 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving OCR for Historical Texts of Multiple Languages
Aug 14, 2025This paper presents our methodology and findings from three tasks across Optical Character Recognition (OCR) and Document Layout Analysis using advanced deep learning techniques. First, for the historical Hebrew fragments of the Dead Sea Scrolls, we enhanced our dataset through extensive data augmentation and employed the Kraken and TrOCR models to improve character recognition. In our analysis of 16th to 18th-century meeting resolutions task, we utilized a Convolutional Recurrent Neural Network (CRNN) that integrated DeepLabV3+ for semantic segmentation with a Bidirectional LSTM, incorporating confidence-based pseudolabeling to refine our model. Finally, for modern English handwriting recognition task, we applied a CRNN with a ResNet34 encoder, trained using the Connectionist Temporal Classification (CTC) loss function to effectively capture sequential dependencies. This report offers valuable insights and suggests potential directions for future research.
Reveal-Bangla: A Dataset for Cross-Lingual Multi-Step Reasoning Evaluation
Aug 12, 2025Language models have demonstrated remarkable performance on complex multi-step reasoning tasks. However, their evaluation has been predominantly confined to high-resource languages such as English. In this paper, we introduce a manually translated Bangla multi-step reasoning dataset derived from the English Reveal dataset, featuring both binary and non-binary question types. We conduct a controlled evaluation of English-centric and Bangla-centric multilingual small language models on the original dataset and our translated version to compare their ability to exploit relevant reasoning steps to produce correct answers. Our results show that, in comparable settings, reasoning context is beneficial for more challenging non-binary questions, but models struggle to employ relevant Bangla reasoning steps effectively. We conclude by exploring how reasoning steps contribute to models' predictions, highlighting different trends across models and languages.
Leveraging Sentiment for Offensive Text Classification
Dec 09, 2024



In this paper, we conduct experiment to analyze whether models can classify offensive texts better with the help of sentiment. We conduct this experiment on the SemEval 2019 task 6, OLID, dataset. First, we utilize pre-trained language models to predict the sentiment of each instance. Later we pick the model that achieved the best performance on the OLID test set, and train it on the augmented OLID set to analyze the performance. Results show that utilizing sentiment increases the overall performance of the model.
Sentiment analysis in Bengali via transfer learning using multi-lingual BERT
Dec 03, 2020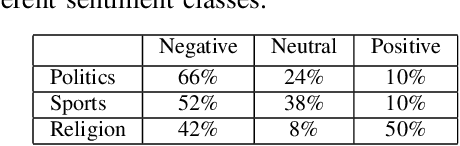
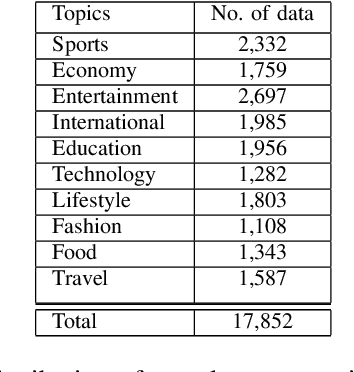
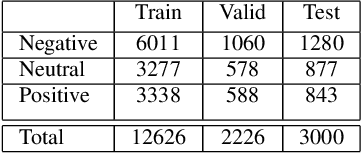
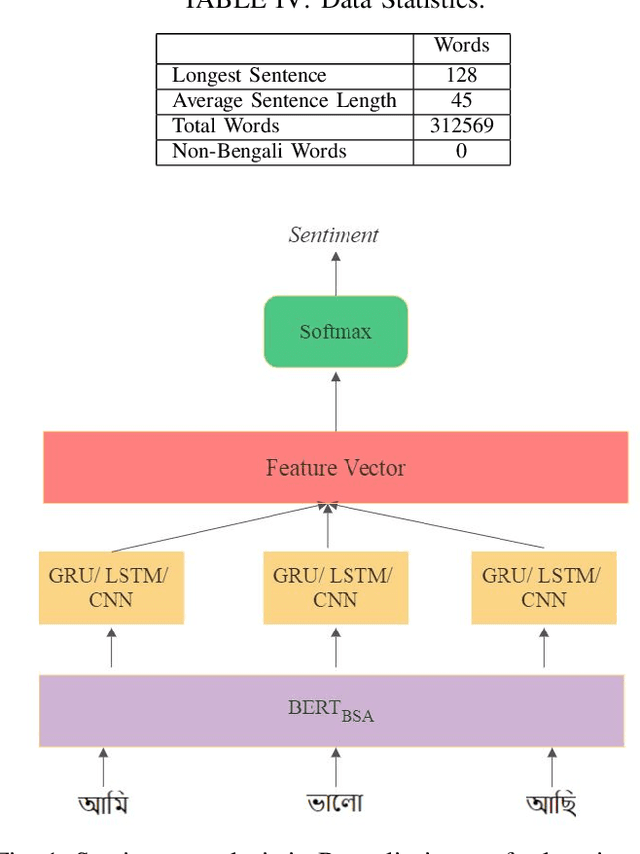
Sentiment analysis (SA) in Bengali is challenging due to this Indo-Aryan language's highly inflected properties with more than 160 different inflected forms for verbs and 36 different forms for noun and 24 different forms for pronouns. The lack of standard labeled datasets in the Bengali domain makes the task of SA even harder. In this paper, we present manually tagged 2-class and 3-class SA datasets in Bengali. We also demonstrate that the multi-lingual BERT model with relevant extensions can be trained via the approach of transfer learning over those novel datasets to improve the state-of-the-art performance in sentiment classification tasks. This deep learning model achieves an accuracy of 71\% for 2-class sentiment classification compared to the current state-of-the-art accuracy of 68\%. We also present the very first Bengali SA classifier for the 3-class manually tagged dataset, and our proposed model achieves an accuracy of 60\%. We further use this model to analyze the sentiment of public comments in the online daily newspaper. Our analysis shows that people post negative comments for political or sports news more often, while the religious article comments represent positive sentiment. The dataset and code is publicly available at https://github.com/KhondokerIslam/Bengali\_Sentiment.