 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Words Don't Mean What They Say: Figurative Understanding in Bengali Idioms
Feb 13, 2026Figurative language understanding remains a significant challenge for Large Language Models (LLMs), especially for low-resource languages. To address this, we introduce a new idiom dataset, a large-scale, culturally-grounded corpus of 10,361 Bengali idioms. Each idiom is annotated under a comprehensive 19-field schema, established and refined through a deliberative expert consensus process, that captures its semantic, syntactic, cultural, and religious dimensions, providing a rich, structured resource for computational linguistics. To establish a robust benchmark for Bangla figurative language understanding, we evaluate 30 state-of-the-art multilingual and instruction-tuned LLMs on the task of inferring figurative meaning. Our results reveal a critical performance gap, with no model surpassing 50% accuracy, a stark contrast to significantly higher human performance (83.4%). This underscores the limitations of existing models in cross-linguistic and cultural reasoning. By releasing the new idiom dataset and benchmark, we provide foundational infrastructure for advancing figurative language understanding and cultural grounding in LLMs for Bengali and other low-resource languages.
Sentiment analysis in Bengali via transfer learning using multi-lingual BERT
Dec 03, 2020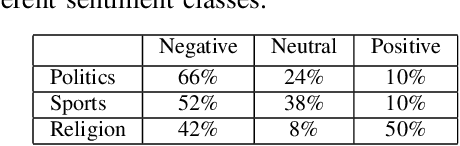
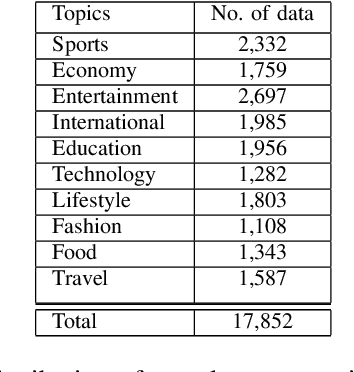
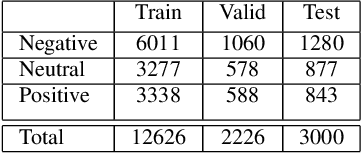
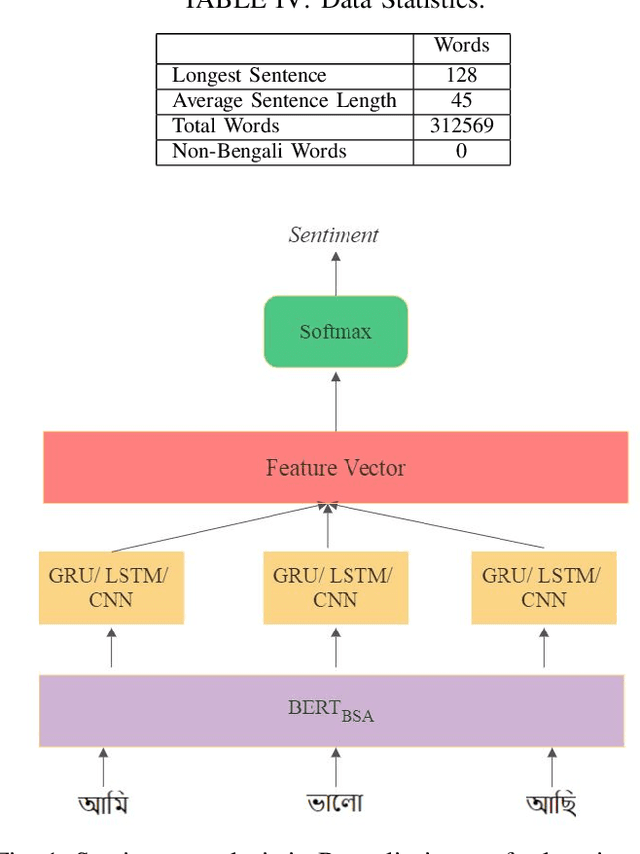
Sentiment analysis (SA) in Bengali is challenging due to this Indo-Aryan language's highly inflected properties with more than 160 different inflected forms for verbs and 36 different forms for noun and 24 different forms for pronouns. The lack of standard labeled datasets in the Bengali domain makes the task of SA even harder. In this paper, we present manually tagged 2-class and 3-class SA datasets in Bengali. We also demonstrate that the multi-lingual BERT model with relevant extensions can be trained via the approach of transfer learning over those novel datasets to improve the state-of-the-art performance in sentiment classification tasks. This deep learning model achieves an accuracy of 71\% for 2-class sentiment classification compared to the current state-of-the-art accuracy of 68\%. We also present the very first Bengali SA classifier for the 3-class manually tagged dataset, and our proposed model achieves an accuracy of 60\%. We further use this model to analyze the sentiment of public comments in the online daily newspaper. Our analysis shows that people post negative comments for political or sports news more often, while the religious article comments represent positive sentiment. The dataset and code is publicly available at https://github.com/KhondokerIslam/Bengali\_Sentiment.