 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Scene Generation and Planning: Driving with World Model via Unifying Vision and Motion Representation
Mar 16, 2026End-to-end autonomous driving aims to generate safe and plausible planning policies from raw sensor input. Driving world models have shown great potential in learning rich representations by predicting the future evolution of a driving scene. However, existing driving world models primarily focus on visual scene representation, and motion representation is not explicitly designed to be planner-shared and inheritable, leaving a schism between the optimization of visual scene generation and the requirements of precise motion planning. We present WorldDrive, a holistic framework that couples scene generation and real-time planning via unifying vision and motion representation. We first introduce a Trajectory-aware Driving World Model, which conditions on a trajectory vocabulary to enforce consistency between visual dynamics and motion intentions, enabling the generation of diverse and plausible future scenes conditioned on a specific trajectory. We transfer the vision and motion encoders to a downstream Multi-modal Planner, ensuring the driving policy operates on mature representations pre-optimized by scene generation. A simple interaction between motion representation, visual representation, and ego status can generate high-quality, multi-modal trajectories. Furthermore, to exploit the world model's foresight, we propose a Future-aware Rewarder, which distills future latent representation from the frozen world model to evaluate and select optimal trajectories in real-time. Extensive experiments on the NAVSIM, NAVSIM-v2, and nuScenes benchmarks demonstrate that WorldDrive achieves leading planning performance among vision-only methods while maintaining high-fidelity action-controlled video generation capabilities, providing strong evidence for the effectiveness of unifying vision and motion representation for robust autonomous driving.
CLAIM: Camera-LiDAR Alignment with Intensity and Monodepth
Dec 16, 2025In this paper, we unleash the potential of the powerful monodepth model in camera-LiDAR calibration and propose CLAIM, a novel method of aligning data from the camera and LiDAR. Given the initial guess and pairs of images and LiDAR point clouds, CLAIM utilizes a coarse-to-fine searching method to find the optimal transformation minimizing a patched Pearson correlation-based structure loss and a mutual information-based texture loss. These two losses serve as good metrics for camera-LiDAR alignment results and require no complicated steps of data processing, feature extraction, or feature matching like most methods, rendering our method simple and adaptive to most scenes. We validate CLAIM on public KITTI, Waymo, and MIAS-LCEC datasets, and the experimental results demonstrate its superior performance compared with the state-of-the-art methods. The code is available at https://github.com/Tompson11/claim.
Regional Semantic Contrast and Aggregation for Weakly Supervised Semantic Segmentation
Mar 22, 2022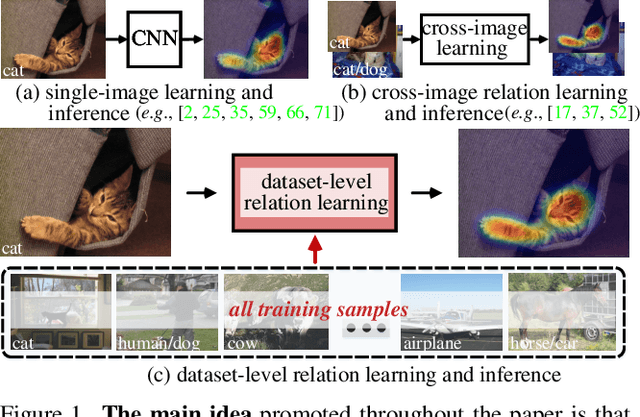
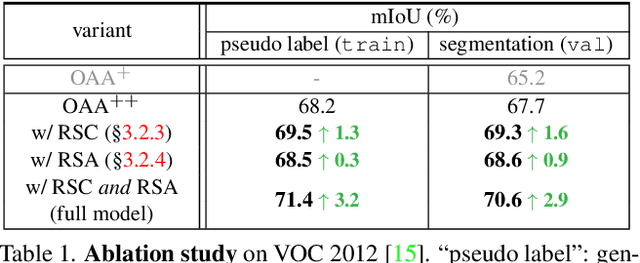
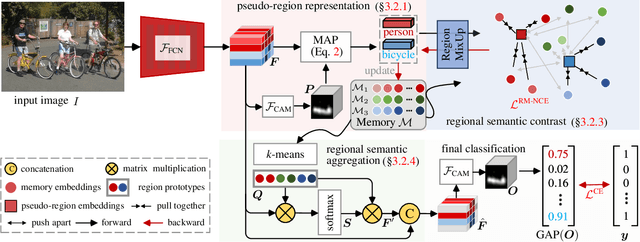
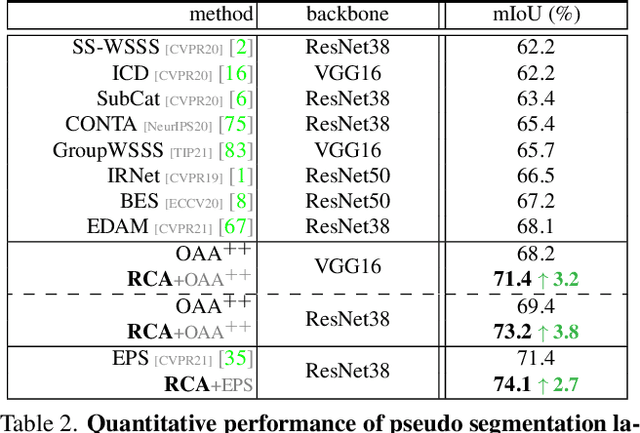
Learning semantic segmentation from weakly-labeled (e.g., image tags only) data is challenging since it is hard to infer dense object regions from sparse semantic tags. Despite being broadly studied, most current efforts directly learn from limited semantic annotations carried by individual image or image pairs, and struggle to obtain integral localization maps. Our work alleviates this from a novel perspective, by exploring rich semantic contexts synergistically among abundant weakly-labeled training data for network learning and inference. In particular, we propose regional semantic contrast and aggregation (RCA) . RCA is equipped with a regional memory bank to store massive, diverse object patterns appearing in training data, which acts as strong support for exploration of dataset-level semantic structure. Particularly, we propose i) semantic contrast to drive network learning by contrasting massive categorical object regions, leading to a more holistic object pattern understanding, and ii) semantic aggregation to gather diverse relational contexts in the memory to enrich semantic representations. In this manner, RCA earns a strong capability of fine-grained semantic understanding, and eventually establishes new state-of-the-art results on two popular benchmarks, i.e., PASCAL VOC 2012 and COCO 2014.