 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-free online learning via model selection
Jan 03, 2018We introduce an efficient algorithmic framework for model selection in online learning, also known as parameter-free online learning. Departing from previous work, which has focused on highly structured function classes such as nested balls in Hilbert space, we propose a generic meta-algorithm framework that achieves online model selection oracle inequalities under minimal structural assumptions. We give the first computationally efficient parameter-free algorithms that work in arbitrary Banach spaces under mild smoothness assumptions; previous results applied only to Hilbert spaces. We further derive new oracle inequalities for matrix classes, non-nested convex sets, and $\mathbb{R}^{d}$ with generic regularizers. Finally, we generalize these results by providing oracle inequalities for arbitrary non-linear classes in the online supervised learning model. These results are all derived through a unified meta-algorithm scheme using a novel "multi-scale" algorithm for prediction with expert advice based on random playout, which may be of independent interest.
Multiple-Source Adaptation for Regression Problems
Nov 14, 2017

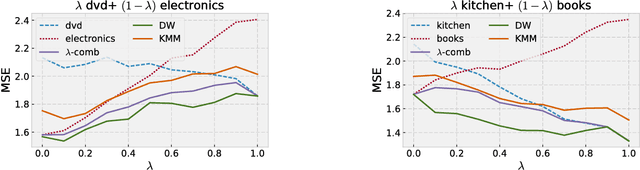
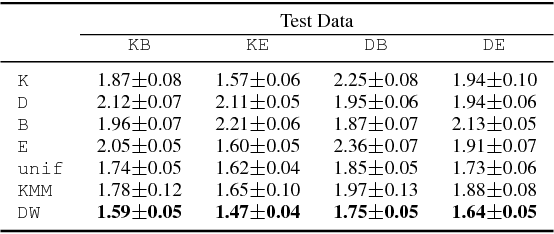
We present a detailed theoretical analysis of the problem of multiple-source adaptation in the general stochastic scenario, extending known results that assume a single target labeling function. Our results cover a more realistic scenario and show the existence of a single robust predictor accurate for \emph{any} target mixture of the source distributions. Moreover, we present an efficient and practical optimization solution to determine the robust predictor in the important case of squared loss, by casting the problem as an instance of DC-programming. We report the results of experiments with both an artificial task and a sentiment analysis task. We find that our algorithm outperforms competing approaches by producing a single robust model that performs well on any target mixture distribution.
Online Learning with Automata-based Expert Sequences
Oct 22, 2017



We consider a general framework of online learning with expert advice where regret is defined with respect to sequences of experts accepted by a weighted automaton. Our framework covers several problems previously studied, including competing against k-shifting experts. We give a series of algorithms for this problem, including an automata-based algorithm extending weighted-majority and more efficient algorithms based on the notion of failure transitions. We further present efficient algorithms based on an approximation of the competitor automaton, in particular n-gram models obtained by minimizing the \infty-R\'{e}nyi divergence, and present an extensive study of the approximation properties of such models. Finally, we also extend our algorithms and results to the framework of sleeping experts.
AdaNet: Adaptive Structural Learning of Artificial Neural Networks
Feb 28, 2017
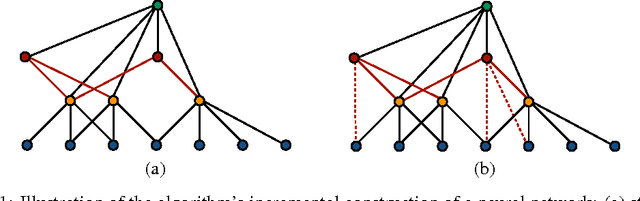

We present new algorithms for adaptively learning artificial neural networks. Our algorithms (AdaNet) adaptively learn both the structure of the network and its weights. They are based on a solid theoretical analysis, including data-dependent generalization guarantees that we prove and discuss in detail. We report the results of large-scale experiments with one of our algorithms on several binary classification tasks extracted from the CIFAR-10 dataset. The results demonstrate that our algorithm can automatically learn network structures with very competitive performance accuracies when compared with those achieved for neural networks found by standard approaches.
Structured Prediction Theory Based on Factor Graph Complexity
Dec 01, 2016
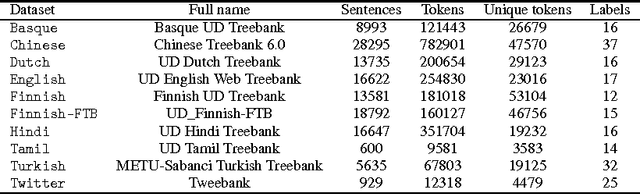
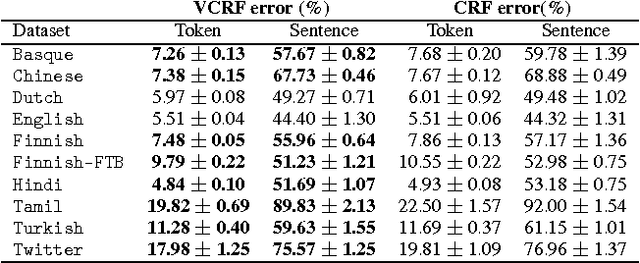
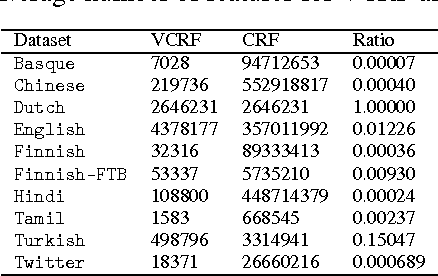
We present a general theoretical analysis of structured prediction with a series of new results. We give new data-dependent margin guarantees for structured prediction for a very wide family of loss functions and a general family of hypotheses, with an arbitrary factor graph decomposition. These are the tightest margin bounds known for both standard multi-class and general structured prediction problems. Our guarantees are expressed in terms of a data-dependent complexity measure, factor graph complexity, which we show can be estimated from data and bounded in terms of familiar quantities. We further extend our theory by leveraging the principle of Voted Risk Minimization (VRM) and show that learning is possible even with complex factor graphs. We present new learning bounds for this advanced setting, which we use to design two new algorithms, Voted Conditional Random Field (VCRF) and Voted Structured Boosting (StructBoost). These algorithms can make use of complex features and factor graphs and yet benefit from favorable learning guarantees. We also report the results of experiments with VCRF on several datasets to validate our theory.
Generalization Bounds for Weighted Automata
Oct 25, 2016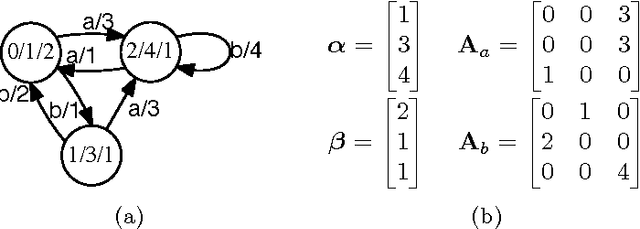
This paper studies the problem of learning weighted automata from a finite labeled training sample. We consider several general families of weighted automata defined in terms of three different measures: the norm of an automaton's weights, the norm of the function computed by an automaton, or the norm of the corresponding Hankel matrix. We present new data-dependent generalization guarantees for learning weighted automata expressed in terms of the Rademacher complexity of these families. We further present upper bounds on these Rademacher complexities, which reveal key new data-dependent terms related to the complexity of learning weighted automata.
Relative Deviation Learning Bounds and Generalization with Unbounded Loss Functions
Apr 04, 2016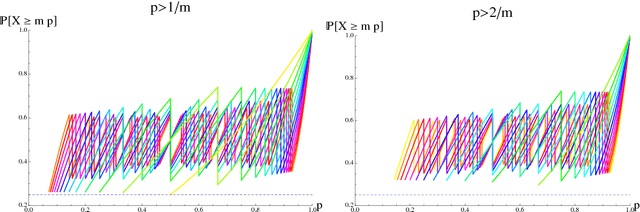
We present an extensive analysis of relative deviation bounds, including detailed proofs of two-sided inequalities and their implications. We also give detailed proofs of two-sided generalization bounds that hold in the general case of unbounded loss functions, under the assumption that a moment of the loss is bounded. These bounds are useful in the analysis of importance weighting and other learning tasks such as unbounded regression.
Foundations of Coupled Nonlinear Dimensionality Reduction
Nov 25, 2015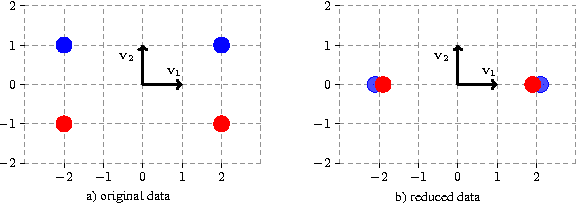
In this paper we introduce and analyze the learning scenario of \emph{coupled nonlinear dimensionality reduction}, which combines two major steps of machine learning pipeline: projection onto a manifold and subsequent supervised learning. First, we present new generalization bounds for this scenario and, second, we introduce an algorithm that follows from these bounds. The generalization error bound is based on a careful analysis of the empirical Rademacher complexity of the relevant hypothesis set. In particular, we show an upper bound on the Rademacher complexity that is in $\widetilde O(\sqrt{\Lambda_{(r)}/m})$, where $m$ is the sample size and $\Lambda_{(r)}$ the upper bound on the Ky-Fan $r$-norm of the associated kernel matrix. We give both upper and lower bound guarantees in terms of that Ky-Fan $r$-norm, which strongly justifies the definition of our hypothesis set. To the best of our knowledge, these are the first learning guarantees for the problem of coupled dimensionality reduction. Our analysis and learning guarantees further apply to several special cases, such as that of using a fixed kernel with supervised dimensionality reduction or that of unsupervised learning of a kernel for dimensionality reduction followed by a supervised learning algorithm. Based on theoretical analysis, we suggest a structural risk minimization algorithm consisting of the coupled fitting of a low dimensional manifold and a separation function on that manifold.
Accelerating Optimization via Adaptive Prediction
Oct 13, 2015We present a powerful general framework for designing data-dependent optimization algorithms, building upon and unifying recent techniques in adaptive regularization, optimistic gradient predictions, and problem-dependent randomization. We first present a series of new regret guarantees that hold at any time and under very minimal assumptions, and then show how different relaxations recover existing algorithms, both basic as well as more recent sophisticated ones. Finally, we show how combining adaptivity, optimism, and problem-dependent randomization can guide the design of algorithms that benefit from more favorable guarantees than recent state-of-the-art methods.
Voted Kernel Regularization
Sep 14, 2015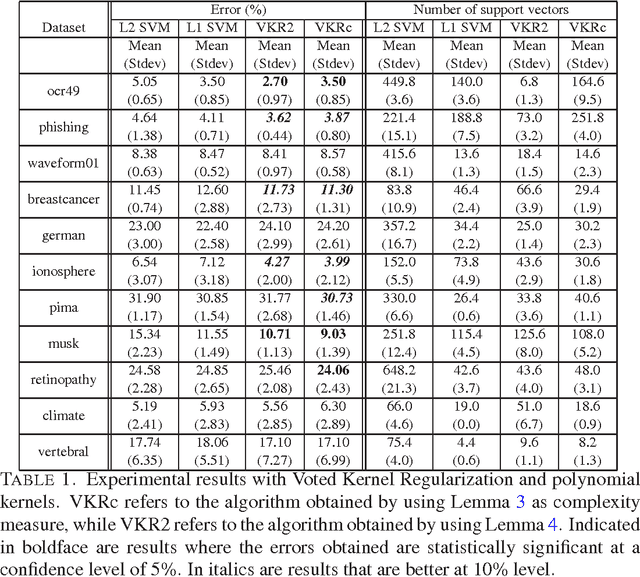
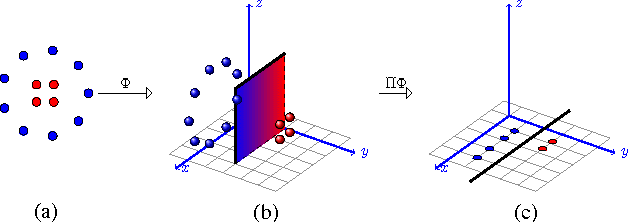
This paper presents an algorithm, Voted Kernel Regularization , that provides the flexibility of using potentially very complex kernel functions such as predictors based on much higher-degree polynomial kernels, while benefitting from strong learning guarantees. The success of our algorithm arises from derived bounds that suggest a new regularization penalty in terms of the Rademacher complexities of the corresponding families of kernel maps. In a series of experiments we demonstrate the improved performance of our algorithm as compared to baselines. Furthermore, the algorithm enjoys several favorable properties. The optimization problem is convex, it allows for learning with non-PDS kernels, and the solutions are highly sparse, resulting in improved classification speed and memory requirements.