 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarginalising over Stationary Kernels with Bayesian Quadrature
Jun 14, 2021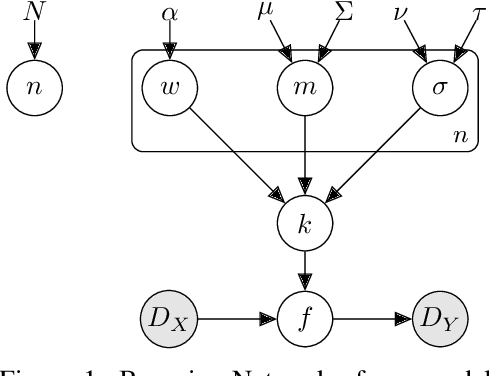

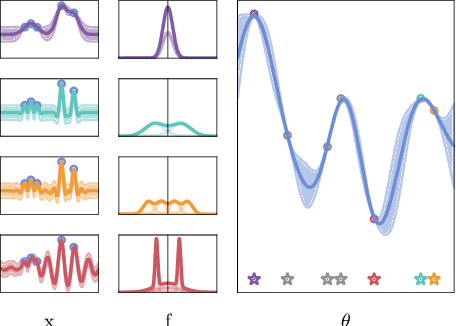

Marginalising over families of Gaussian Process kernels produces flexible model classes with well-calibrated uncertainty estimates. Existing approaches require likelihood evaluations of many kernels, rendering them prohibitively expensive for larger datasets. We propose a Bayesian Quadrature scheme to make this marginalisation more efficient and thereby more practical. Through use of the maximum mean discrepancies between distributions, we define a kernel over kernels that captures invariances between Spectral Mixture (SM) Kernels. Kernel samples are selected by generalising an information-theoretic acquisition function for warped Bayesian Quadrature. We show that our framework achieves more accurate predictions with better calibrated uncertainty than state-of-the-art baselines, especially when given limited (wall-clock) time budgets.
Think Global and Act Local: Bayesian Optimisation over High-Dimensional Categorical and Mixed Search Spaces
Feb 14, 2021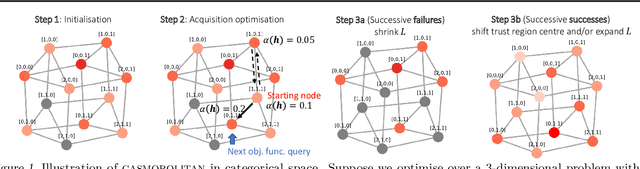

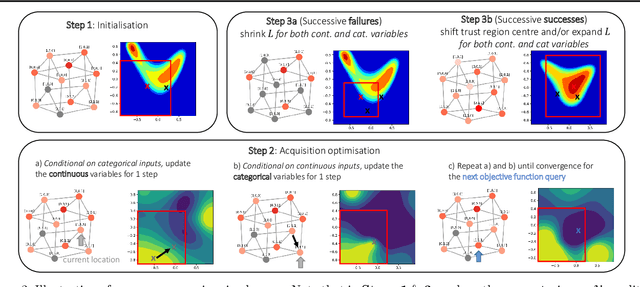
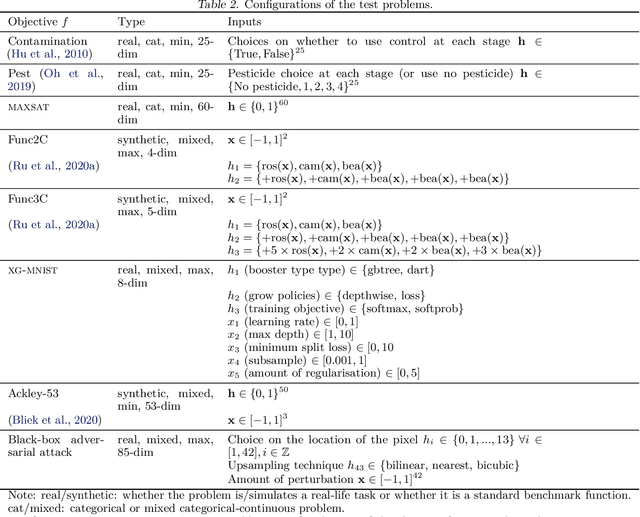
High-dimensional black-box optimisation remains an important yet notoriously challenging problem. Despite the success of Bayesian optimisation methods on continuous domains, domains that are categorical, or that mix continuous and categorical variables, remain challenging. We propose a novel solution -- we combine local optimisation with a tailored kernel design, effectively handling high-dimensional categorical and mixed search spaces, whilst retaining sample efficiency. We further derive convergence guarantee for the proposed approach. Finally, we demonstrate empirically that our method outperforms the current baselines on a variety of synthetic and real-world tasks in terms of performance, computational costs, or both.
Gaussian Process Bandit Optimization of the Thermodynamic Variational Objective
Oct 31, 2020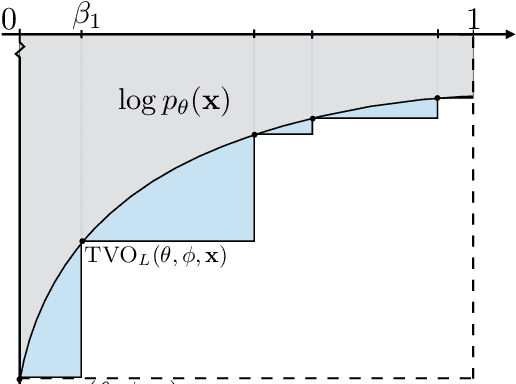

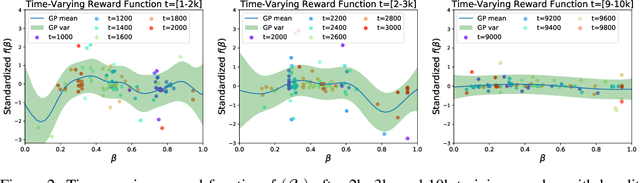

Achieving the full promise of the Thermodynamic Variational Objective (TVO), a recently proposed variational lower bound on the log evidence involving a one-dimensional Riemann integral approximation, requires choosing a "schedule" of sorted discretization points. This paper introduces a bespoke Gaussian process bandit optimization method for automatically choosing these points. Our approach not only automates their one-time selection, but also dynamically adapts their positions over the course of optimization, leading to improved model learning and inference. We provide theoretical guarantees that our bandit optimization converges to the regret-minimizing choice of integration points. Empirical validation of our algorithm is provided in terms of improved learning and inference in Variational Autoencoders and Sigmoid Belief Networks.
Adaptive Configuration Oracle for Online Portfolio Selection Methods
Aug 22, 2019
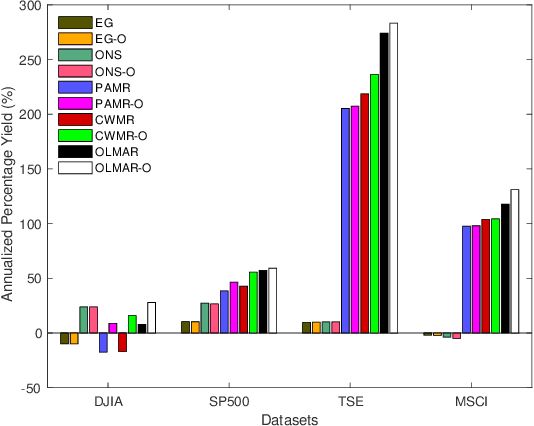
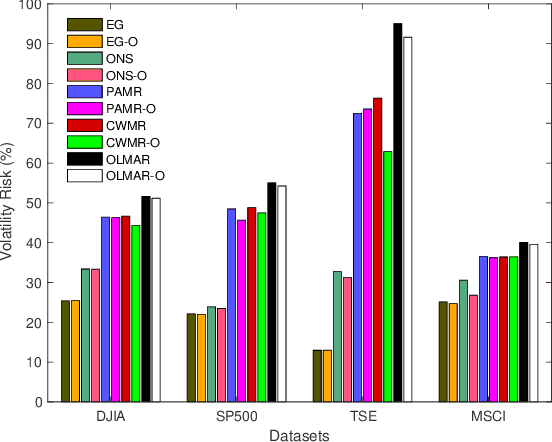
Financial markets are complex environments that produce enormous amounts of noisy and non-stationary data. One fundamental problem is online portfolio selection, the goal of which is to exploit this data to sequentially select portfolios of assets to achieve positive investment outcomes while managing risks. Various algorithms have been proposed for solving this problem in fields such as finance, statistics and machine learning, among others. Most of the methods have parameters that are estimated from backtests for good performance. Since these algorithms operate on non-stationary data that reflects the complexity of financial markets, we posit that adaptively tuning these parameters in an intelligent manner is a remedy for dealing with this complexity. In this paper, we model the mapping between the parameter space and the space of performance metrics using a Gaussian process prior. We then propose an oracle based on adaptive Bayesian optimization for automatically and adaptively configuring online portfolio selection methods. We test the efficacy of our solution on algorithms operating on equity and index data from various markets.
Bayesian Optimisation over Multiple Continuous and Categorical Inputs
Jun 20, 2019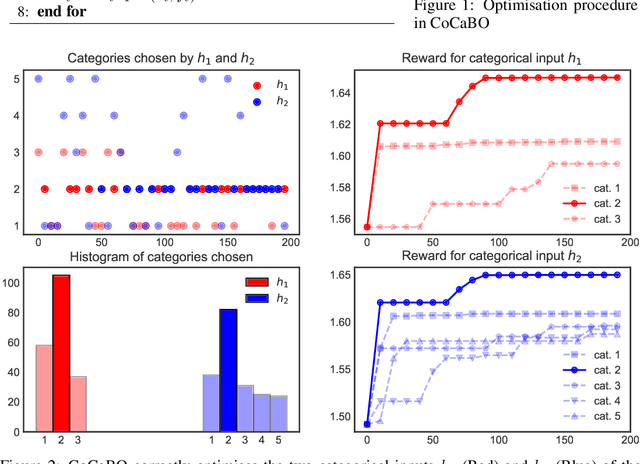

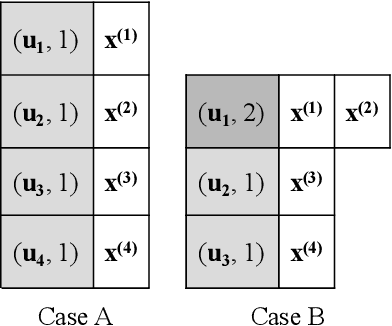

Efficient optimisation of black-box problems that comprise both continuous and categorical inputs is important, yet poses significant challenges. We propose a new approach, Continuous and Categorical Bayesian Optimisation (CoCaBO), which combines the strengths of multi-armed bandits and Bayesian optimisation to select values for both categorical and continuous inputs. We model this mixed-type space using a Gaussian Process kernel, designed to allow sharing of information across multiple categorical variables, each with multiple possible values; this allows CoCaBO to leverage all available data efficiently. We extend our method to the batch setting and propose an efficient selection procedure that dynamically balances exploration and exploitation whilst encouraging batch diversity. We demonstrate empirically that our method outperforms existing approaches on both synthetic and real-world optimisation tasks with continuous and categorical inputs.
Knowing The What But Not The Where in Bayesian Optimization
May 11, 2019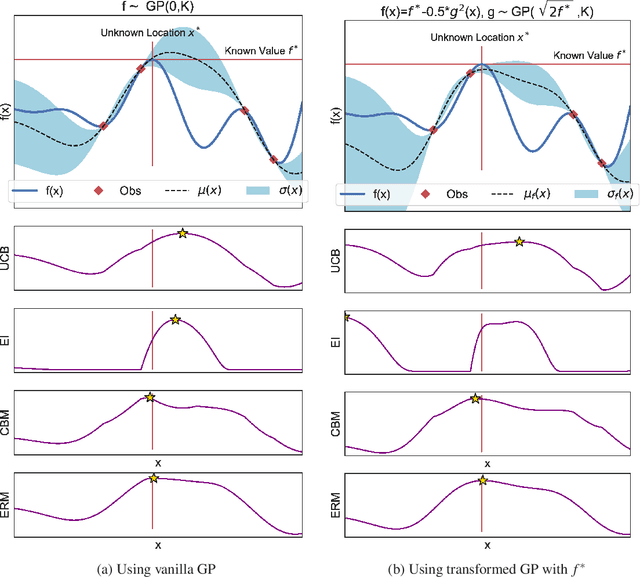
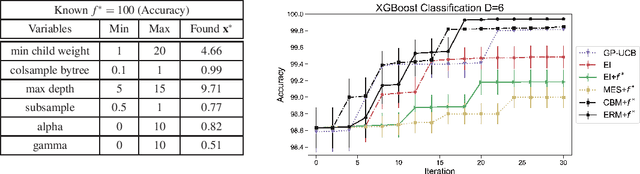
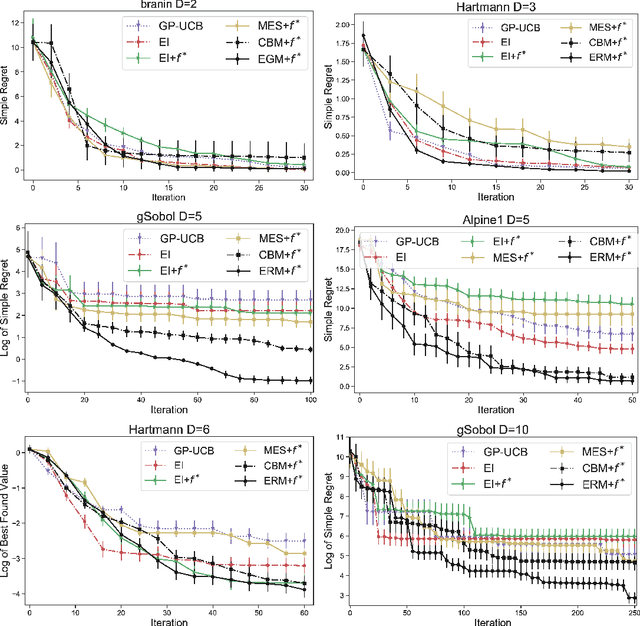
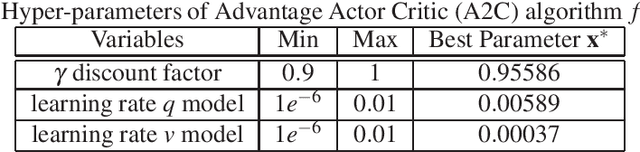
Bayesian optimization has demonstrated impressive success in finding the optimum location $x^{*}$ and value $f^{*}=f(x^{*})=\max_{x\in\mathcal{X}}f(x)$ of the black-box function $f$. In some applications, however, the optimum value is known in advance and the goal is to find the corresponding optimum location. Existing work in Bayesian optimization (BO) has not effectively exploited the knowledge of $f^{*}$ for optimization. In this paper, we consider a new setting in BO in which the knowledge of the optimum value is available. Our goal is to exploit the knowledge about $f^{*}$ to search for the location $x^{*}$ efficiently. To achieve this goal, we first transform the Gaussian process surrogate using the information about the optimum value. Then, we propose two acquisition functions, called confidence bound minimization and expected regret minimization, which exploit the knowledge about the optimum value to identify the optimum location efficiently. We show that our approaches work both intuitively and quantitatively achieve better performance against standard BO methods. We demonstrate real applications in tuning a deep reinforcement learning algorithm on the CartPole problem and XGBoost on Skin Segmentation dataset in which the optimum values are publicly available.
Automated Model Selection with Bayesian Quadrature
Mar 01, 2019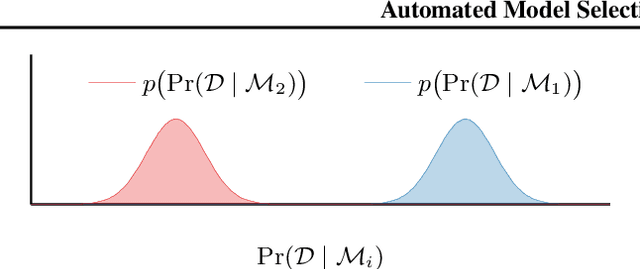
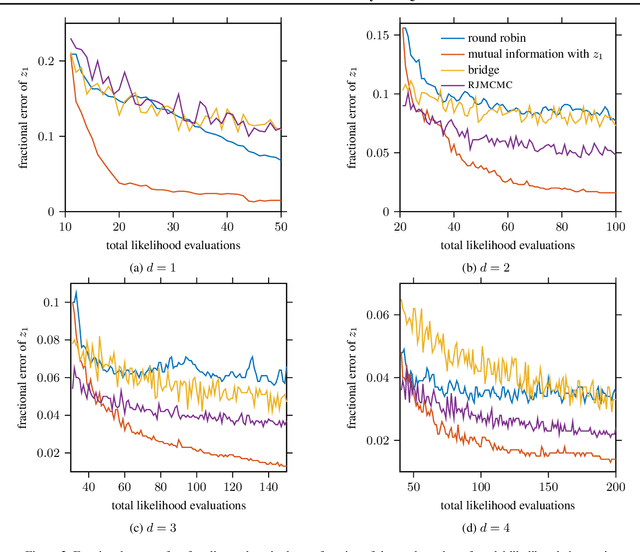
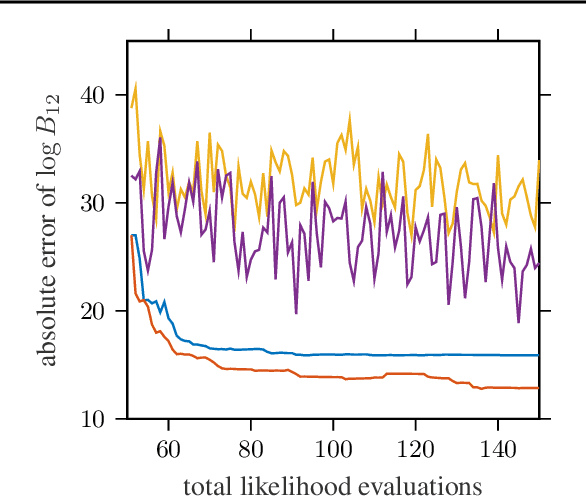
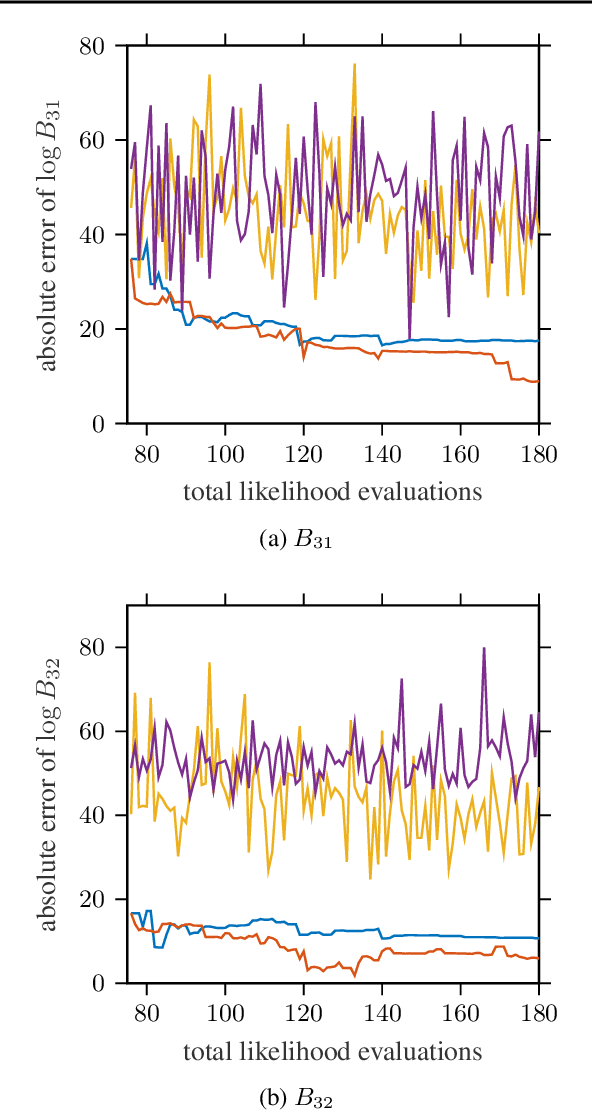
We present a novel technique for tailoring Bayesian quadrature (BQ) to model selection. The state-of-the-art for comparing the evidence of multiple models relies on Monte Carlo methods, which converge slowly and are unreliable for computationally expensive models. Previous research has shown that BQ offers sample efficiency superior to Monte Carlo in computing the evidence of an individual model. However, applying BQ directly to model comparison may waste computation producing an overly-accurate estimate for the evidence of a clearly poor model. We propose an automated and efficient algorithm for computing the most-relevant quantity for model selection: the posterior probability of a model. Our technique maximizes the mutual information between this quantity and observations of the models' likelihoods, yielding efficient acquisition of samples across disparate model spaces when likelihood observations are limited. Our method produces more-accurate model posterior estimates using fewer model likelihood evaluations than standard Bayesian quadrature and Monte Carlo estimators, as we demonstrate on synthetic and real-world examples.
Asynchronous Batch Bayesian Optimisation with Improved Local Penalisation
Jan 30, 2019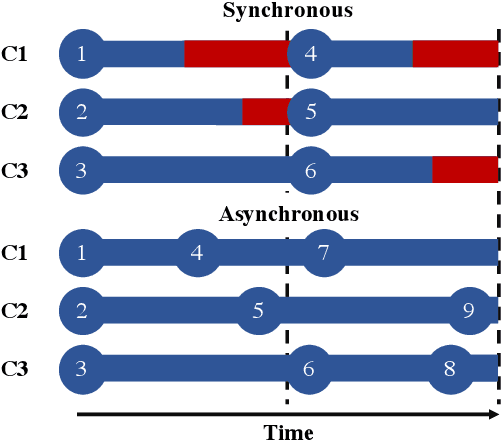
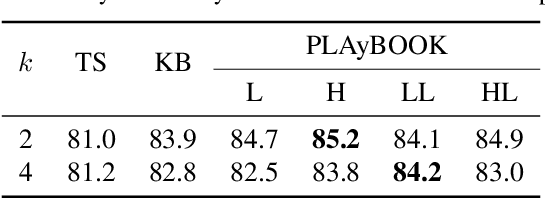
Batch Bayesian optimisation (BO) has been successfully applied to hyperparameter tuning using parallel computing, but it is wasteful of resources: workers that complete jobs ahead of others are left idle. We address this problem by developing an approach, Penalising Locally for Asynchronous Bayesian Optimisation on $k$ workers (PLAyBOOK), for asynchronous parallel BO. We demonstrate empirically the efficacy of PLAyBOOK and its variants on synthetic tasks and a real-world problem. We undertake a comparison between synchronous and asynchronous BO, and show that asynchronous BO often outperforms synchronous batch BO in both wall-clock time and number of function evaluations.
Rejoinder for "Probabilistic Integration: A Role in Statistical Computation?"
Nov 26, 2018This article is the rejoinder for the paper "Probabilistic Integration: A Role in Statistical Computation?" to appear in Statistical Science with discussion. We would first like to thank the reviewers and many of our colleagues who helped shape this paper, the editor for selecting our paper for discussion, and of course all of the discussants for their thoughtful, insightful and constructive comments. In this rejoinder, we respond to some of the points raised by the discussants and comment further on the fundamental questions underlying the paper: (i) Should Bayesian ideas be used in numerical analysis?, and (ii) If so, what role should such approaches have in statistical computation?
Fingerprint Policy Optimisation for Robust Reinforcement Learning
Sep 15, 2018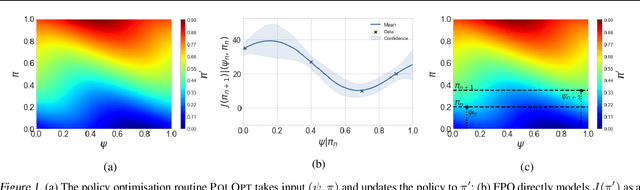
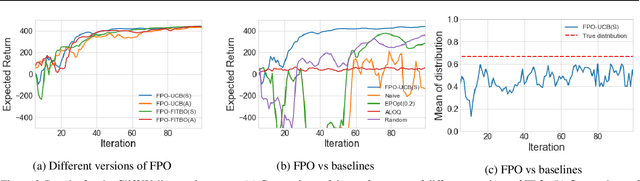
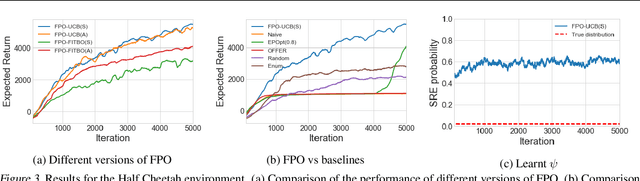
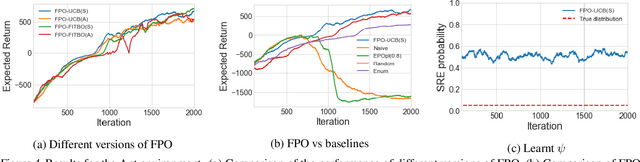
Policy gradient methods have been successfully applied to a variety of reinforcement learning tasks. However, while learning in a simulator, these methods do not utilise the opportunity to improve learning by adjusting certain environment variables: unobservable state features that are randomly determined by the environment in a physical setting, but that are controllable in a simulator. This can lead to slow learning or convergence to highly suboptimal policies if the environment variable has a large impact on the transition dynamics. In this paper, we present fingerprint policy optimisation (FPO) which finds a policy that is optimal in expectation across the distribution of environment variables. The central idea is to use Bayesian optimisation (BO) to actively select the distribution of the environment variable that maximises the improvement generated by each iteration of the policy gradient method. To make this BO practical, we contribute two easy-to-compute low-dimensional fingerprints of the current policy. We apply FPO to a number of continuous control tasks of varying difficulty and show that FPO can efficiently learn policies that are robust to significant rare events, which are unlikely to be observable under random sampling but are key to learning good policies.