 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-Box Saliency Map Generation Using Bayesian Optimisation
Jan 30, 2020
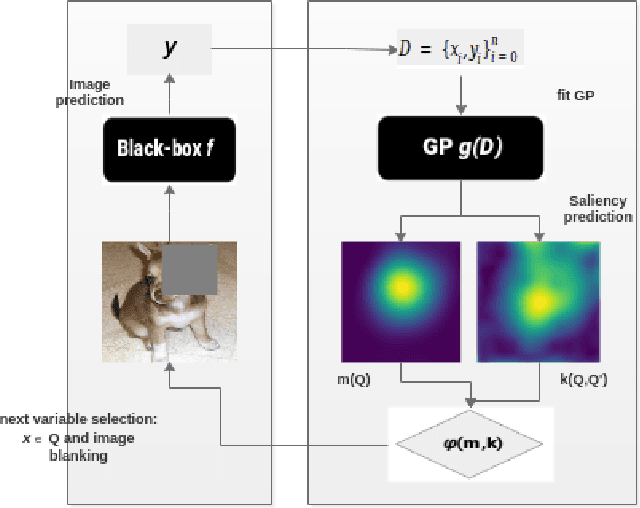
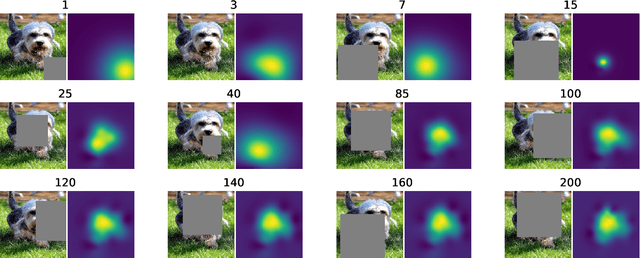
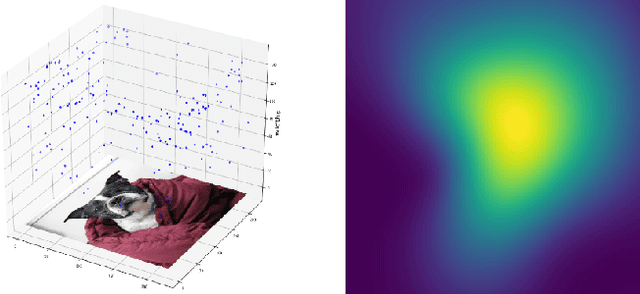
Saliency maps are often used in computer vision to provide intuitive interpretations of what input regions a model has used to produce a specific prediction. A number of approaches to saliency map generation are available, but most require access to model parameters. This work proposes an approach for saliency map generation for black-box models, where no access to model parameters is available, using a Bayesian optimisation sampling method. The approach aims to find the global salient image region responsible for a particular (black-box) model's prediction. This is achieved by a sampling-based approach to model perturbations that seeks to localise salient regions of an image to the black-box model. Results show that the proposed approach to saliency map generation outperforms grid-based perturbation approaches, and performs similarly to gradient-based approaches which require access to model parameters.
Learning with Modular Representations for Long-Term Multi-Agent Motion Predictions
Jan 17, 2020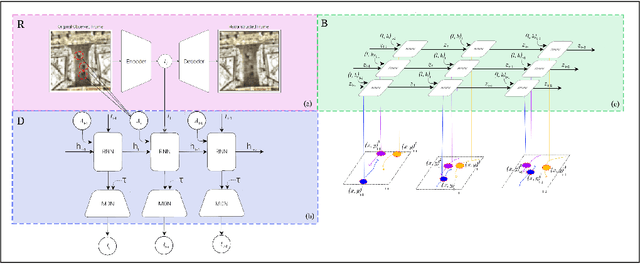
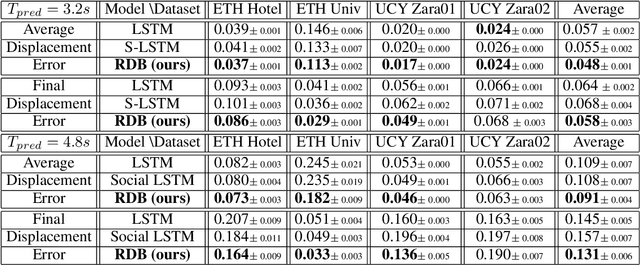
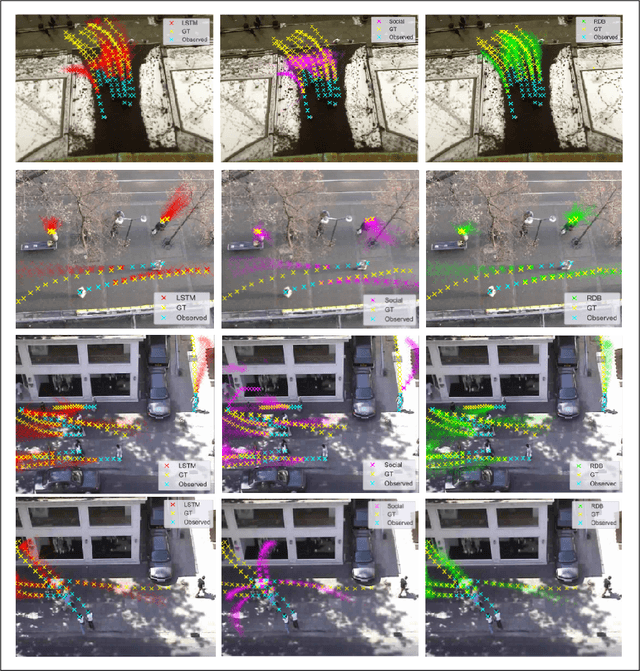
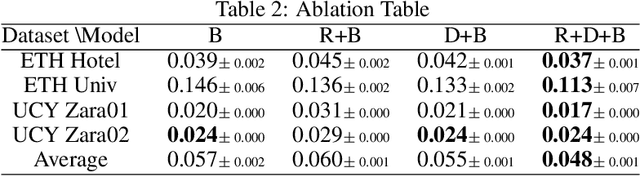
Context plays a significant role in the generation of motion for dynamic agents in interactive environments. This work proposes a modular method that utilises a model of the environment to aid motion prediction of tracked agents. This paper shows that modelling the spatial and dynamic aspects of a given environment alongside the local per agent behaviour results in more accurate and informed long-term motion prediction. Further, we observe that this decoupling of dynamics and environment models allows for better adaptation to unseen environments, requiring that only a spatial representation of a new environment be learned. We highlight the model's prediction capability using a benchmark pedestrian tracking problem and by tracking a robot arm performing a tabletop manipulation task. The proposed approach allows for robust and data efficient forward modelling, and relaxes the need for full model re-training in new environments. We evaluate this through an ablation study which shows better performance gain when utilising both representation modules in addition to improved generalisation on tasks with dynamics unseen at training time.
Bias Remediation in Driver Drowsiness Detection systems using Generative Adversarial Networks
Dec 10, 2019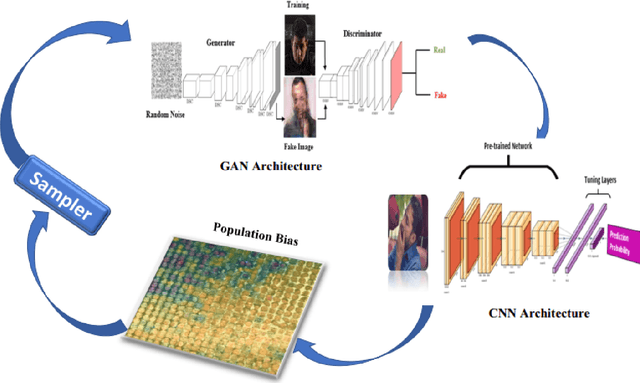
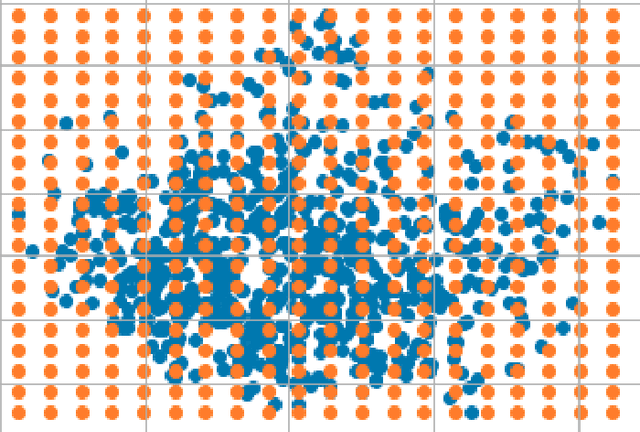


Datasets are crucial when training a deep neural network. When datasets are unrepresentative, trained models are prone to bias because they are unable to generalise to real world settings. This is particularly problematic for models trained in specific cultural contexts, which may not represent a wide range of races, and thus fail to generalise. This is a particular challenge for Driver drowsiness detection, where many publicly available datasets are unrepresentative as they cover only certain ethnicity groups. Traditional augmentation methods are unable to improve a model's performance when tested on other groups with different facial attributes, and it is often challenging to build new, more representative datasets. In this paper, we introduce a novel framework that boosts the performance of detection of drowsiness for different ethnicity groups. Our framework improves Convolutional Neural Network (CNN) trained for prediction by using Generative Adversarial networks (GAN) for targeted data augmentation based on a population bias visualisation strategy that groups faces with similar facial attributes and highlights where the model is failing. A sampling method selects faces where the model is not performing well, which are used to fine-tune the CNN. Experiments show the efficacy of our approach in improving driver drowsiness detection for under represented ethnicity groups. Here, models trained on publicly available datasets are compared with a model trained using the proposed data augmentation strategy. Although developed in the context of driver drowsiness detection, the proposed framework is not limited to the driver drowsiness detection task, but can be applied to other applications.
Surfing on an uncertain edge: Precision cutting of soft tissue using torque-based medium classification
Sep 16, 2019
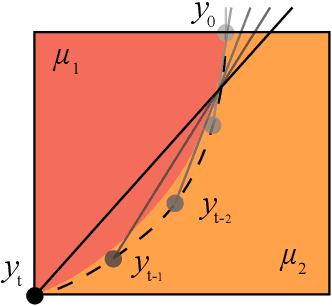
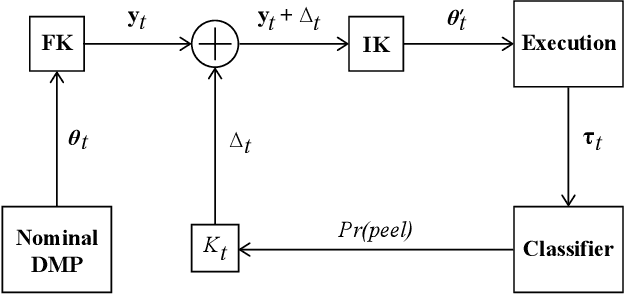

Precision cutting of soft-tissue remains a challenging problem in robotics, due to the complex and unpredictable mechanical behaviour of tissue under manipulation. Here, we consider the challenge of cutting along the boundary between two soft mediums, a problem that is made extremely difficult due to visibility constraints, which means that the precise location of the cutting trajectory is typically unknown. This paper introduces a novel strategy to address this task, using a binary medium classifier trained using joint torque measurements, and a closed loop control law that relies on an error signal compactly encoded in the decision boundary of the classifier. We illustrate this on a grapefruit cutting task, successfully modulating a nominal trajectory fit using dynamic movement primitives to follow the boundary between grapefruit pulp and peel using torque based medium classification. Results show that this control strategy is successful in 72 % of attempts in contrast to control using a nominal trajectory, which only succeeds in 50 % of attempts.
Hybrid system identification using switching density networks
Aug 06, 2019Behaviour cloning is a commonly used strategy for imitation learning and can be extremely effective in constrained domains. However, in cases where the dynamics of an environment may be state dependent and varying, behaviour cloning places a burden on model capacity and the number of demonstrations required. This paper introduces switching density networks, which rely on a categorical reparametrisation for hybrid system identification. This results in a network comprising a classification layer that is followed by a regression layer. We use switching density networks to predict the parameters of hybrid control laws, which are toggled by a switching layer to produce different controller outputs, when conditioned on an input state. This work shows how switching density networks can be used for hybrid system identification in a variety of tasks, successfully identifying the key joint angle goals that make up manipulation tasks, while simultaneously learning image-based goal classifiers and regression networks that predict joint angles from images. We also show that they can cluster the phase space of an inverted pendulum, identifying the balance, spin and pump controllers required to solve this task. Switching density networks can be difficult to train, but we introduce a cross entropy regularisation loss that stabilises training.
Disentangled Relational Representations for Explaining and Learning from Demonstration
Jul 31, 2019
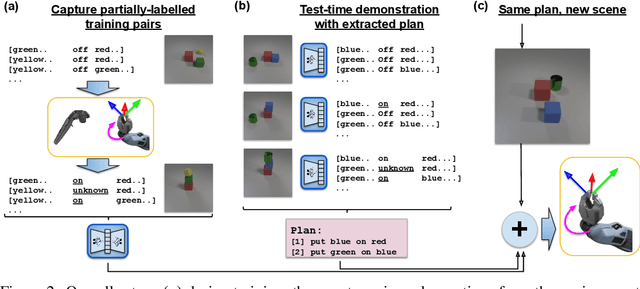

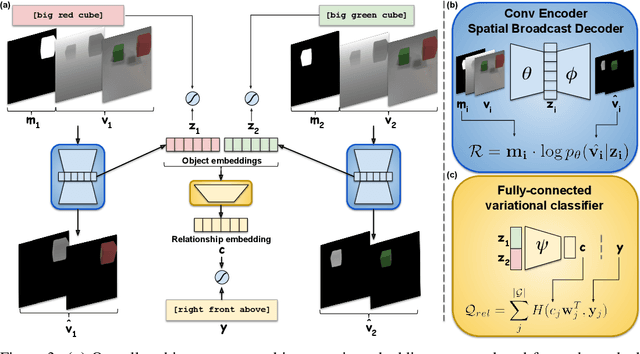
Learning from demonstration is an effective method for human users to instruct desired robot behaviour. However, for most non-trivial tasks of practical interest, efficient learning from demonstration depends crucially on inductive bias in the chosen structure for rewards/costs and policies. We address the case where this inductive bias comes from an exchange with a human user. We propose a method in which a learning agent utilizes the information bottleneck layer of a high-parameter variational neural model, with auxiliary loss terms, in order to ground abstract concepts such as spatial relations. The concepts are referred to in natural language instructions and are manifested in the high-dimensional sensory input stream the agent receives from the world. We evaluate the properties of the latent space of the learned model in a photorealistic synthetic environment and particularly focus on examining its usability for downstream tasks. Additionally, through a series of controlled table-top manipulation experiments, we demonstrate that the learned manifold can be used to ground demonstrations as symbolic plans, which can then be executed on a PR2 robot.
Composing Diverse Policies for Temporally Extended Tasks
Jul 18, 2019
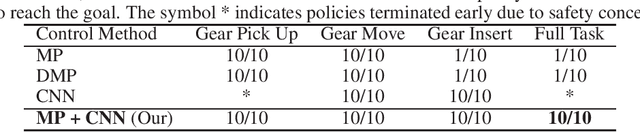
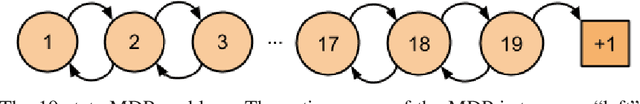
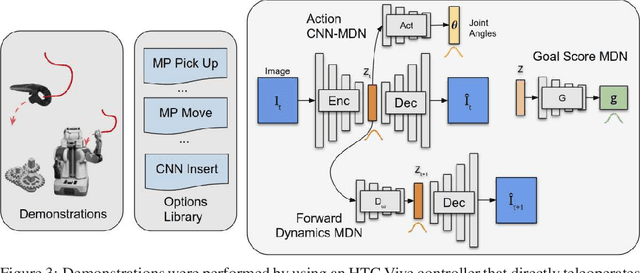
Temporally extended and sequenced robot motion tasks are often characterized by discontinuous switches between different types of local dynamics. These change-points can be exploited to build approximate models of the interleaving regions, which in turn allow the design of region-specific controllers. These can then be combined to create the initiation state-space of a final policy. However, such a pipeline can become challenging to implement for combinatorially complex, temporarily extended tasks - especially so when sub-controllers work on different information streams, time scales and action spaces. In this paper, we introduce a method that can compose diverse policies based on scripted motion planning, dynamic motion primitives and neural networks. In order to do this, we extend the options framework to introduce a per-option dynamics module and a global function that evaluates a goal metric. Additionally, we can leverage expert demonstrations to sequence these local policies, converting the learning problem in hierarchical reinforcement learning to a planning problem at inference time. We first illustrate the core concepts with an MDP benchmark, and then with a physical gear assembly task solved on a PR2 robot. We show that the proposed approach successfully discovers the optimal sequence of policies and solves both tasks efficiently.
Vid2Param: Online system identification from video for robotics applications
Jul 15, 2019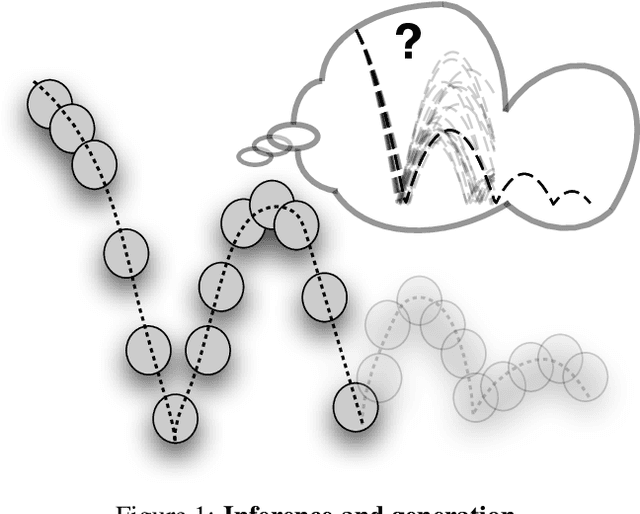

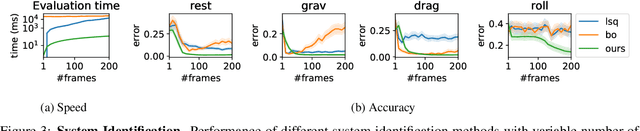
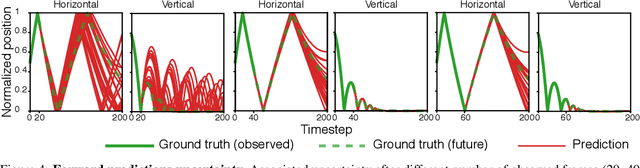
Robots performing tasks in dynamic environments would benefit greatly from understanding the underlying environment motion, in order to make future predictions and to synthesize effective control policies that use this inductive bias. Online system identification is therefore a fundamental requirement for robust autonomous agents. When the dynamics involves multiple modes (due to contacts or interactions between objects), and when system identification must proceed directly from a rich sensory stream such as video, then traditional methods for system identification may not be well suited. We propose an approach wherein fast parameter estimation with a model can be seamlessly combined with a recurrent variational autoencoder. Our Physics-based recurrent variational autoencoder model includes an additional loss that enforces conformity with the structure of a physically based dynamics model. This enables the resulting model to encode parameters such as position, velocity, restitution, air drag and other physical properties of the system. The model can be trained entirely in simulation, in an end-to-end manner with domain randomization, to perform online system identification, and probabilistic forward predictions of parameters of interest. We benchmark against existing system identification methods and demonstrate that Vid2Param outperforms the baselines in terms of speed and accuracy of identification, and also provides uncertainty quantification in the form of a distribution over future trajectories. Furthermore, we illustrate the utility of this in physical experiments wherein a PR2 robot with velocity constrained arm must intercept a bouncing ball, by estimating the physical parameters of this ball directly from the video trace after the ball is released.
Physics-as-Inverse-Graphics: Joint Unsupervised Learning of Objects and Physics from Video
May 27, 2019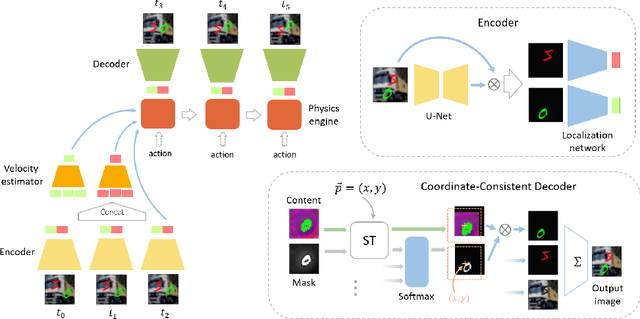



We aim to perform unsupervised discovery of objects and their states such as location and velocity, as well as physical system parameters such as mass and gravity from video -- given only the differential equations governing the scene dynamics. Existing physical scene understanding methods require either object state supervision, or do not integrate with differentiable physics to learn interpretable system parameters and states. We address this problem through a $\textit{physics-as-inverse-graphics}$ approach that brings together vision-as-inverse-graphics and differentiable physics engines. This framework allows us to perform long term extrapolative video prediction, as well as vision-based model-predictive control. Our approach significantly outperforms related unsupervised methods in long-term future frame prediction of systems with interacting objects (such as ball-spring or 3-body gravitational systems). We further show the value of this tight vision-physics integration by demonstrating data-efficient learning of vision-actuated model-based control for a pendulum system. The controller's interpretability also provides unique capabilities in goal-driven control and physical reasoning for zero-data adaptation.
Detecting inter-sectional accuracy differences in driver drowsiness detection algorithms
Apr 23, 2019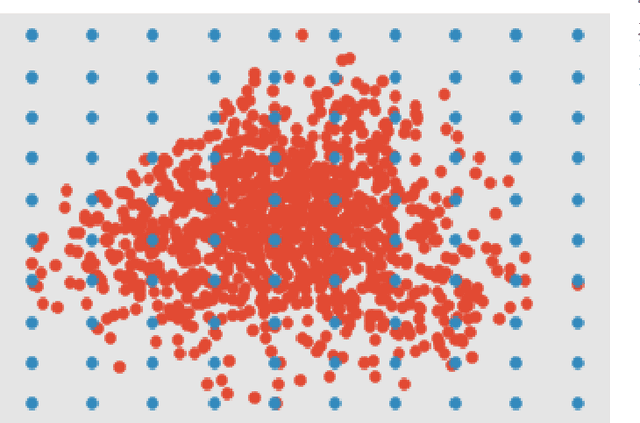

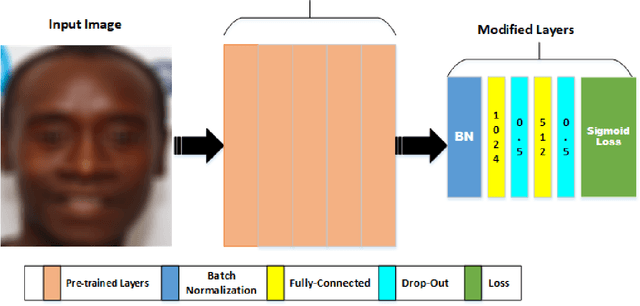
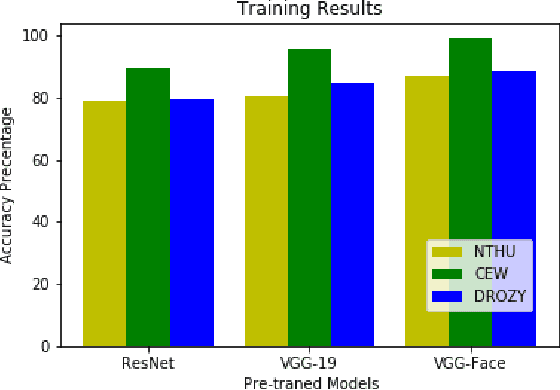
Convolutional Neural Networks (CNNs) have been used successfully across a broad range of areas including data mining, object detection, and in business. The dominance of CNNs follows a breakthrough by Alex Krizhevsky which showed improvements by dramatically reducing the error rate obtained in a general image classification task from 26.2% to 15.4%. In road safety, CNNs have been applied widely to the detection of traffic signs, obstacle detection, and lane departure checking. In addition, CNNs have been used in data mining systems that monitor driving patterns and recommend rest breaks when appropriate. This paper presents a driver drowsiness detection system and shows that there are potential social challenges regarding the application of these techniques, by highlighting problems in detecting dark-skinned driver's faces. This is a particularly important challenge in African contexts, where there are more dark-skinned drivers. Unfortunately, publicly available datasets are often captured in different cultural contexts, and therefore do not cover all ethnicities, which can lead to false detections or racially biased models. This work evaluates the performance obtained when training convolutional neural network models on commonly used driver drowsiness detection datasets and testing on datasets specifically chosen for broader representation. Results show that models trained using publicly available datasets suffer extensively from over-fitting, and can exhibit racial bias, as shown by testing on a more representative dataset. We propose a novel visualisation technique that can assist in identifying groups of people where there might be the potential of discrimination, using Principal Component Analysis (PCA) to produce a grid of faces sorted by similarity, and combining these with a model accuracy overlay.