 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking a MIRACL: Multilingual Information Retrieval Across a Continuum of Languages
Oct 18, 2022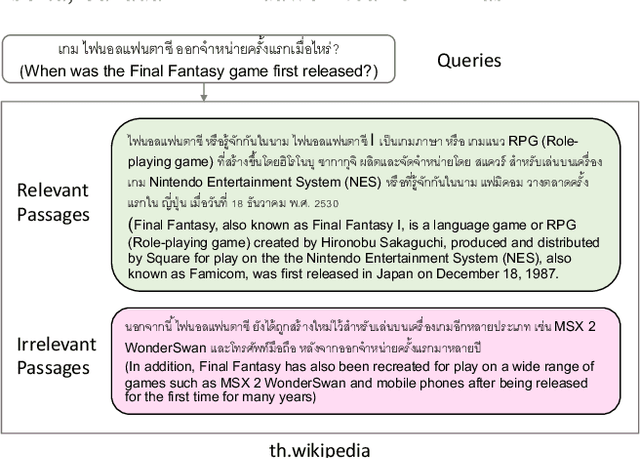
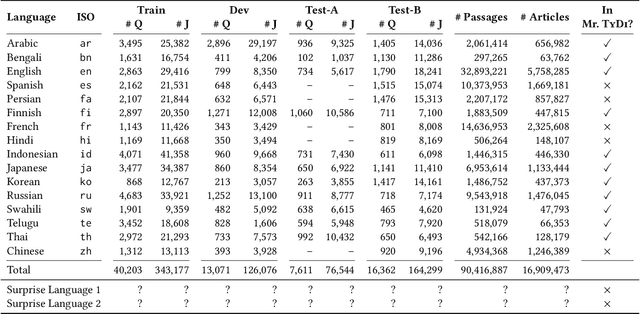
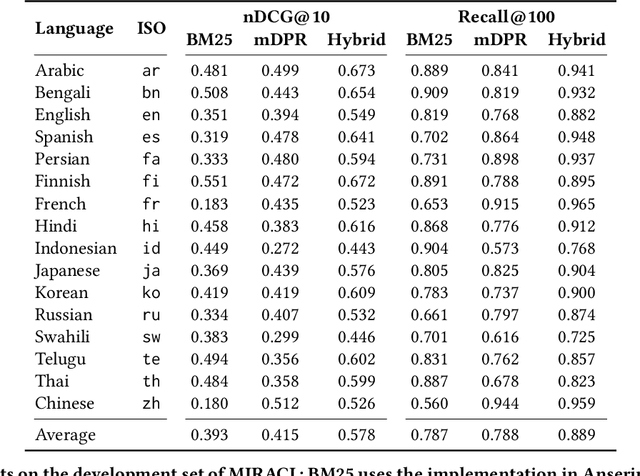
MIRACL (Multilingual Information Retrieval Across a Continuum of Languages) is a multilingual dataset we have built for the WSDM 2023 Cup challenge that focuses on ad hoc retrieval across 18 different languages, which collectively encompass over three billion native speakers around the world. These languages have diverse typologies, originate from many different language families, and are associated with varying amounts of available resources -- including what researchers typically characterize as high-resource as well as low-resource languages. Our dataset is designed to support the creation and evaluation of models for monolingual retrieval, where the queries and the corpora are in the same language. In total, we have gathered over 700k high-quality relevance judgments for around 77k queries over Wikipedia in these 18 languages, where all assessments have been performed by native speakers hired by our team. Our goal is to spur research that will improve retrieval across a continuum of languages, thus enhancing information access capabilities for diverse populations around the world, particularly those that have been traditionally underserved. This overview paper describes the dataset and baselines that we share with the community. The MIRACL website is live at http://miracl.ai/.
DyLoRA: Parameter Efficient Tuning of Pre-trained Models using Dynamic Search-Free Low-Rank Adaptation
Oct 14, 2022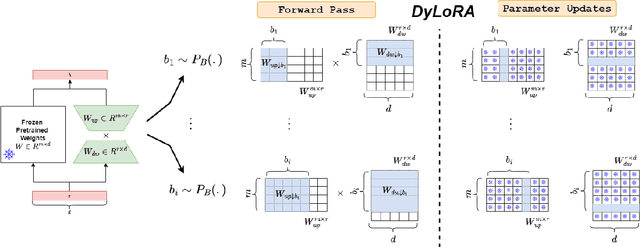
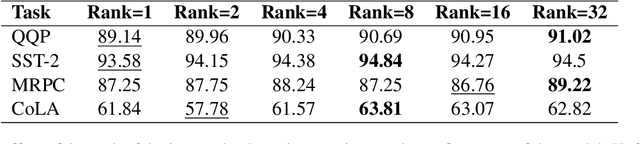

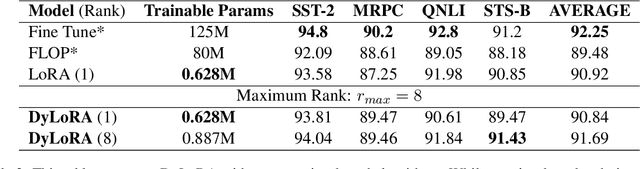
With the ever-growing size of pre-trained models (PMs), fine-tuning them has become more expensive and resource-hungry. As a remedy, low-rank adapters (LoRA) keep the main pre-trained weights of the model frozen and just introduce some learnable truncated SVD modules (so-called LoRA blocks) to the model. While LoRA blocks are parameter efficient, they suffer from two major problems: first, the size of these blocks is fixed and cannot be modified after training (for example, if we need to change the rank of LoRA blocks, then we need to re-train them from scratch); second, optimizing their rank requires an exhaustive search and effort. In this work, we introduce a dynamic low-rank adaptation (DyLoRA) technique to address these two problems together. Our DyLoRA method trains LoRA blocks for a range of ranks instead of a single rank by sorting out the representation learned by the adapter module at different ranks during training. We evaluate our solution on different tasks of the GLUE benchmark using the RoBERTa model. Our results show that we can train dynamic search-free models with DyLoRA at least $7\times$ faster than LoRA without significantly compromising performance. Moreover, our models can perform consistently well on a much larger range of ranks compared to LoRA.
Integer Fine-tuning of Transformer-based Models
Sep 20, 2022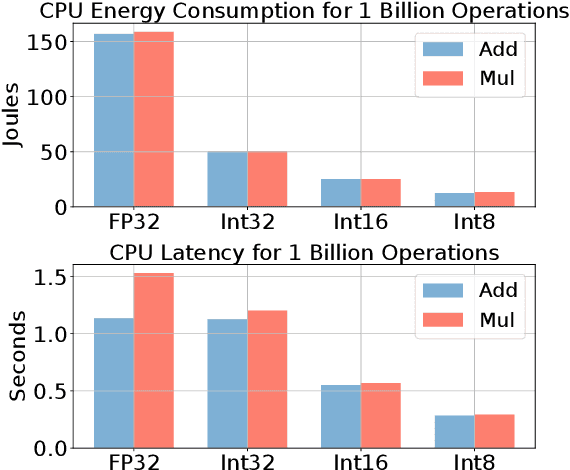
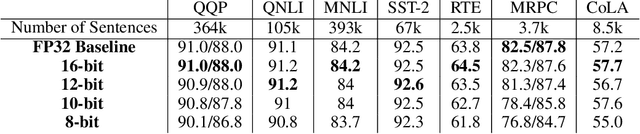
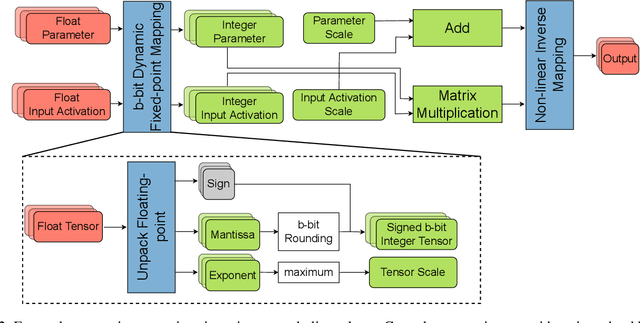
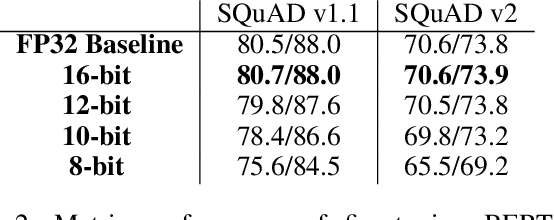
Transformer based models are used to achieve state-of-the-art performance on various deep learning tasks. Since transformer-based models have large numbers of parameters, fine-tuning them on downstream tasks is computationally intensive and energy hungry. Automatic mixed-precision FP32/FP16 fine-tuning of such models has been previously used to lower the compute resource requirements. However, with the recent advances in the low-bit integer back-propagation, it is possible to further reduce the computation and memory foot-print. In this work, we explore a novel integer training method that uses integer arithmetic for both forward propagation and gradient computation of linear, convolutional, layer-norm, and embedding layers in transformer-based models. Furthermore, we study the effect of various integer bit-widths to find the minimum required bit-width for integer fine-tuning of transformer-based models. We fine-tune BERT and ViT models on popular downstream tasks using integer layers. We show that 16-bit integer models match the floating-point baseline performance. Reducing the bit-width to 10, we observe 0.5 average score drop. Finally, further reduction of the bit-width to 8 provides an average score drop of 1.7 points.
Learning Functions on Multiple Sets using Multi-Set Transformers
Jun 30, 2022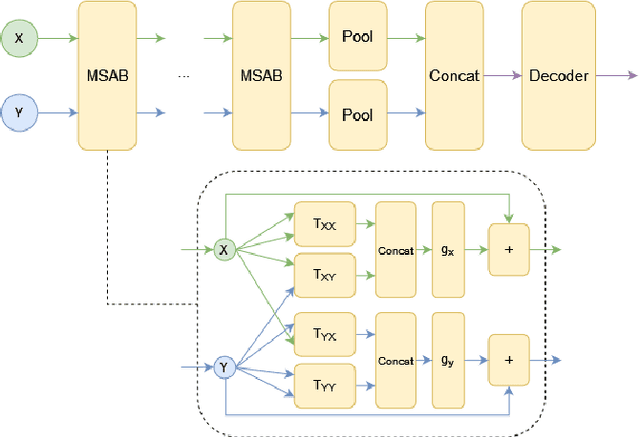
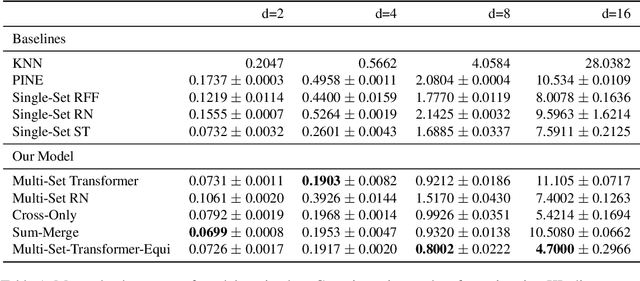
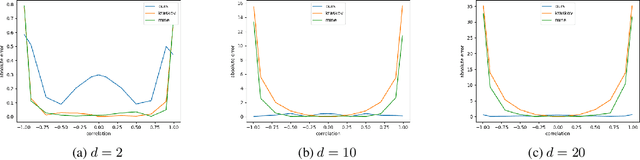
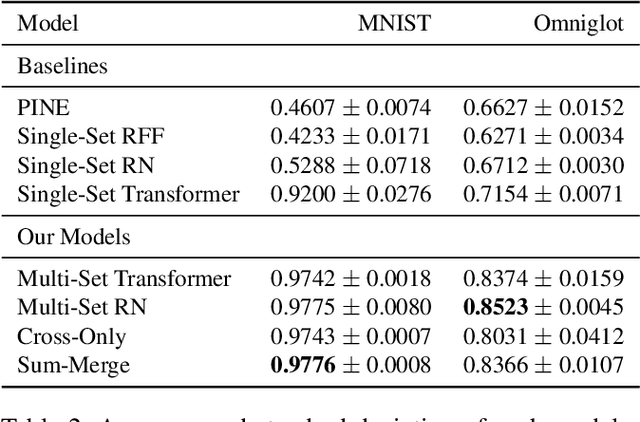
We propose a general deep architecture for learning functions on multiple permutation-invariant sets. We also show how to generalize this architecture to sets of elements of any dimension by dimension equivariance. We demonstrate that our architecture is a universal approximator of these functions, and show superior results to existing methods on a variety of tasks including counting tasks, alignment tasks, distinguishability tasks and statistical distance measurements. This last task is quite important in Machine Learning. Although our approach is quite general, we demonstrate that it can generate approximate estimates of KL divergence and mutual information that are more accurate than previous techniques that are specifically designed to approximate those statistical distances.
Towards Understanding Label Regularization for Fine-tuning Pre-trained Language Models
May 25, 2022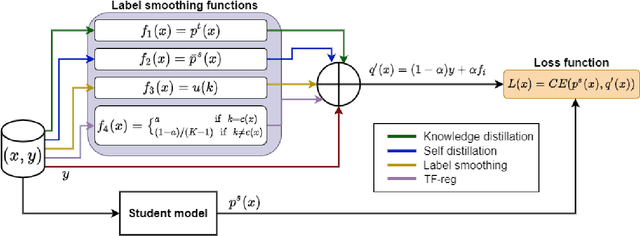
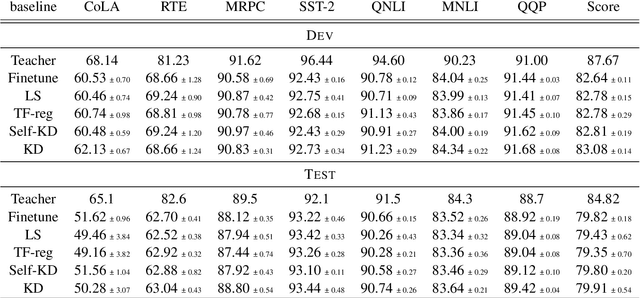
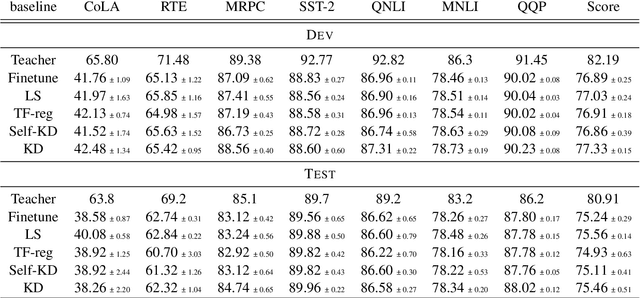
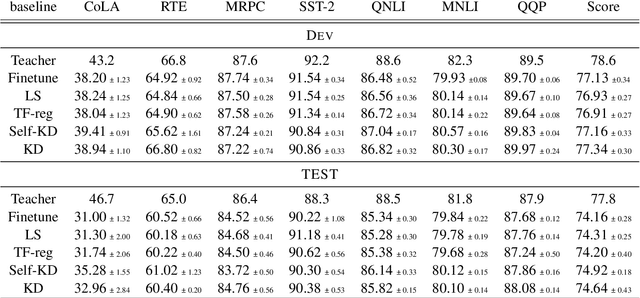
Knowledge Distillation (KD) is a prominent neural model compression technique which heavily relies on teacher network predictions to guide the training of a student model. Considering the ever-growing size of pre-trained language models (PLMs), KD is often adopted in many NLP tasks involving PLMs. However, it is evident that in KD, deploying the teacher network during training adds to the memory and computational requirements of training. In the computer vision literature, the necessity of the teacher network is put under scrutiny by showing that KD is a label regularization technique that can be replaced with lighter teacher-free variants such as the label-smoothing technique. However, to the best of our knowledge, this issue is not investigated in NLP. Therefore, this work concerns studying different label regularization techniques and whether we actually need the teacher labels to fine-tune smaller PLM student networks on downstream tasks. In this regard, we did a comprehensive set of experiments on different PLMs such as BERT, RoBERTa, and GPT with more than 600 distinct trials and ran each configuration five times. This investigation led to a surprising observation that KD and other label regularization techniques do not play any meaningful role over regular fine-tuning when the student model is pre-trained. We further explore this phenomenon in different settings of NLP and computer vision tasks and demonstrate that pre-training itself acts as a kind of regularization, and additional label regularization is unnecessary.
Revisiting Pre-trained Language Models and their Evaluation for Arabic Natural Language Understanding
May 21, 2022
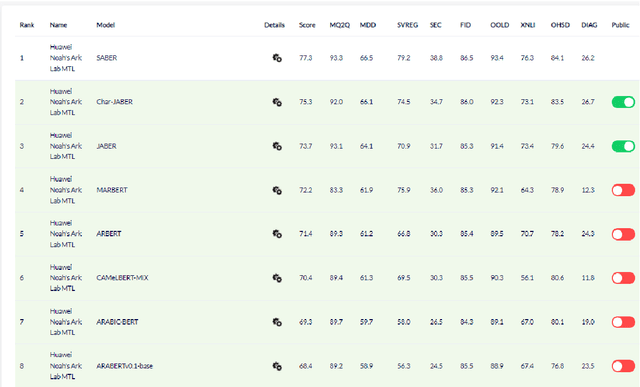
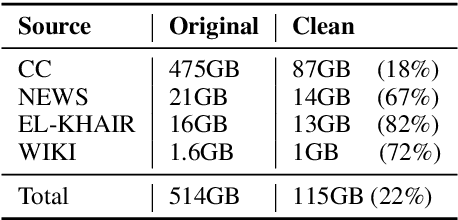
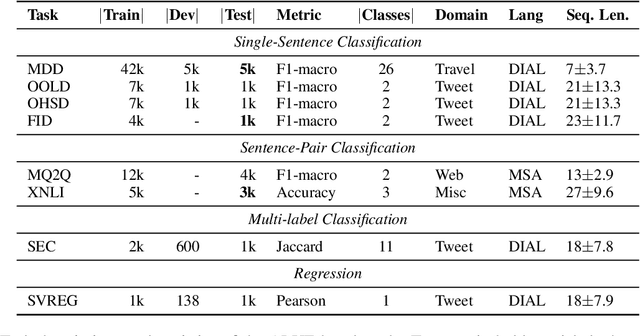
There is a growing body of work in recent years to develop pre-trained language models (PLMs) for the Arabic language. This work concerns addressing two major problems in existing Arabic PLMs which constraint progress of the Arabic NLU and NLG fields.First, existing Arabic PLMs are not well-explored and their pre-trainig can be improved significantly using a more methodical approach. Second, there is a lack of systematic and reproducible evaluation of these models in the literature. In this work, we revisit both the pre-training and evaluation of Arabic PLMs. In terms of pre-training, we explore improving Arabic LMs from three perspectives: quality of the pre-training data, size of the model, and incorporating character-level information. As a result, we release three new Arabic BERT-style models ( JABER, Char-JABER, and SABER), and two T5-style models (AT5S and AT5B). In terms of evaluation, we conduct a comprehensive empirical study to systematically evaluate the performance of existing state-of-the-art models on ALUE that is a leaderboard-powered benchmark for Arabic NLU tasks, and on a subset of the ARGEN benchmark for Arabic NLG tasks. We show that our models significantly outperform existing Arabic PLMs and achieve a new state-of-the-art performance on discriminative and generative Arabic NLU and NLG tasks. Our models and source code to reproduce of results will be made available shortly.
Dynamic Position Encoding for Transformers
Apr 18, 2022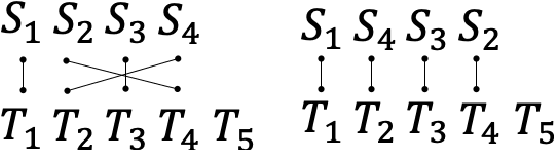
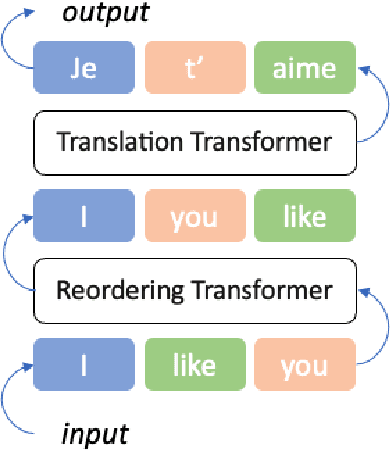

Recurrent models have been dominating the field of neural machine translation (NMT) for the past few years. Transformers \citep{vaswani2017attention}, have radically changed it by proposing a novel architecture that relies on a feed-forward backbone and self-attention mechanism. Although Transformers are powerful, they could fail to properly encode sequential/positional information due to their non-recurrent nature. To solve this problem, position embeddings are defined exclusively for each time step to enrich word information. However, such embeddings are fixed after training regardless of the task and the word ordering system of the source or target language. In this paper, we propose a novel architecture with new position embeddings depending on the input text to address this shortcoming by taking the order of target words into consideration. Instead of using predefined position embeddings, our solution \textit{generates} new embeddings to refine each word's position information. Since we do not dictate the position of source tokens and learn them in an end-to-end fashion, we refer to our method as \textit{dynamic} position encoding (DPE). We evaluated the impact of our model on multiple datasets to translate from English into German, French, and Italian and observed meaningful improvements in comparison to the original Transformer.
CILDA: Contrastive Data Augmentation using Intermediate Layer Knowledge Distillation
Apr 15, 2022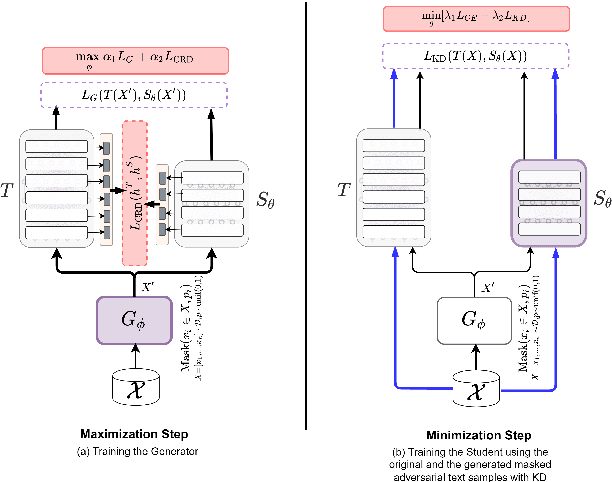
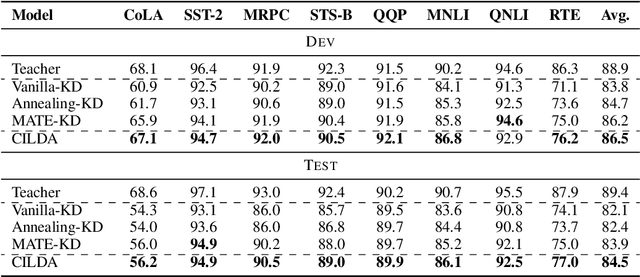
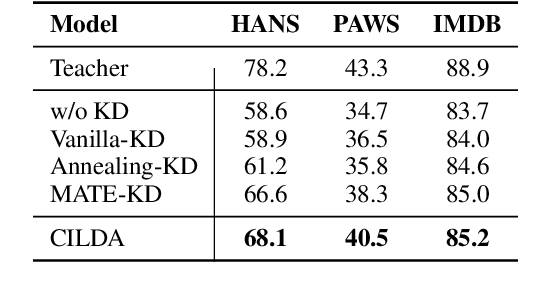
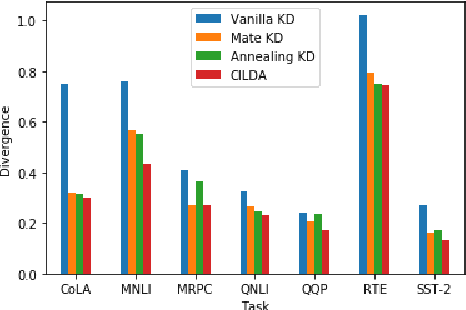
Knowledge distillation (KD) is an efficient framework for compressing large-scale pre-trained language models. Recent years have seen a surge of research aiming to improve KD by leveraging Contrastive Learning, Intermediate Layer Distillation, Data Augmentation, and Adversarial Training. In this work, we propose a learning based data augmentation technique tailored for knowledge distillation, called CILDA. To the best of our knowledge, this is the first time that intermediate layer representations of the main task are used in improving the quality of augmented samples. More precisely, we introduce an augmentation technique for KD based on intermediate layer matching using contrastive loss to improve masked adversarial data augmentation. CILDA outperforms existing state-of-the-art KD approaches on the GLUE benchmark, as well as in an out-of-domain evaluation.
When Chosen Wisely, More Data Is What You Need: A Universal Sample-Efficient Strategy For Data Augmentation
Mar 17, 2022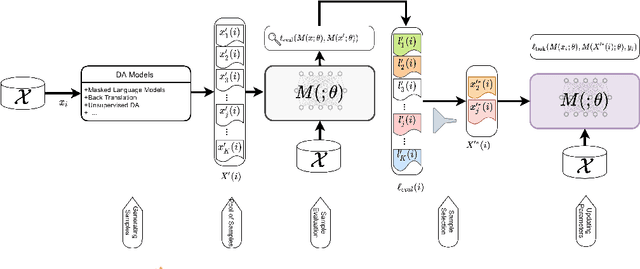
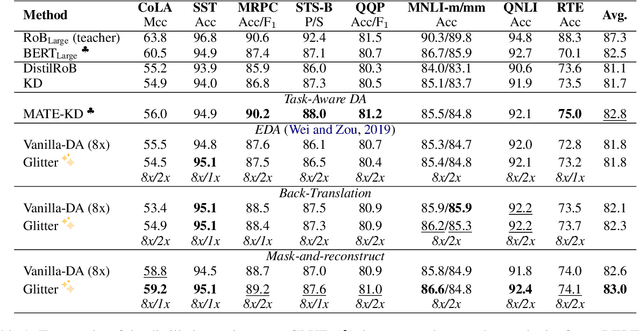
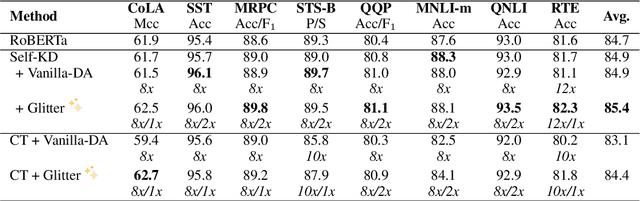

Data Augmentation (DA) is known to improve the generalizability of deep neural networks. Most existing DA techniques naively add a certain number of augmented samples without considering the quality and the added computational cost of these samples. To tackle this problem, a common strategy, adopted by several state-of-the-art DA methods, is to adaptively generate or re-weight augmented samples with respect to the task objective during training. However, these adaptive DA methods: (1) are computationally expensive and not sample-efficient, and (2) are designed merely for a specific setting. In this work, we present a universal DA technique, called Glitter, to overcome both issues. Glitter can be plugged into any DA method, making training sample-efficient without sacrificing performance. From a pre-generated pool of augmented samples, Glitter adaptively selects a subset of worst-case samples with maximal loss, analogous to adversarial DA. Without altering the training strategy, the task objective can be optimized on the selected subset. Our thorough experiments on the GLUE benchmark, SQuAD, and HellaSwag in three widely used training setups including consistency training, self-distillation and knowledge distillation reveal that Glitter is substantially faster to train and achieves a competitive performance, compared to strong baselines.
JABER and SABER: Junior and Senior Arabic BERt
Jan 09, 2022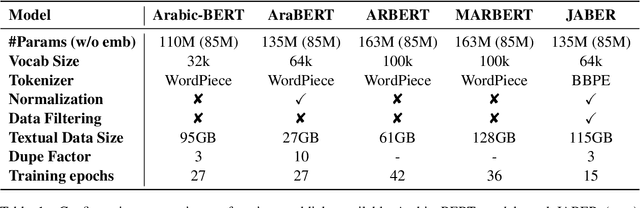
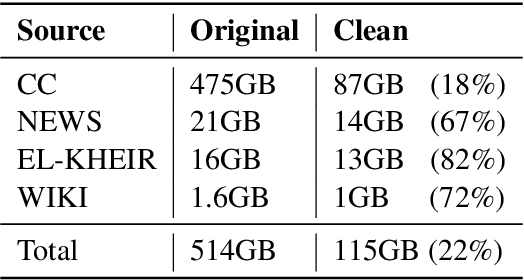
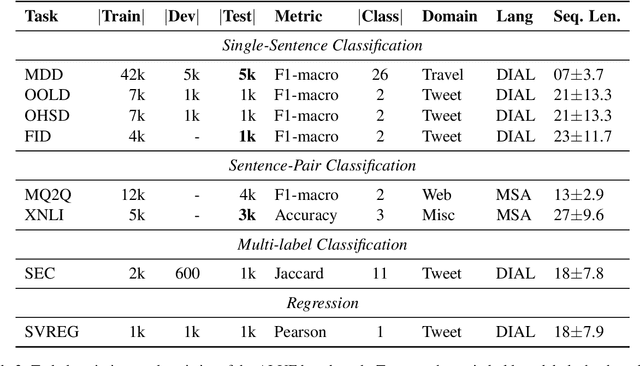
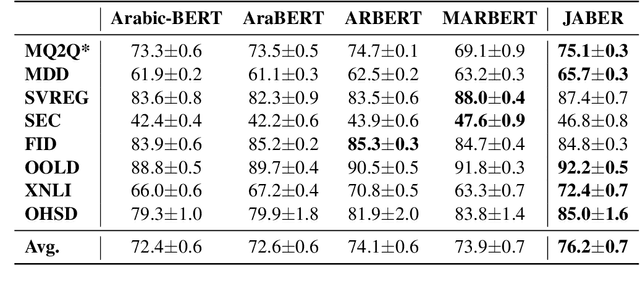
Language-specific pre-trained models have proven to be more accurate than multilingual ones in a monolingual evaluation setting, Arabic is no exception. However, we found that previously released Arabic BERT models were significantly under-trained. In this technical report, we present JABER and SABER, Junior and Senior Arabic BERt respectively, our pre-trained language model prototypes dedicated for Arabic. We conduct an empirical study to systematically evaluate the performance of models across a diverse set of existing Arabic NLU tasks. Experimental results show that JABER and SABER achieve state-of-the-art performances on ALUE, a new benchmark for Arabic Language Understanding Evaluation, as well as on a well-established NER benchmark.