 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
Mar 12, 2026Multimodal agents offer a promising path to automating complex document-intensive workflows. Yet, a critical question remains: do these agents demonstrate genuine strategic reasoning, or merely stochastic trial-and-error search? To address this, we introduce MADQA, a benchmark of 2,250 human-authored questions grounded in 800 heterogeneous PDF documents. Guided by Classical Test Theory, we design it to maximize discriminative power across varying levels of agentic abilities. To evaluate agentic behaviour, we introduce a novel evaluation protocol measuring the accuracy-effort trade-off. Using this framework, we show that while the best agents can match human searchers in raw accuracy, they succeed on largely different questions and rely on brute-force search to compensate for weak strategic planning. They fail to close the nearly 20% gap to oracle performance, persisting in unproductive loops. We release the dataset and evaluation harness to help facilitate the transition from brute-force retrieval to calibrated, efficient reasoning.
Unchecked and Overlooked: Addressing the Checkbox Blind Spot in Large Language Models with CheckboxQA
Apr 15, 2025



Checkboxes are critical in real-world document processing where the presence or absence of ticks directly informs data extraction and decision-making processes. Yet, despite the strong performance of Large Vision and Language Models across a wide range of tasks, they struggle with interpreting checkable content. This challenge becomes particularly pressing in industries where a single overlooked checkbox may lead to costly regulatory or contractual oversights. To address this gap, we introduce the CheckboxQA dataset, a targeted resource designed to evaluate and improve model performance on checkbox-related tasks. It reveals the limitations of current models and serves as a valuable tool for advancing document comprehension systems, with significant implications for applications in sectors such as legal tech and finance. The dataset is publicly available at: https://github.com/Snowflake-Labs/CheckboxQA
Arctic-TILT. Business Document Understanding at Sub-Billion Scale
Aug 08, 2024The vast portion of workloads employing LLMs involves answering questions grounded on PDF or scan content. We introduce the Arctic-TILT achieving accuracy on par with models 1000$\times$ its size on these use cases. It can be fine-tuned and deployed on a single 24GB GPU, lowering operational costs while processing Visually Rich Documents with up to 400k tokens. The model establishes state-of-the-art results on seven diverse Document Understanding benchmarks, as well as provides reliable confidence scores and quick inference, which are essential for processing files in large-scale or time-sensitive enterprise environments.
CCpdf: Building a High Quality Corpus for Visually Rich Documents from Web Crawl Data
Apr 28, 2023In recent years, the field of document understanding has progressed a lot. A significant part of this progress has been possible thanks to the use of language models pretrained on large amounts of documents. However, pretraining corpora used in the domain of document understanding are single domain, monolingual, or nonpublic. Our goal in this paper is to propose an efficient pipeline for creating a big-scale, diverse, multilingual corpus of PDF files from all over the Internet using Common Crawl, as PDF files are the most canonical types of documents as considered in document understanding. We analysed extensively all of the steps of the pipeline and proposed a solution which is a trade-off between data quality and processing time. We also share a CCpdf corpus in a form or an index of PDF files along with a script for downloading them, which produces a collection useful for language model pretraining. The dataset and tools published with this paper offer researchers the opportunity to develop even better multilingual language models.
STable: Table Generation Framework for Encoder-Decoder Models
Jun 08, 2022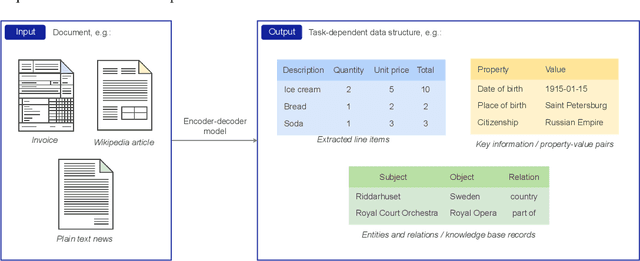
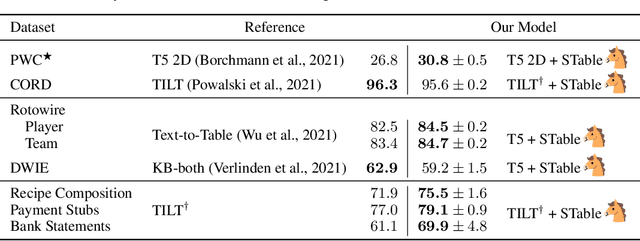
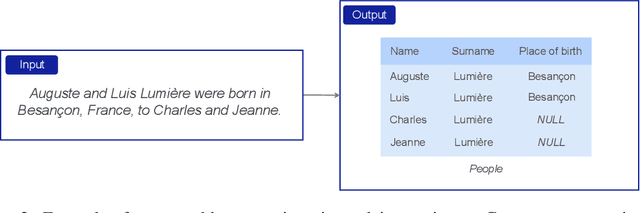
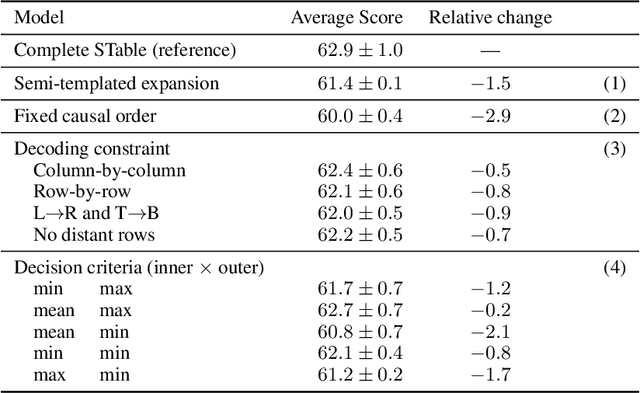
The output structure of database-like tables, consisting of values structured in horizontal rows and vertical columns identifiable by name, can cover a wide range of NLP tasks. Following this constatation, we propose a framework for text-to-table neural models applicable to problems such as extraction of line items, joint entity and relation extraction, or knowledge base population. The permutation-based decoder of our proposal is a generalized sequential method that comprehends information from all cells in the table. The training maximizes the expected log-likelihood for a table's content across all random permutations of the factorization order. During the content inference, we exploit the model's ability to generate cells in any order by searching over possible orderings to maximize the model's confidence and avoid substantial error accumulation, which other sequential models are prone to. Experiments demonstrate a high practical value of the framework, which establishes state-of-the-art results on several challenging datasets, outperforming previous solutions by up to 15%.