 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching AI to Explain its Decisions Using Embeddings and Multi-Task Learning
Jun 05, 2019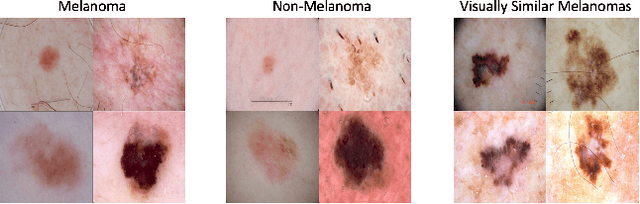
Using machine learning in high-stakes applications often requires predictions to be accompanied by explanations comprehensible to the domain user, who has ultimate responsibility for decisions and outcomes. Recently, a new framework for providing explanations, called TED, has been proposed to provide meaningful explanations for predictions. This framework augments training data to include explanations elicited from domain users, in addition to features and labels. This approach ensures that explanations for predictions are tailored to the complexity expectations and domain knowledge of the consumer. In this paper, we build on this foundational work, by exploring more sophisticated instantiations of the TED framework and empirically evaluate their effectiveness in two diverse domains, chemical odor and skin cancer prediction. Results demonstrate that meaningful explanations can be reliably taught to machine learning algorithms, and in some cases, improving modeling accuracy.
TED: Teaching AI to Explain its Decisions
Nov 12, 2018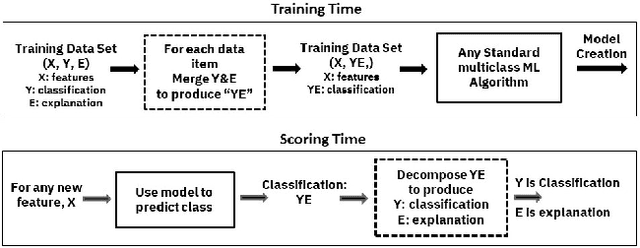

Artificial intelligence systems are being increasingly deployed due to their potential to increase the efficiency, scale, consistency, fairness, and accuracy of decisions. However, as many of these systems are opaque in their operation, there is a growing demand for such systems to provide explanations for their decisions. Conventional approaches to this problem attempt to expose or discover the inner workings of a machine learning model with the hope that the resulting explanations will be meaningful to the consumer. In contrast, this paper suggests a new approach to this problem. It introduces a simple, practical framework, called Teaching Explanations for Decisions (TED), that provides meaningful explanations that match the mental model of the consumer. We illustrate the generality and effectiveness of this approach with two different examples, resulting in highly accurate explanations with no loss of prediction accuracy for these two examples.
AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias
Oct 03, 2018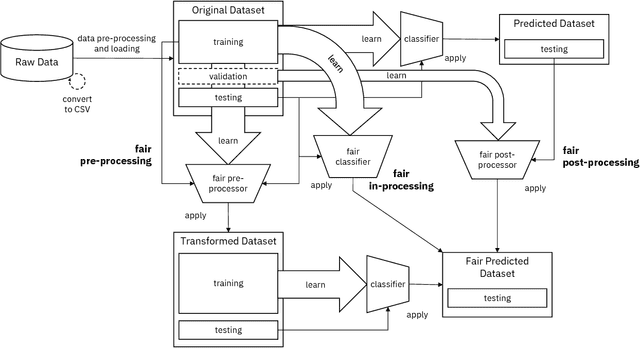
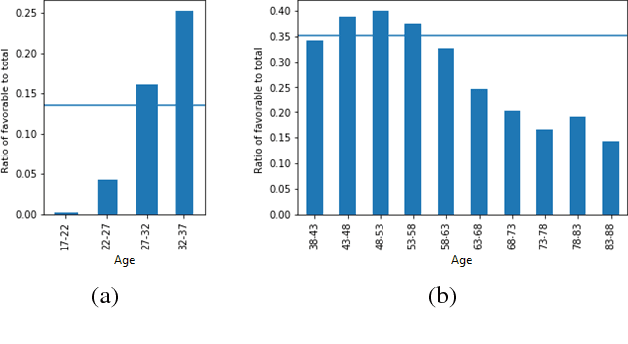
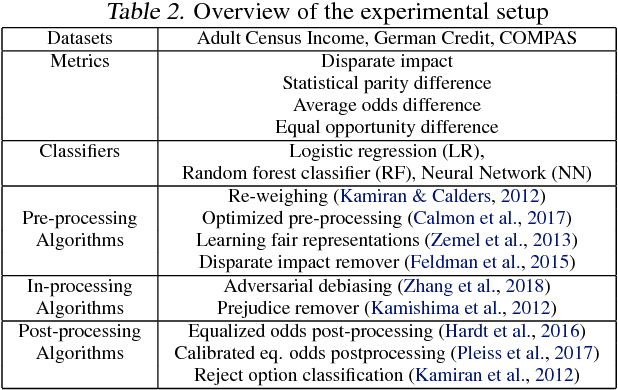
Fairness is an increasingly important concern as machine learning models are used to support decision making in high-stakes applications such as mortgage lending, hiring, and prison sentencing. This paper introduces a new open source Python toolkit for algorithmic fairness, AI Fairness 360 (AIF360), released under an Apache v2.0 license {https://github.com/ibm/aif360). The main objectives of this toolkit are to help facilitate the transition of fairness research algorithms to use in an industrial setting and to provide a common framework for fairness researchers to share and evaluate algorithms. The package includes a comprehensive set of fairness metrics for datasets and models, explanations for these metrics, and algorithms to mitigate bias in datasets and models. It also includes an interactive Web experience (https://aif360.mybluemix.net) that provides a gentle introduction to the concepts and capabilities for line-of-business users, as well as extensive documentation, usage guidance, and industry-specific tutorials to enable data scientists and practitioners to incorporate the most appropriate tool for their problem into their work products. The architecture of the package has been engineered to conform to a standard paradigm used in data science, thereby further improving usability for practitioners. Such architectural design and abstractions enable researchers and developers to extend the toolkit with their new algorithms and improvements, and to use it for performance benchmarking. A built-in testing infrastructure maintains code quality.
Trusted Multi-Party Computation and Verifiable Simulations: A Scalable Blockchain Approach
Sep 22, 2018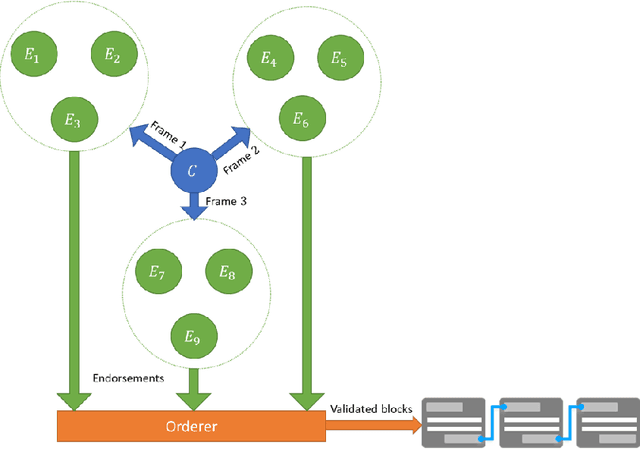

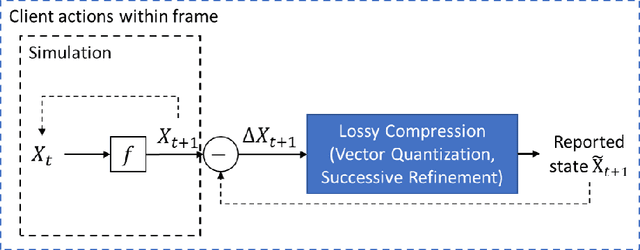
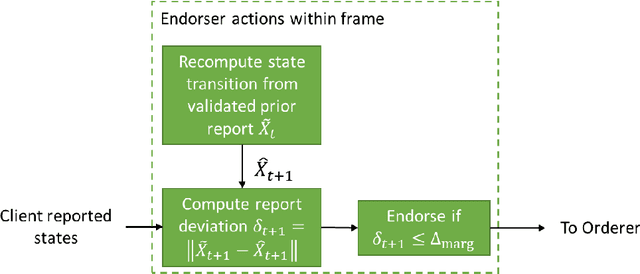
Large-scale computational experiments, often running over weeks and over large datasets, are used extensively in fields such as epidemiology, meteorology, computational biology, and healthcare to understand phenomena, and design high-stakes policies affecting everyday health and economy. For instance, the OpenMalaria framework is a computationally-intensive simulation used by various non-governmental and governmental agencies to understand malarial disease spread and effectiveness of intervention strategies, and subsequently design healthcare policies. Given that such shared results form the basis of inferences drawn, technological solutions designed, and day-to-day policies drafted, it is essential that the computations are validated and trusted. In particular, in a multi-agent environment involving several independent computing agents, a notion of trust in results generated by peers is critical in facilitating transparency, accountability, and collaboration. Using a novel combination of distributed validation of atomic computation blocks and a blockchain-based immutable audits mechanism, this work proposes a universal framework for distributed trust in computations. In particular we address the scalaibility problem by reducing the storage and communication costs using a lossy compression scheme. This framework guarantees not only verifiability of final results, but also the validity of local computations, and its cost-benefit tradeoffs are studied using a synthetic example of training a neural network.
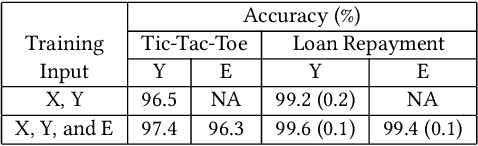
Teaching Meaningful Explanations
Sep 11, 2018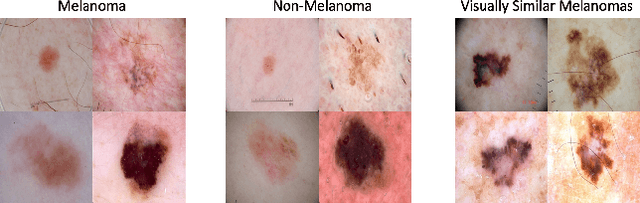
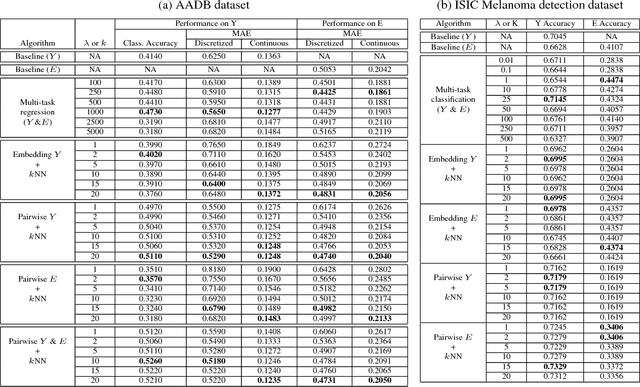
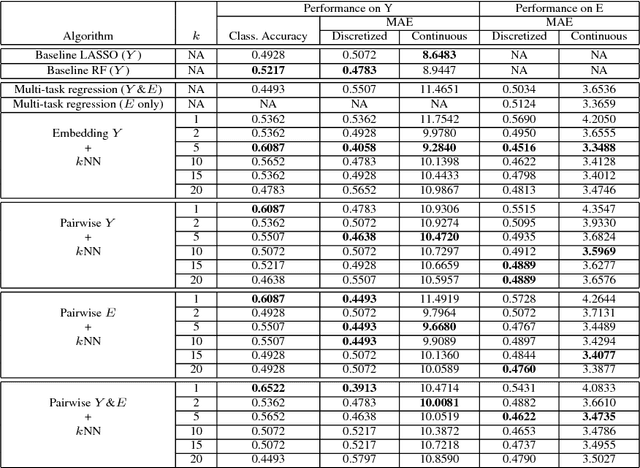
The adoption of machine learning in high-stakes applications such as healthcare and law has lagged in part because predictions are not accompanied by explanations comprehensible to the domain user, who often holds the ultimate responsibility for decisions and outcomes. In this paper, we propose an approach to generate such explanations in which training data is augmented to include, in addition to features and labels, explanations elicited from domain users. A joint model is then learned to produce both labels and explanations from the input features. This simple idea ensures that explanations are tailored to the complexity expectations and domain knowledge of the consumer. Evaluation spans multiple modeling techniques on a game dataset, a (visual) aesthetics dataset, a chemical odor dataset and a Melanoma dataset showing that our approach is generalizable across domains and algorithms. Results demonstrate that meaningful explanations can be reliably taught to machine learning algorithms, and in some cases, also improve modeling accuracy.
Increasing Trust in AI Services through Supplier's Declarations of Conformity
Aug 22, 2018The accuracy and reliability of machine learning algorithms are an important concern for suppliers of artificial intelligence (AI) services, but considerations beyond accuracy, such as safety, security, and provenance, are also critical elements to engender consumers' trust in a service. In this paper, we propose a supplier's declaration of conformity (SDoC) for AI services to help increase trust in AI services. An SDoC is a transparent, standardized, but often not legally required, document used in many industries and sectors to describe the lineage of a product along with the safety and performance testing it has undergone. We envision an SDoC for AI services to contain purpose, performance, safety, security, and provenance information to be completed and voluntarily released by AI service providers for examination by consumers. Importantly, it conveys product-level rather than component-level functional testing. We suggest a set of declaration items tailored to AI and provide examples for two fictitious AI services.
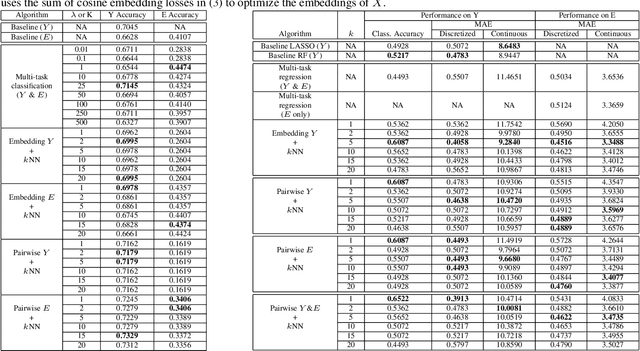
Collaborative Human-AI (CHAI): Evidence-Based Interpretable Melanoma Classification in Dermoscopic Images
Aug 01, 2018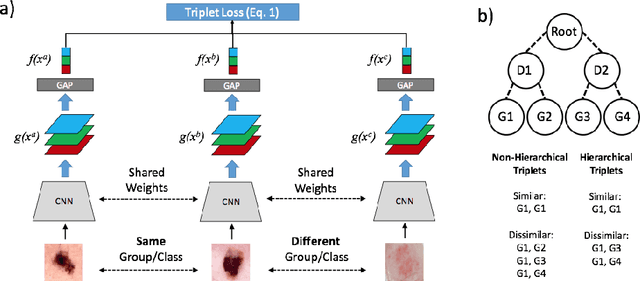
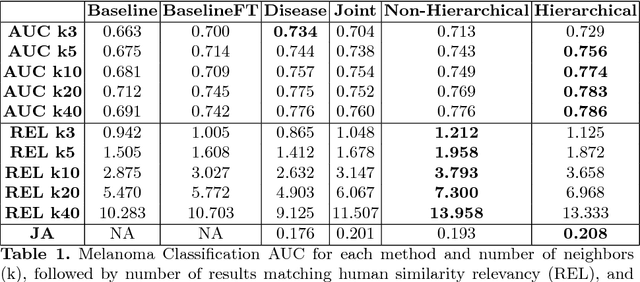
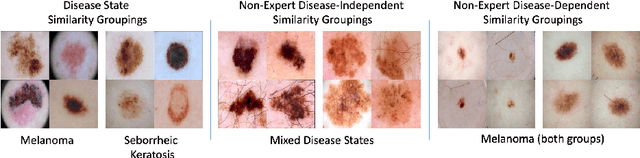
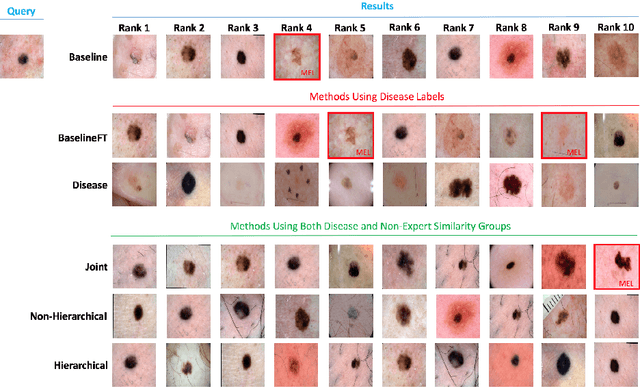
Automated dermoscopic image analysis has witnessed rapid growth in diagnostic performance. Yet adoption faces resistance, in part, because no evidence is provided to support decisions. In this work, an approach for evidence-based classification is presented. A feature embedding is learned with CNNs, triplet-loss, and global average pooling, and used to classify via kNN search. Evidence is provided as both the discovered neighbors, as well as localized image regions most relevant to measuring distance between query and neighbors. To ensure that results are relevant in terms of both label accuracy and human visual similarity for any skill level, a novel hierarchical triplet logic is implemented to jointly learn an embedding according to disease labels and non-expert similarity. Results are improved over baselines trained on disease labels alone, as well as standard multiclass loss. Quantitative relevance of results, according to non-expert similarity, as well as localized image regions, are also significantly improved.