 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Source Cybersecurity Logs: An ATT&CK-Labeled Dataset and SLM Evaluation
Jun 16, 2026Multi-stage cyberattacks span system, network, and browser logs. Detecting them requires correlating events across all three sources. Machine learning methods can learn these cross-source patterns, but they need labeled multi-source data. Existing public datasets fall short. Network-only datasets such as CICIDS and UNSW-NB15 miss host and browser activity. Host-focused datasets such as LMDG and CICAPT-IIoT lack browser telemetry. ATLAS includes all three sources but labels events only as malicious or benign, without MITRE Adversarial Tactics, Techniques, and Common Knowledge (ATT&CK) technique granularity. No public dataset combines all three sources with per-entry ATT&CK technique labels. We close the gap by building a multi-source log dataset of 870 sessions (70 attack, 800 benign) and approximately 2.3 million events. We captured system, network, and browser activity simultaneously on Windows endpoints. We labeled malicious events with ATT&CK technique IDs, covering 12 tactics and 53 techniques. We generated all attack data using real tools, including Remote Access Trojan (RAT), Command and Control (C2) tunnels, and cloud exfiltration. To demonstrate learnability, we fine-tuned three Small Language Models (SLMs) (Qwen2.5-1.5B, Llama-3.2-3B, Phi-4-Mini) using Low-Rank Adaptation (LoRA). We compared each against its base variant across ten metrics on two tasks: chunk classification and ATT&CK technique identification. Fine-tuning improved every model on every metric. Chunk classification accuracy rose from approximately 8% in the base variants to between 90% and 97% after fine-tuning. Technique identification remained challenging, with the best exact-match accuracy at 42%, although high partial-match scores show the models captured most of the underlying reasoning.
Evaluating Open-Source LLMs for Multi-Label ATT&CK Technique Classification on CTI Reports
Jun 16, 2026Classifying Cyber Threat Intelligence (CTI) using MITRE Adversarial Tactics, Techniques, and Common Knowledge (ATT&CK) is essential for proactive defense, but historically required extensive human effort. Pre-Large Language Model (LLM) automation sped up this process, but could not resolve the complex language and multi-step attack patterns found in unstructured CTI reports. LLMs addressed previous limitations by using contextual reasoning to understand unstructured text. However, current evaluations rely on simplified, single-technique sentences that ignore the complexity of real-world CTI reports, which often leads to inflated performance results. Consequently, the baseline performance of open-source LLMs on complex unstructured CTI reports remains unevaluated. To address this gap, we constructed a ground-truth dataset of 2,076 human-annotated sentences (1,281 technique-positive, 795 negative) from 83 complex unstructured CTI reports. These sentences were mapped to 114 unique ATT&CK techniques using a six-phase annotation process, achieving \k{appa} = 0.68 inter-annotator agreement. Using this dataset, we evaluated seven open-source LLMs ranging from 8B to 236B parameters across prompt strategy and temperature configurations. The highest-performing LLM achieved a micro-averaged F1 score of 0.22, establishing the empirical baseline for multi-label ATT&CK classification on complex unstructured CTI. Parameter size showed a statistically significant positive correlation with F1 score. Prompt strategy and temperature produced no statistically significant gains across model configurations. These results indicate that current open-source LLMs are insufficient for production-grade ATT&CK classification. The dataset, benchmark, and findings provide a reproducible foundation for future CTI research.
From Natural Language to Verified Code: Toward AI Assisted Problem-to-Code Generation with Dafny-Based Formal Verification
Apr 24, 2026Large Language Models (LLMs) show promise in automated software engineering, yet their guarantee of correctness is frequently undermined by erroneous or hallucinated code. To enforce model honesty, formal verification requires LLMs to synthesize implementation logic alongside formal specifications that are subsequently proven correct by a mathematical verifier. However, the transition from informal natural language to precise formal specification remains an arduous task. Our work addresses this by providing the NaturalLanguage2VerifiedCode (NL2VC)-60 dataset: a collection of 60 complex algorithmic problems. We evaluate 11 randomly selected problem sets across seven open-weight LLMs using a tiered prompting strategy: contextless prompts, signature prompts providing structural anchors, and self-healing prompts utilizing iterative feedback from the Dafny verifier. To address vacuous verification, where models satisfy verifiers with trivial specifications, we integrate the uDebug platform to ensure functional validation. Our results show that while contextless prompting leads to near-universal failure, structural signatures and iterative self-healing facilitate a dramatic performance turnaround. Specifically, Gemma 4-31B achieved a 90.91\% verification success rate, while GPT-OSS 120B rose from zero to 81.82\% success with signature-guided feedback. These findings indicate that formal verification is now attainable for open-weight LLMs, which serve as effective apprentices for synthesizing complex annotations and facilitating high-assurance software development.
FALCON: Autonomous Cyber Threat Intelligence Mining with LLMs for IDS Rule Generation
Aug 26, 2025Signature-based Intrusion Detection Systems (IDS) detect malicious activities by matching network or host activity against predefined rules. These rules are derived from extensive Cyber Threat Intelligence (CTI), which includes attack signatures and behavioral patterns obtained through automated tools and manual threat analysis, such as sandboxing. The CTI is then transformed into actionable rules for the IDS engine, enabling real-time detection and prevention. However, the constant evolution of cyber threats necessitates frequent rule updates, which delay deployment time and weaken overall security readiness. Recent advancements in agentic systems powered by Large Language Models (LLMs) offer the potential for autonomous IDS rule generation with internal evaluation. We introduce FALCON, an autonomous agentic framework that generates deployable IDS rules from CTI data in real-time and evaluates them using built-in multi-phased validators. To demonstrate versatility, we target both network (Snort) and host-based (YARA) mediums and construct a comprehensive dataset of IDS rules with their corresponding CTIs. Our evaluations indicate FALCON excels in automatic rule generation, with an average of 95% accuracy validated by qualitative evaluation with 84% inter-rater agreement among multiple cybersecurity analysts across all metrics. These results underscore the feasibility and effectiveness of LLM-driven data mining for real-time cyber threat mitigation.
Mining Temporal Attack Patterns from Cyberthreat Intelligence Reports
Jan 03, 2024



Defending from cyberattacks requires practitioners to operate on high-level adversary behavior. Cyberthreat intelligence (CTI) reports on past cyberattack incidents describe the chain of malicious actions with respect to time. To avoid repeating cyberattack incidents, practitioners must proactively identify and defend against recurring chain of actions - which we refer to as temporal attack patterns. Automatically mining the patterns among actions provides structured and actionable information on the adversary behavior of past cyberattacks. The goal of this paper is to aid security practitioners in prioritizing and proactive defense against cyberattacks by mining temporal attack patterns from cyberthreat intelligence reports. To this end, we propose ChronoCTI, an automated pipeline for mining temporal attack patterns from cyberthreat intelligence (CTI) reports of past cyberattacks. To construct ChronoCTI, we build the ground truth dataset of temporal attack patterns and apply state-of-the-art large language models, natural language processing, and machine learning techniques. We apply ChronoCTI on a set of 713 CTI reports, where we identify 124 temporal attack patterns - which we categorize into nine pattern categories. We identify that the most prevalent pattern category is to trick victim users into executing malicious code to initiate the attack, followed by bypassing the anti-malware system in the victim network. Based on the observed patterns, we advocate organizations to train users about cybersecurity best practices, introduce immutable operating systems with limited functionalities, and enforce multi-user authentications. Moreover, we advocate practitioners to leverage the automated mining capability of ChronoCTI and design countermeasures against the recurring attack patterns.
From Threat Reports to Continuous Threat Intelligence: A Comparison of Attack Technique Extraction Methods from Textual Artifacts
Oct 05, 2022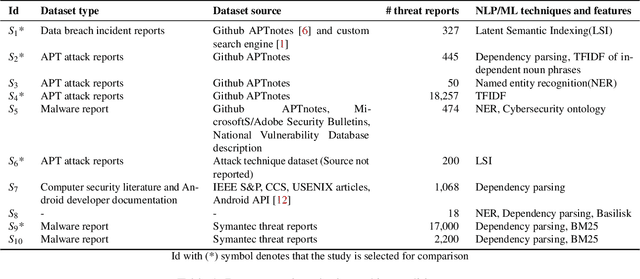
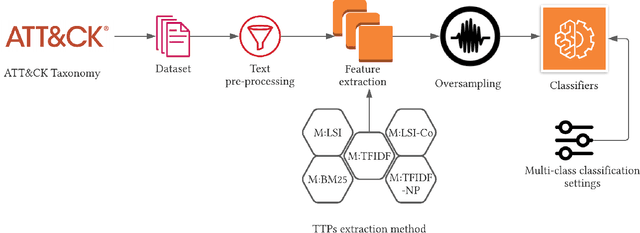
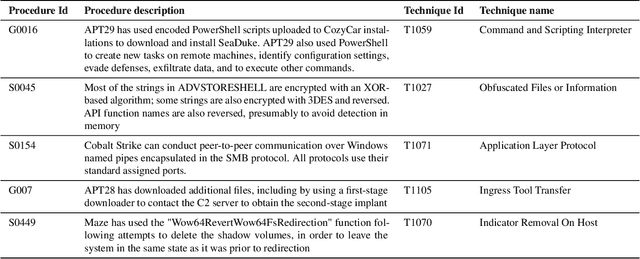
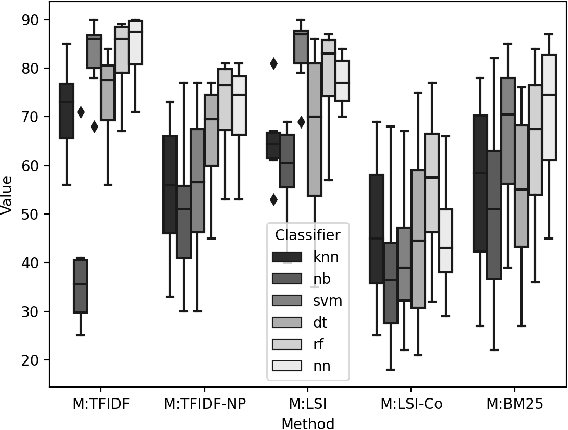
The cyberthreat landscape is continuously evolving. Hence, continuous monitoring and sharing of threat intelligence have become a priority for organizations. Threat reports, published by cybersecurity vendors, contain detailed descriptions of attack Tactics, Techniques, and Procedures (TTP) written in an unstructured text format. Extracting TTP from these reports aids cybersecurity practitioners and researchers learn and adapt to evolving attacks and in planning threat mitigation. Researchers have proposed TTP extraction methods in the literature, however, not all of these proposed methods are compared to one another or to a baseline. \textit{The goal of this study is to aid cybersecurity researchers and practitioners choose attack technique extraction methods for monitoring and sharing threat intelligence by comparing the underlying methods from the TTP extraction studies in the literature.} In this work, we identify ten existing TTP extraction studies from the literature and implement five methods from the ten studies. We find two methods, based on Term Frequency-Inverse Document Frequency(TFIDF) and Latent Semantic Indexing (LSI), outperform the other three methods with a F1 score of 84\% and 83\%, respectively. We observe the performance of all methods in F1 score drops in the case of increasing the class labels exponentially. We also implement and evaluate an oversampling strategy to mitigate class imbalance issues. Furthermore, oversampling improves the classification performance of TTP extraction. We provide recommendations from our findings for future cybersecurity researchers, such as the construction of a benchmark dataset from a large corpus; and the selection of textual features of TTP. Our work, along with the dataset and implementation source code, can work as a baseline for cybersecurity researchers to test and compare the performance of future TTP extraction methods.
What are the attackers doing now? Automating cyber threat intelligence extraction from text on pace with the changing threat landscape: A survey
Sep 14, 2021
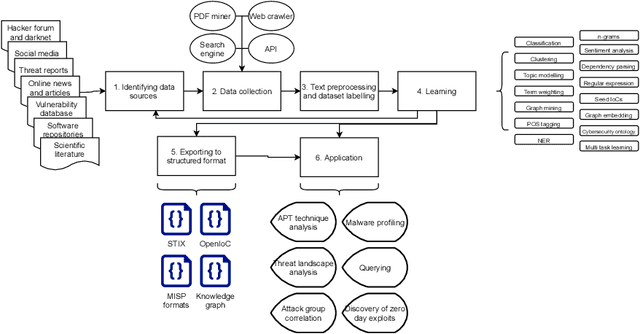
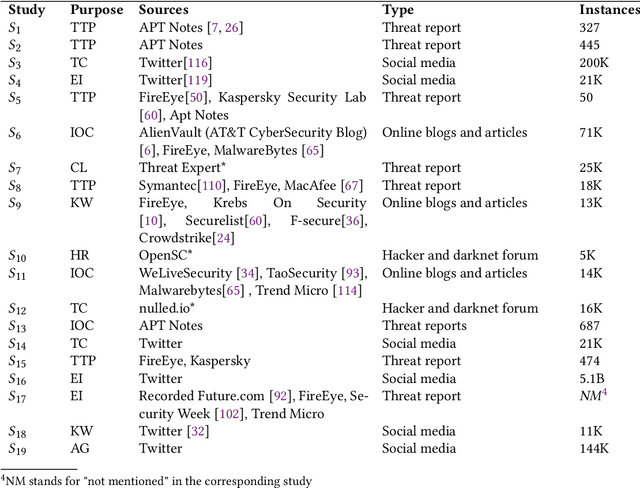
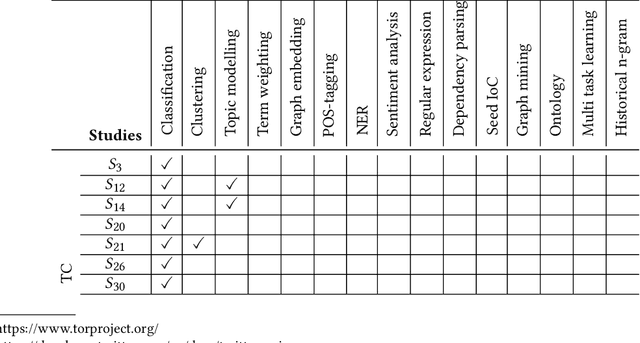
Cybersecurity researchers have contributed to the automated extraction of CTI from textual sources, such as threat reports and online articles, where cyberattack strategies, procedures, and tools are described. The goal of this article is to aid cybersecurity researchers understand the current techniques used for cyberthreat intelligence extraction from text through a survey of relevant studies in the literature. We systematically collect "CTI extraction from text"-related studies from the literature and categorize the CTI extraction purposes. We propose a CTI extraction pipeline abstracted from these studies. We identify the data sources, techniques, and CTI sharing formats utilized in the context of the proposed pipeline. Our work finds ten types of extraction purposes, such as extraction indicators of compromise extraction, TTPs (tactics, techniques, procedures of attack), and cybersecurity keywords. We also identify seven types of textual sources for CTI extraction, and textual data obtained from hacker forums, threat reports, social media posts, and online news articles have been used by almost 90% of the studies. Natural language processing along with both supervised and unsupervised machine learning techniques such as named entity recognition, topic modelling, dependency parsing, supervised classification, and clustering are used for CTI extraction. We observe the technical challenges associated with these studies related to obtaining available clean, labelled data which could assure replication, validation, and further extension of the studies. As we find the studies focusing on CTI information extraction from text, we advocate for building upon the current CTI extraction work to help cybersecurity practitioners with proactive decision making such as threat prioritization, automated threat modelling to utilize knowledge from past cybersecurity incidents.