 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Flip Reasoning in Multiparty Conversations
Jun 24, 2023



In a conversational dialogue, speakers may have different emotional states and their dynamics play an important role in understanding dialogue's emotional discourse. However, simply detecting emotions is not sufficient to entirely comprehend the speaker-specific changes in emotion that occur during a conversation. To understand the emotional dynamics of speakers in an efficient manner, it is imperative to identify the rationale or instigator behind any changes or flips in emotion expressed by the speaker. In this paper, we explore the task called Instigator based Emotion Flip Reasoning (EFR), which aims to identify the instigator behind a speaker's emotion flip within a conversation. For example, an emotion flip from joy to anger could be caused by an instigator like threat. To facilitate this task, we present MELD-I, a dataset that includes ground-truth EFR instigator labels, which are in line with emotional psychology. To evaluate the dataset, we propose a novel neural architecture called TGIF, which leverages Transformer encoders and stacked GRUs to capture the dialogue context, speaker dynamics, and emotion sequence in a conversation. Our evaluation demonstrates state-of-the-art performance (+4-12% increase in F1-score) against five baselines used for the task. Further, we establish the generalizability of TGIF on an unseen dataset in a zero-shot setting. Additionally, we provide a detailed analysis of the competing models, highlighting the advantages and limitations of our neural architecture.
Speaker Profiling in Multiparty Conversations
Apr 19, 2023In conversational settings, individuals exhibit unique behaviors, rendering a one-size-fits-all approach insufficient for generating responses by dialogue agents. Although past studies have aimed to create personalized dialogue agents using speaker persona information, they have relied on the assumption that the speaker's persona is already provided. However, this assumption is not always valid, especially when it comes to chatbots utilized in industries like banking, hotel reservations, and airline bookings. This research paper aims to fill this gap by exploring the task of Speaker Profiling in Conversations (SPC). The primary objective of SPC is to produce a summary of persona characteristics for each individual speaker present in a dialogue. To accomplish this, we have divided the task into three subtasks: persona discovery, persona-type identification, and persona-value extraction. Given a dialogue, the first subtask aims to identify all utterances that contain persona information. Subsequently, the second task evaluates these utterances to identify the type of persona information they contain, while the third subtask identifies the specific persona values for each identified type. To address the task of SPC, we have curated a new dataset named SPICE, which comes with specific labels. We have evaluated various baselines on this dataset and benchmarked it with a new neural model, SPOT, which we introduce in this paper. Furthermore, we present a comprehensive analysis of SPOT, examining the limitations of individual modules both quantitatively and qualitatively.
Explaining (Sarcastic) Utterances to Enhance Affect Understanding in Multimodal Dialogues
Nov 22, 2022Conversations emerge as the primary media for exchanging ideas and conceptions. From the listener's perspective, identifying various affective qualities, such as sarcasm, humour, and emotions, is paramount for comprehending the true connotation of the emitted utterance. However, one of the major hurdles faced in learning these affect dimensions is the presence of figurative language, viz. irony, metaphor, or sarcasm. We hypothesize that any detection system constituting the exhaustive and explicit presentation of the emitted utterance would improve the overall comprehension of the dialogue. To this end, we explore the task of Sarcasm Explanation in Dialogues, which aims to unfold the hidden irony behind sarcastic utterances. We propose MOSES, a deep neural network, which takes a multimodal (sarcastic) dialogue instance as an input and generates a natural language sentence as its explanation. Subsequently, we leverage the generated explanation for various natural language understanding tasks in a conversational dialogue setup, such as sarcasm detection, humour identification, and emotion recognition. Our evaluation shows that MOSES outperforms the state-of-the-art system for SED by an average of ~2% on different evaluation metrics, such as ROUGE, BLEU, and METEOR. Further, we observe that leveraging the generated explanation advances three downstream tasks for affect classification - an average improvement of ~14% F1-score in the sarcasm detection task and ~2% in the humour identification and emotion recognition task. We also perform extensive analyses to assess the quality of the results.
Empowering the Fact-checkers! Automatic Identification of Claim Spans on Twitter
Oct 11, 2022
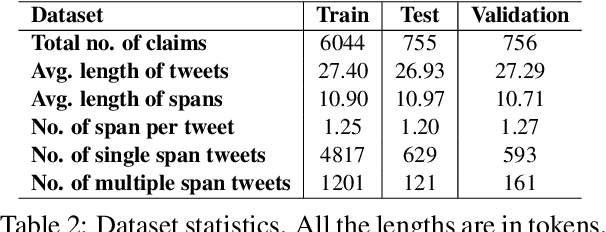
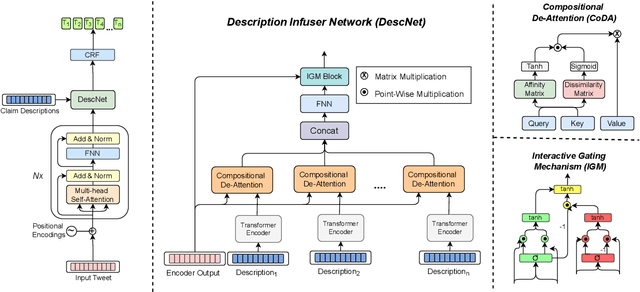
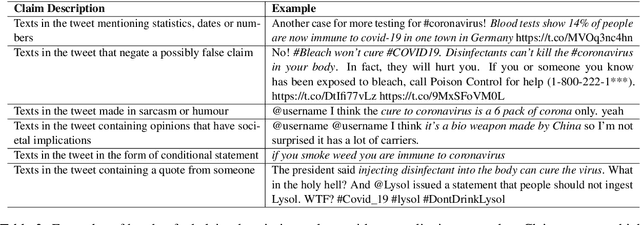
The widespread diffusion of medical and political claims in the wake of COVID-19 has led to a voluminous rise in misinformation and fake news. The current vogue is to employ manual fact-checkers to efficiently classify and verify such data to combat this avalanche of claim-ridden misinformation. However, the rate of information dissemination is such that it vastly outpaces the fact-checkers' strength. Therefore, to aid manual fact-checkers in eliminating the superfluous content, it becomes imperative to automatically identify and extract the snippets of claim-worthy (mis)information present in a post. In this work, we introduce the novel task of Claim Span Identification (CSI). We propose CURT, a large-scale Twitter corpus with token-level claim spans on more than 7.5k tweets. Furthermore, along with the standard token classification baselines, we benchmark our dataset with DABERTa, an adapter-based variation of RoBERTa. The experimental results attest that DABERTa outperforms the baseline systems across several evaluation metrics, improving by about 1.5 points. We also report detailed error analysis to validate the model's performance along with the ablation studies. Lastly, we release our comprehensive span annotation guidelines for public use.
Proactively Reducing the Hate Intensity of Online Posts via Hate Speech Normalization
Jun 08, 2022
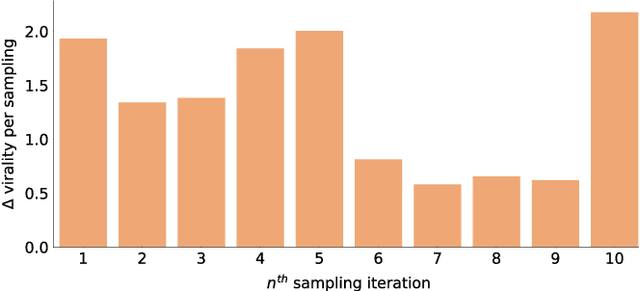
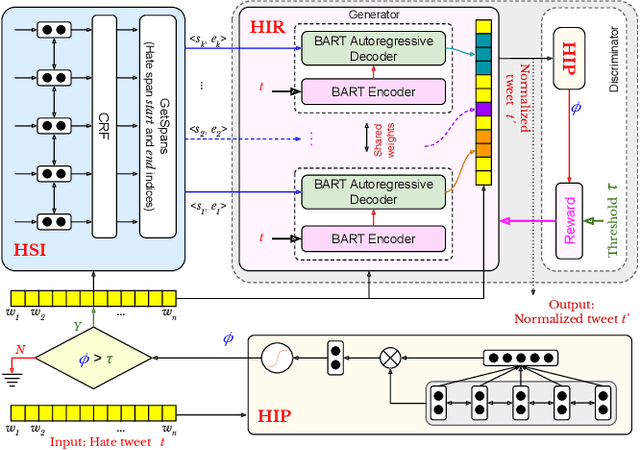
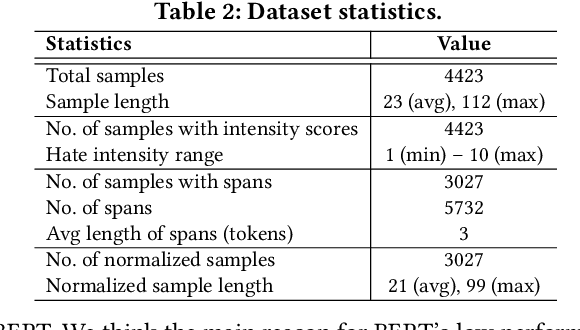
Curbing online hate speech has become the need of the hour; however, a blanket ban on such activities is infeasible for several geopolitical and cultural reasons. To reduce the severity of the problem, in this paper, we introduce a novel task, hate speech normalization, that aims to weaken the intensity of hatred exhibited by an online post. The intention of hate speech normalization is not to support hate but instead to provide the users with a stepping stone towards non-hate while giving online platforms more time to monitor any improvement in the user's behavior. To this end, we manually curated a parallel corpus - hate texts and their normalized counterparts (a normalized text is less hateful and more benign). We introduce NACL, a simple yet efficient hate speech normalization model that operates in three stages - first, it measures the hate intensity of the original sample; second, it identifies the hate span(s) within it; and finally, it reduces hate intensity by paraphrasing the hate spans. We perform extensive experiments to measure the efficacy of NACL via three-way evaluation (intrinsic, extrinsic, and human-study). We observe that NACL outperforms six baselines - NACL yields a score of 0.1365 RMSE for the intensity prediction, 0.622 F1-score in the span identification, and 82.27 BLEU and 80.05 perplexity for the normalized text generation. We further show the generalizability of NACL across other platforms (Reddit, Facebook, Gab). An interactive prototype of NACL was put together for the user study. Further, the tool is being deployed in a real-world setting at Wipro AI as a part of its mission to tackle harmful content on online platforms.
A Comprehensive Understanding of Code-mixed Language Semantics using Hierarchical Transformer
Apr 27, 2022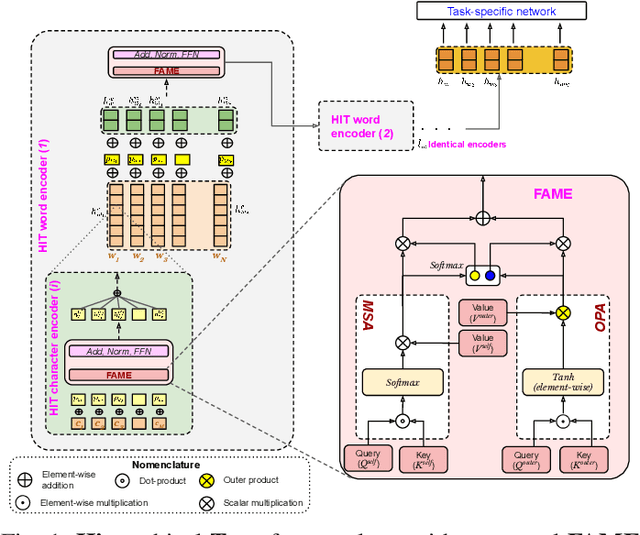

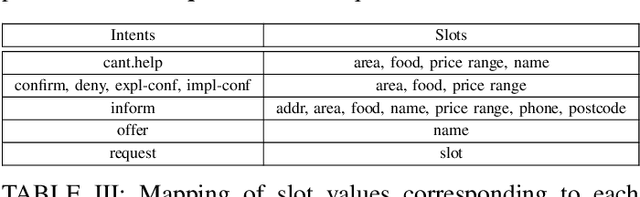
Being a popular mode of text-based communication in multilingual communities, code-mixing in online social media has became an important subject to study. Learning the semantics and morphology of code-mixed language remains a key challenge, due to scarcity of data and unavailability of robust and language-invariant representation learning technique. Any morphologically-rich language can benefit from character, subword, and word-level embeddings, aiding in learning meaningful correlations. In this paper, we explore a hierarchical transformer-based architecture (HIT) to learn the semantics of code-mixed languages. HIT consists of multi-headed self-attention and outer product attention components to simultaneously comprehend the semantic and syntactic structures of code-mixed texts. We evaluate the proposed method across 6 Indian languages (Bengali, Gujarati, Hindi, Tamil, Telugu and Malayalam) and Spanish for 9 NLP tasks on 17 datasets. The HIT model outperforms state-of-the-art code-mixed representation learning and multilingual language models in all tasks. We further demonstrate the generalizability of the HIT architecture using masked language modeling-based pre-training, zero-shot learning, and transfer learning approaches. Our empirical results show that the pre-training objectives significantly improve the performance on downstream tasks.
When did you become so smart, oh wise one?! Sarcasm Explanation in Multi-modal Multi-party Dialogues
Mar 12, 2022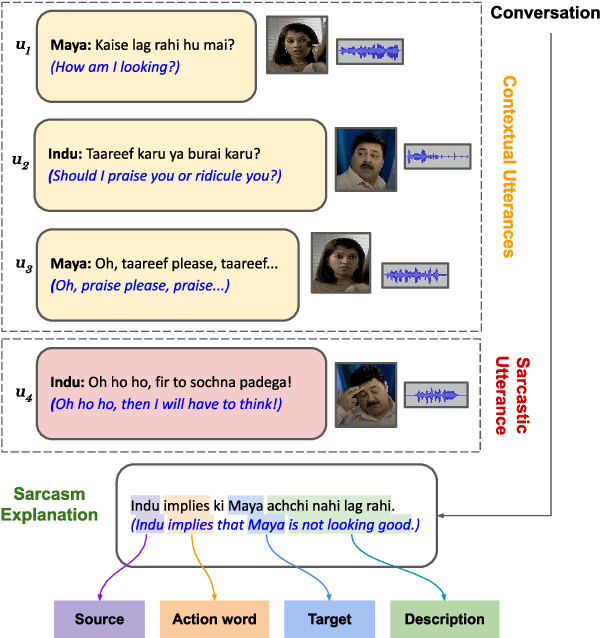
Indirect speech such as sarcasm achieves a constellation of discourse goals in human communication. While the indirectness of figurative language warrants speakers to achieve certain pragmatic goals, it is challenging for AI agents to comprehend such idiosyncrasies of human communication. Though sarcasm identification has been a well-explored topic in dialogue analysis, for conversational systems to truly grasp a conversation's innate meaning and generate appropriate responses, simply detecting sarcasm is not enough; it is vital to explain its underlying sarcastic connotation to capture its true essence. In this work, we study the discourse structure of sarcastic conversations and propose a novel task - Sarcasm Explanation in Dialogue (SED). Set in a multimodal and code-mixed setting, the task aims to generate natural language explanations of satirical conversations. To this end, we curate WITS, a new dataset to support our task. We propose MAF (Modality Aware Fusion), a multimodal context-aware attention and global information fusion module to capture multimodality and use it to benchmark WITS. The proposed attention module surpasses the traditional multimodal fusion baselines and reports the best performance on almost all metrics. Lastly, we carry out detailed analyses both quantitatively and qualitatively.
Nice perfume. How long did you marinate in it? Multimodal Sarcasm Explanation
Dec 09, 2021
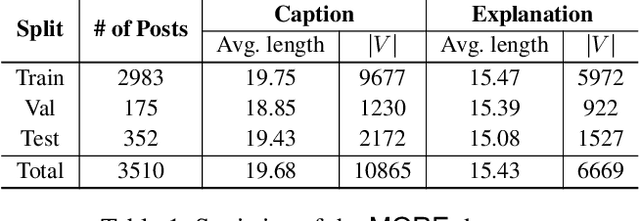

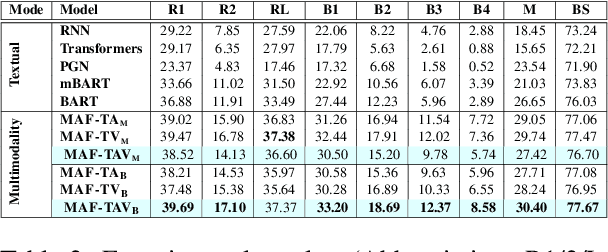
Sarcasm is a pervading linguistic phenomenon and highly challenging to explain due to its subjectivity, lack of context and deeply-felt opinion. In the multimodal setup, sarcasm is conveyed through the incongruity between the text and visual entities. Although recent approaches deal with sarcasm as a classification problem, it is unclear why an online post is identified as sarcastic. Without proper explanation, end users may not be able to perceive the underlying sense of irony. In this paper, we propose a novel problem -- Multimodal Sarcasm Explanation (MuSE) -- given a multimodal sarcastic post containing an image and a caption, we aim to generate a natural language explanation to reveal the intended sarcasm. To this end, we develop MORE, a new dataset with explanation of 3510 sarcastic multimodal posts. Each explanation is a natural language (English) sentence describing the hidden irony. We benchmark MORE by employing a multimodal Transformer-based architecture. It incorporates a cross-modal attention in the Transformer's encoder which attends to the distinguishing features between the two modalities. Subsequently, a BART-based auto-regressive decoder is used as the generator. Empirical results demonstrate convincing results over various baselines (adopted for MuSE) across five evaluation metrics. We also conduct human evaluation on predictions and obtain Fleiss' Kappa score of 0.4 as a fair agreement among 25 evaluators.
Speaker and Time-aware Joint Contextual Learning for Dialogue-act Classification in Counselling Conversations
Nov 12, 2021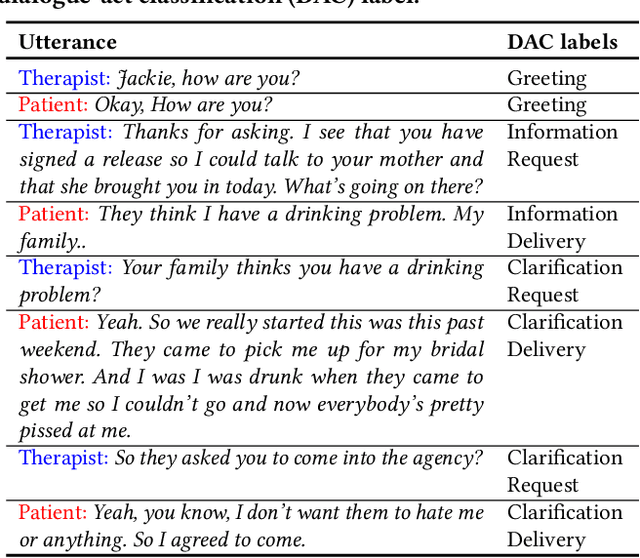
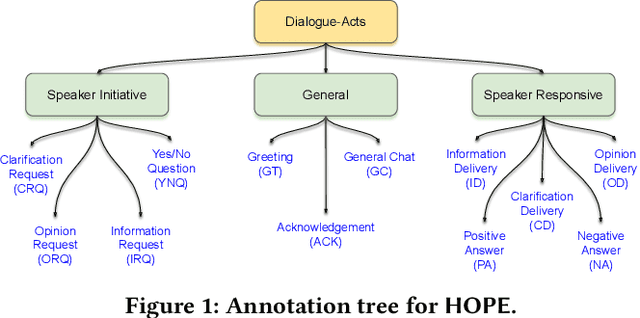
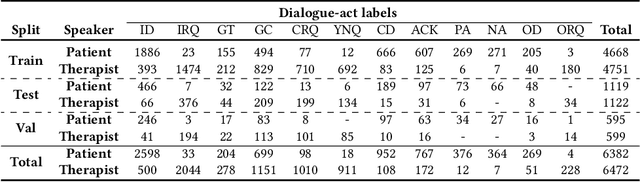
The onset of the COVID-19 pandemic has brought the mental health of people under risk. Social counselling has gained remarkable significance in this environment. Unlike general goal-oriented dialogues, a conversation between a patient and a therapist is considerably implicit, though the objective of the conversation is quite apparent. In such a case, understanding the intent of the patient is imperative in providing effective counselling in therapy sessions, and the same applies to a dialogue system as well. In this work, we take forward a small but an important step in the development of an automated dialogue system for mental-health counselling. We develop a novel dataset, named HOPE, to provide a platform for the dialogue-act classification in counselling conversations. We identify the requirement of such conversation and propose twelve domain-specific dialogue-act (DAC) labels. We collect 12.9K utterances from publicly-available counselling session videos on YouTube, extract their transcripts, clean, and annotate them with DAC labels. Further, we propose SPARTA, a transformer-based architecture with a novel speaker- and time-aware contextual learning for the dialogue-act classification. Our evaluation shows convincing performance over several baselines, achieving state-of-the-art on HOPE. We also supplement our experiments with extensive empirical and qualitative analyses of SPARTA.
MOMENTA: A Multimodal Framework for Detecting Harmful Memes and Their Targets
Sep 22, 2021
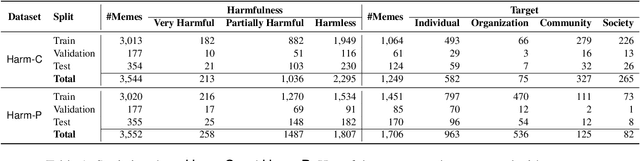
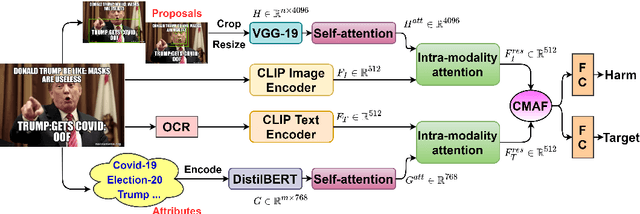
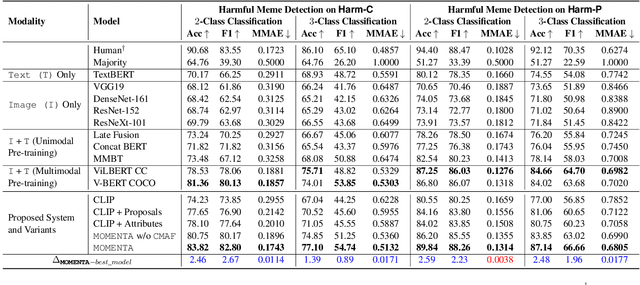
Internet memes have become powerful means to transmit political, psychological, and socio-cultural ideas. Although memes are typically humorous, recent days have witnessed an escalation of harmful memes used for trolling, cyberbullying, and abuse. Detecting such memes is challenging as they can be highly satirical and cryptic. Moreover, while previous work has focused on specific aspects of memes such as hate speech and propaganda, there has been little work on harm in general. Here, we aim to bridge this gap. We focus on two tasks: (i)detecting harmful memes, and (ii)identifying the social entities they target. We further extend a recently released HarMeme dataset, which covered COVID-19, with additional memes and a new topic: US politics. To solve these tasks, we propose MOMENTA (MultimOdal framework for detecting harmful MemEs aNd Their tArgets), a novel multimodal deep neural network that uses global and local perspectives to detect harmful memes. MOMENTA systematically analyzes the local and the global perspective of the input meme (in both modalities) and relates it to the background context. MOMENTA is interpretable and generalizable, and our experiments show that it outperforms several strong rivaling approaches.