces by reducing the contribution of change pixels to the learning of the translation function. Many existing approaches train the networks by exploiting supervised information of the change areas, which, however, is not always available. We propose to extract relational pixel information captured by domain-specific affinity matrices at the input and use this to enforce alignment of the code spaces and reduce the impact of change pixels on the learning objective. A change prior is derived in an unsupervised fashion from pixel pair affinities that are comparable across domains. To achieve code space alignment we enforce that pixel with similar affinity relations in the input domains should be correlated also in code space. We demonstrate the utility of this procedure in combination with cycle consistency. The proposed approach are compared with state-of-the-art deep learning algorithms. Experiments conducted on four real datasets show the effectiveness of our methodology.
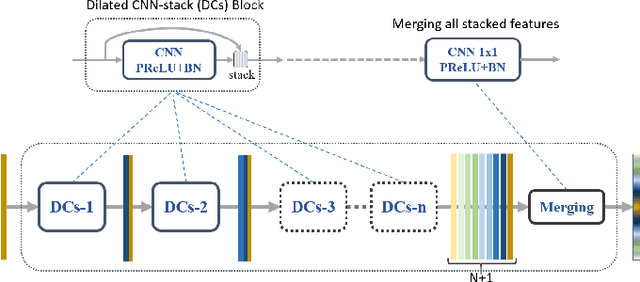
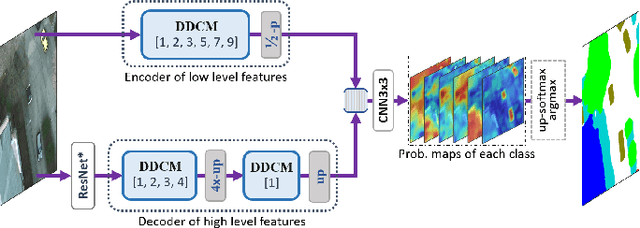
Dense Dilated Convolutions Merging Network for Land Cover Classification
Mar 09, 2020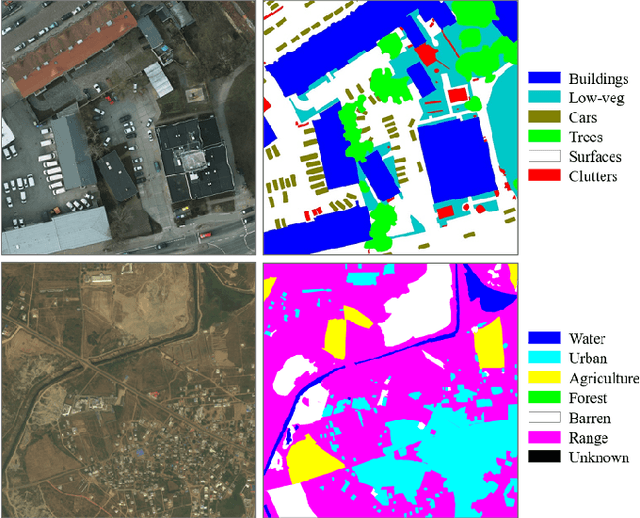
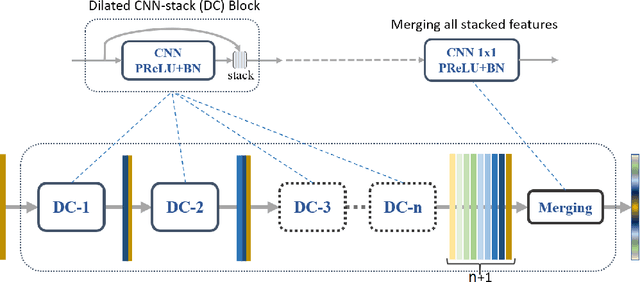
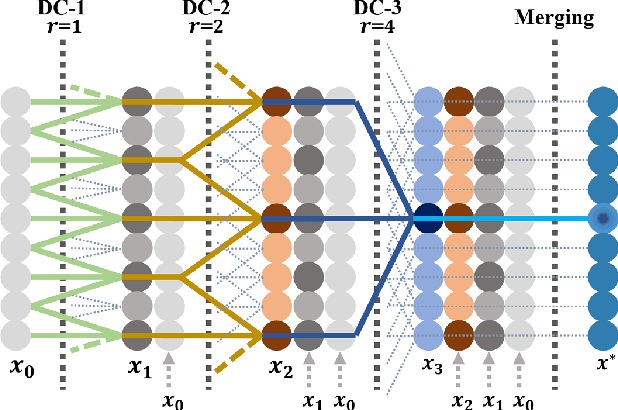
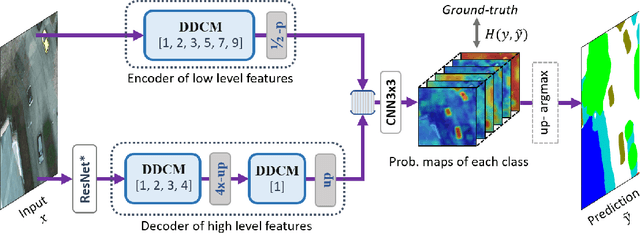
Land cover classification of remote sensing images is a challenging task due to limited amounts of annotated data, highly imbalanced classes, frequent incorrect pixel-level annotations, and an inherent complexity in the semantic segmentation task. In this article, we propose a novel architecture called the dense dilated convolutions' merging network (DDCM-Net) to address this task. The proposed DDCM-Net consists of dense dilated image convolutions merged with varying dilation rates. This effectively utilizes rich combinations of dilated convolutions that enlarge the network's receptive fields with fewer parameters and features compared with the state-of-the-art approaches in the remote sensing domain. Importantly, DDCM-Net obtains fused local- and global-context information, in effect incorporating surrounding discriminative capability for multiscale and complex-shaped objects with similar color and textures in very high-resolution aerial imagery. We demonstrate the effectiveness, robustness, and flexibility of the proposed DDCM-Net on the publicly available ISPRS Potsdam and Vaihingen data sets, as well as the DeepGlobe land cover data set. Our single model, trained on three-band Potsdam and Vaihingen data sets, achieves better accuracy in terms of both mean intersection over union (mIoU) and F1-score compared with other published models trained with more than three-band data. We further validate our model on the DeepGlobe data set, achieving state-of-the-art result 56.2% mIoU with much fewer parameters and at a lower computational cost compared with related recent work. Code available at https://github.com/samleoqh/DDCM-Semantic-Segmentation-PyTorch
Deep Image Translation with an Affinity-Based Change Prior for Unsupervised Multimodal Change Detection
Jan 13, 2020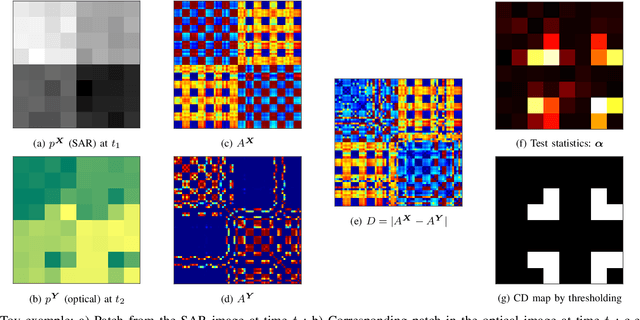
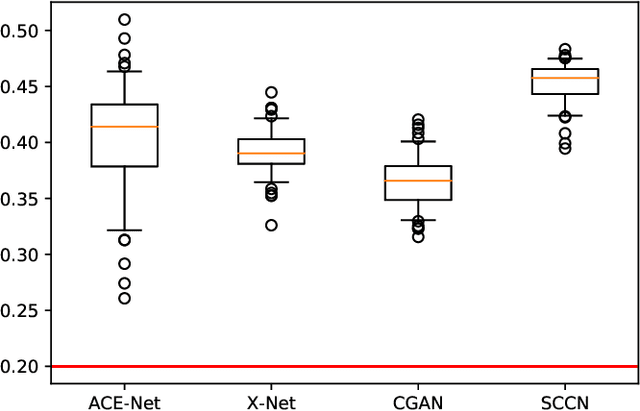
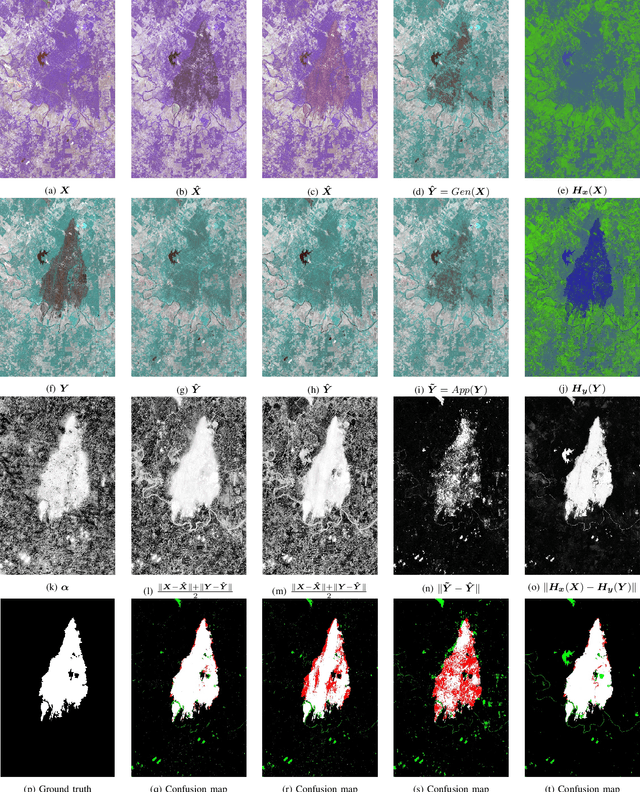
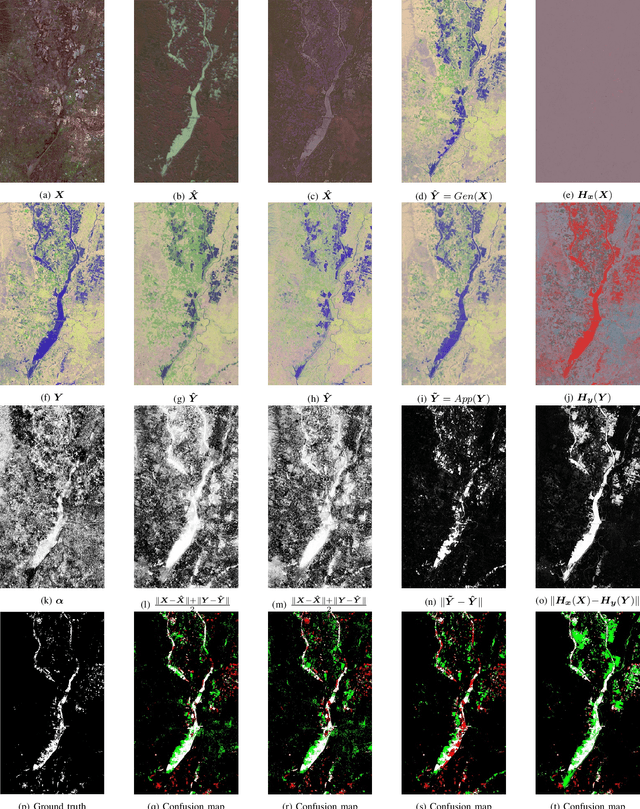
Image translation with convolutional neural networks has recently been used as an approach to multimodal change detection. Existing approaches train the networks by exploiting supervised information of the change areas, which, however, is not always available. A main challenge in the unsupervised problem setting is to avoid that change pixels affect the learning of the translation function. We propose two new network architectures trained with loss functions weighted by priors that reduce the impact of change pixels on the learning objective. The change prior is derived in an unsupervised fashion from relational pixel information captured by domain-specific affinity matrices. Specifically, we use the vertex degrees associated with an absolute affinity difference matrix and demonstrate their utility in combination with cycle consistency and adversarial training. The proposed neural networks are compared with state-of-the-art algorithms. Experiments conducted on two real datasets show the effectiveness of our methodology.
Information Plane Analysis of Deep Neural Networks via Matrix-Based Renyi's Entropy and Tensor Kernels
Sep 25, 2019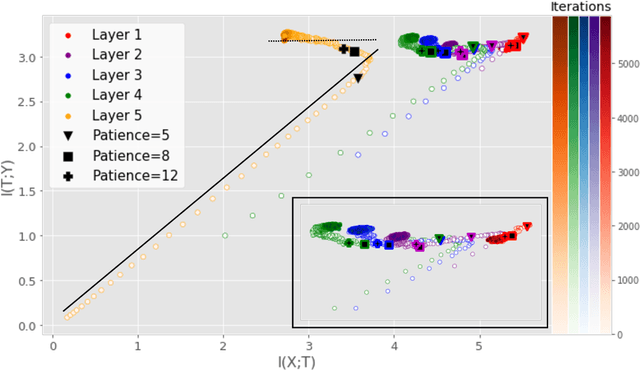
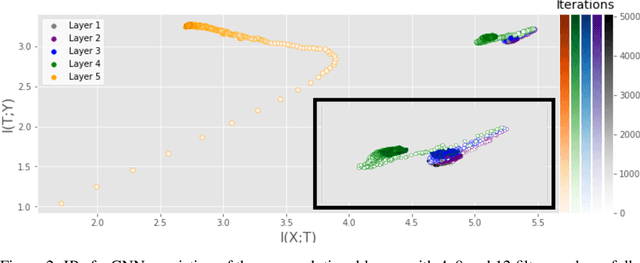
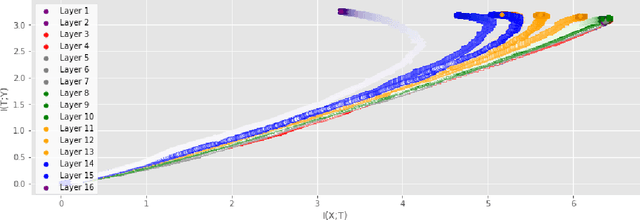
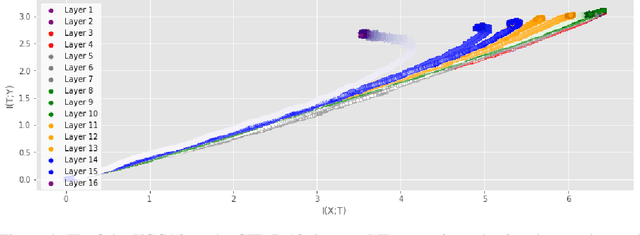
Analyzing deep neural networks (DNNs) via information plane (IP) theory has gained tremendous attention recently as a tool to gain insight into, among others, their generalization ability. However, it is by no means obvious how to estimate mutual information (MI) between each hidden layer and the input/desired output, to construct the IP. For instance, hidden layers with many neurons require MI estimators with robustness towards the high dimensionality associated with such layers. MI estimators should also be able to naturally handle convolutional layers, while at the same time being computationally tractable to scale to large networks. None of the existing IP methods to date have been able to study truly deep Convolutional Neural Networks (CNNs), such as the e.g.\ VGG-16. In this paper, we propose an IP analysis using the new matrix--based R\'enyi's entropy coupled with tensor kernels over convolutional layers, leveraging the power of kernel methods to represent properties of the probability distribution independently of the dimensionality of the data. The obtained results shed new light on the previous literature concerning small-scale DNNs, however using a completely new approach. Importantly, the new framework enables us to provide the first comprehensive IP analysis of contemporary large-scale DNNs and CNNs, investigating the different training phases and providing new insights into the training dynamics of large-scale neural networks.
Road Mapping In LiDAR Images Using A Joint-Task Dense Dilated Convolutions Merging Network
Sep 07, 2019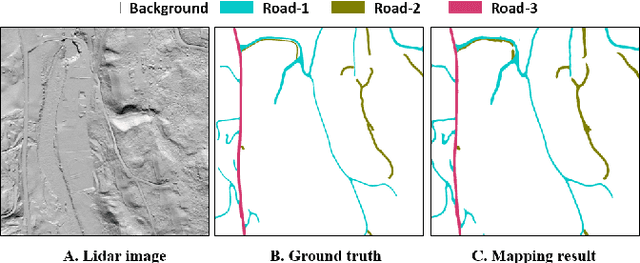
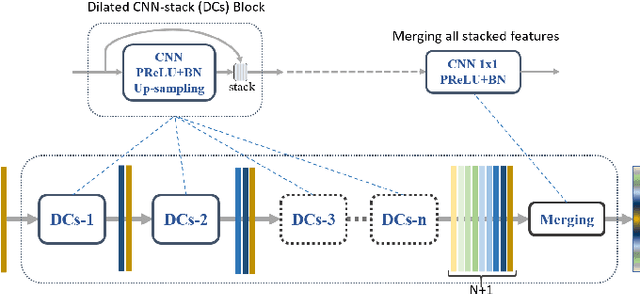
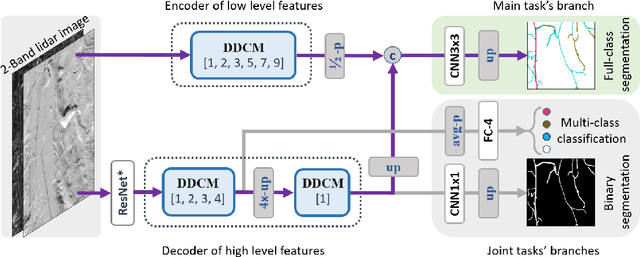
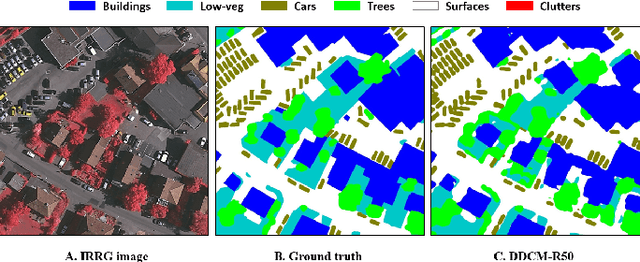
It is important, but challenging, for the forest industry to accurately map roads which are used for timber transport by trucks. In this work, we propose a Dense Dilated Convolutions Merging Network (DDCM-Net) to detect these roads in lidar images. The DDCM-Net can effectively recognize multi-scale and complex shaped roads with similar texture and colors, and also is shown to have superior performance over existing methods. To further improve its ability to accurately infer categories of roads, we propose the use of a joint-task learning strategy that utilizes two auxiliary output branches, i.e, multi-class classification and binary segmentation, joined with the main output of full-class segmentation. This pushes the network towards learning more robust representations that are expected to boost the ultimate performance of the main task. In addition, we introduce an iterative-random-weighting method to automatically weigh the joint losses for auxiliary tasks. This can avoid the difficult and expensive process of tuning the weights of each task's loss by hand. The experiments demonstrate that our proposed joint-task DDCM-Net can achieve better performance with fewer parameters and higher computational efficiency than previous state-of-the-art approaches.
Dense Dilated Convolutions Merging Network for Semantic Mapping of Remote Sensing Images
Aug 30, 2019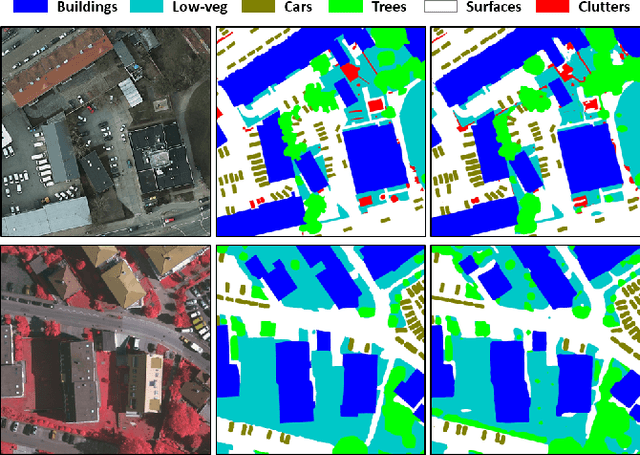

We propose a network for semantic mapping called the Dense Dilated Convolutions Merging Network (DDCM-Net) to provide a deep learning approach that can recognize multi-scale and complex shaped objects with similar color and textures, such as buildings, surfaces/roads, and trees in very high resolution remote sensing images. The proposed DDCM-Net consists of dense dilated convolutions merged with varying dilation rates. This can effectively enlarge the kernels' receptive fields, and, more importantly, obtain fused local and global context information to promote surrounding discriminative capability. We demonstrate the effectiveness of the proposed DDCM-Net on the publicly available ISPRS Potsdam dataset and achieve a performance of 92.3% F1-score and 86.0% mean intersection over union accuracy by only using the RGB bands, without any post-processing. We also show results on the ISPRS Vaihingen dataset, where the DDCM-Net trained with IRRG bands, also obtained better mapping accuracy (89.8% F1-score) than previous state-of-the-art approaches.
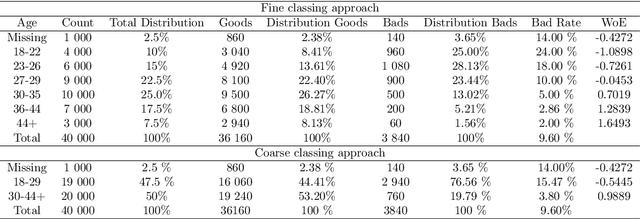
Deep Generative Models for Reject Inference in Credit Scoring
Apr 12, 2019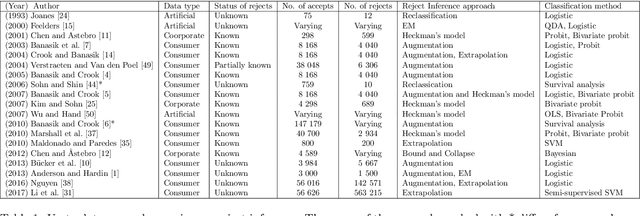
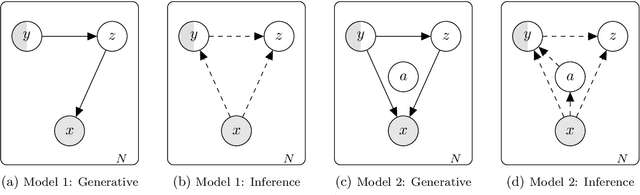

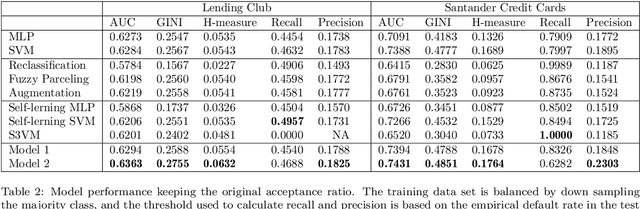
Credit scoring models based on accepted applications may be biased and their consequences can have a statistical and economic impact. Reject inference is the process of attempting to infer the creditworthiness status of the rejected applications. In this research, we use deep generative models to develop two new semi-supervised Bayesian models for reject inference in credit scoring, in which we model the data generating process to be dependent on a Gaussian mixture. The goal is to improve the classification accuracy in credit scoring models by adding reject applications. Our proposed models infer the unknown creditworthiness of the rejected applications by exact enumeration of the two possible outcomes of the loan (default or non-default). The efficient stochastic gradient optimization technique used in deep generative models makes our models suitable for large data sets. Finally, the experiments in this research show that our proposed models perform better than classical and alternative machine learning models for reject inference in credit scoring.
Learning Latent Representations of Bank Customers With The Variational Autoencoder
Mar 14, 2019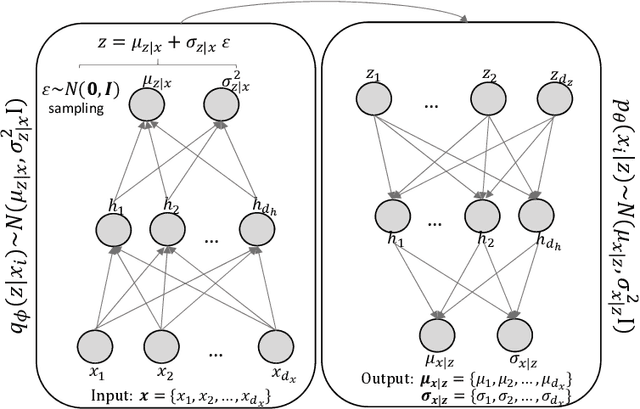
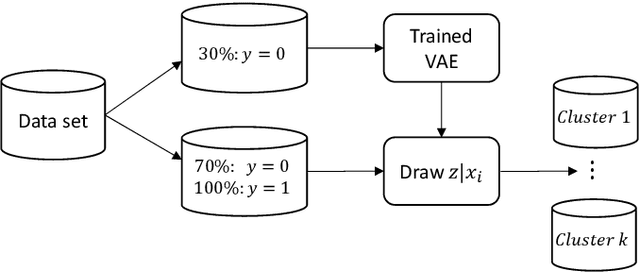

Learning data representations that reflect the customers' creditworthiness can improve marketing campaigns, customer relationship management, data and process management or the credit risk assessment in retail banks. In this research, we adopt the Variational Autoencoder (VAE), which has the ability to learn latent representations that contain useful information. We show that it is possible to steer the latent representations in the latent space of the VAE using the Weight of Evidence and forming a specific grouping of the data that reflects the customers' creditworthiness. Our proposed method learns a latent representation of the data, which shows a well-defied clustering structure capturing the customers' creditworthiness. These clusters are well suited for the aforementioned banks' activities. Further, our methodology generalizes to new customers, captures high-dimensional and complex financial data, and scales to large data sets.
Deep Divergence-Based Approach to Clustering
Feb 13, 2019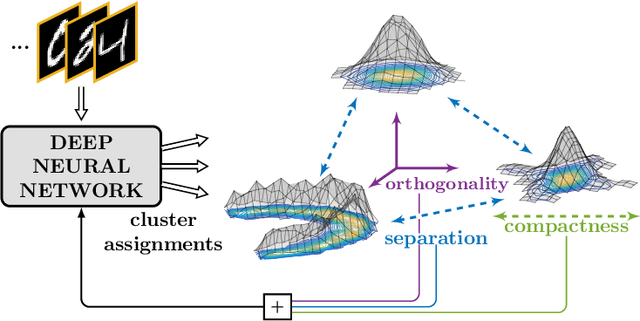
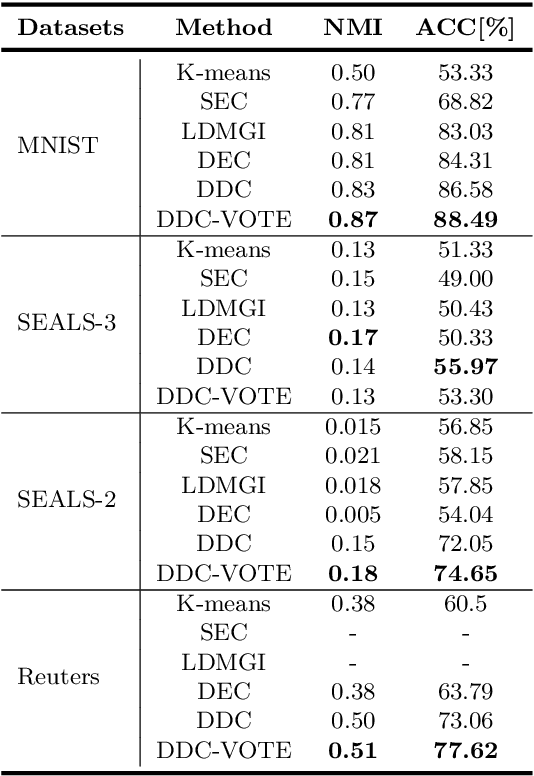
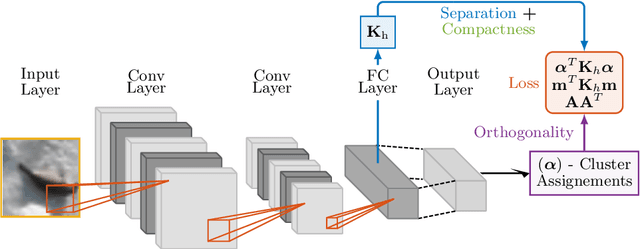
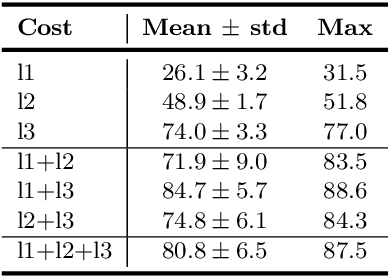
A promising direction in deep learning research consists in learning representations and simultaneously discovering cluster structure in unlabeled data by optimizing a discriminative loss function. As opposed to supervised deep learning, this line of research is in its infancy, and how to design and optimize suitable loss functions to train deep neural networks for clustering is still an open question. Our contribution to this emerging field is a new deep clustering network that leverages the discriminative power of information-theoretic divergence measures, which have been shown to be effective in traditional clustering. We propose a novel loss function that incorporates geometric regularization constraints, thus avoiding degenerate structures of the resulting clustering partition. Experiments on synthetic benchmarks and real datasets show that the proposed network achieves competitive performance with respect to other state-of-the-art methods, scales well to large datasets, and does not require pre-training steps.