 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering the Fact-checkers! Automatic Identification of Claim Spans on Twitter
Oct 11, 2022
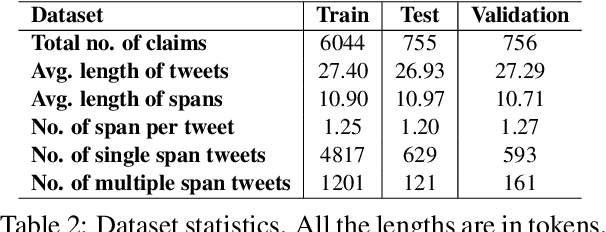
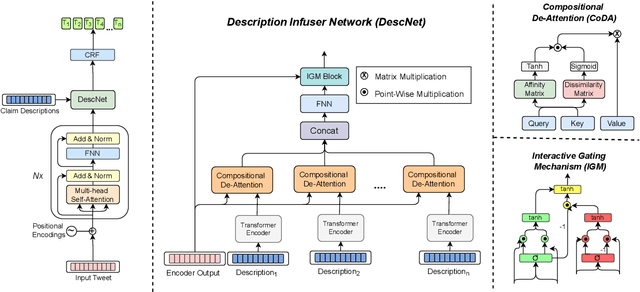
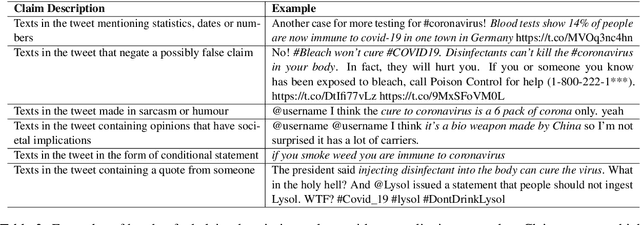
The widespread diffusion of medical and political claims in the wake of COVID-19 has led to a voluminous rise in misinformation and fake news. The current vogue is to employ manual fact-checkers to efficiently classify and verify such data to combat this avalanche of claim-ridden misinformation. However, the rate of information dissemination is such that it vastly outpaces the fact-checkers' strength. Therefore, to aid manual fact-checkers in eliminating the superfluous content, it becomes imperative to automatically identify and extract the snippets of claim-worthy (mis)information present in a post. In this work, we introduce the novel task of Claim Span Identification (CSI). We propose CURT, a large-scale Twitter corpus with token-level claim spans on more than 7.5k tweets. Furthermore, along with the standard token classification baselines, we benchmark our dataset with DABERTa, an adapter-based variation of RoBERTa. The experimental results attest that DABERTa outperforms the baseline systems across several evaluation metrics, improving by about 1.5 points. We also report detailed error analysis to validate the model's performance along with the ablation studies. Lastly, we release our comprehensive span annotation guidelines for public use.
Assessing the Quality of the Datasets by Identifying Mislabeled Samples
Sep 10, 2021

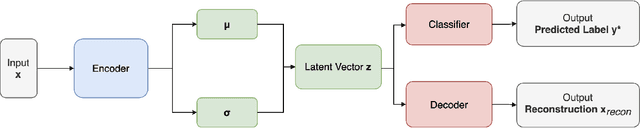
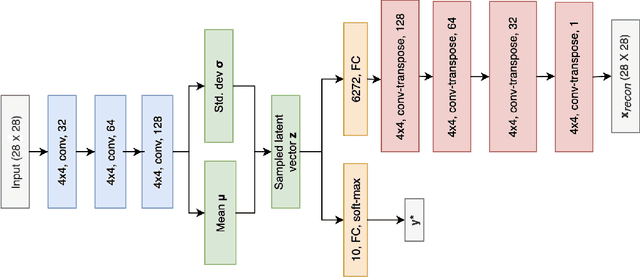
Due to the over-emphasize of the quantity of data, the data quality has often been overlooked. However, not all training data points contribute equally to learning. In particular, if mislabeled, it might actively damage the performance of the model and the ability to generalize out of distribution, as the model might end up learning spurious artifacts present in the dataset. This problem gets compounded by the prevalence of heavily parameterized and complex deep neural networks, which can, with their high capacity, end up memorizing the noise present in the dataset. This paper proposes a novel statistic -- noise score, as a measure for the quality of each data point to identify such mislabeled samples based on the variations in the latent space representation. In our work, we use the representations derived by the inference network of data quality supervised variational autoencoder (AQUAVS). Our method leverages the fact that samples belonging to the same class will have similar latent representations. Therefore, by identifying the outliers in the latent space, we can find the mislabeled samples. We validate our proposed statistic through experimentation by corrupting MNIST, FashionMNIST, and CIFAR10/100 datasets in different noise settings for the task of identifying mislabelled samples. We further show significant improvements in accuracy for the classification task for each dataset.