 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Zero-Shot Framework for Deepfake Hate Speech Detection in Low-Resource Languages
Jun 10, 2025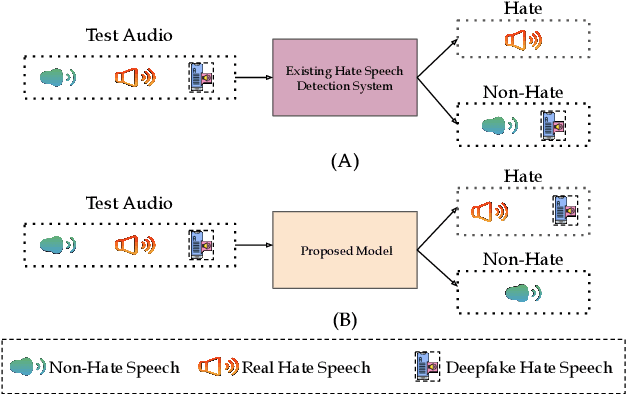
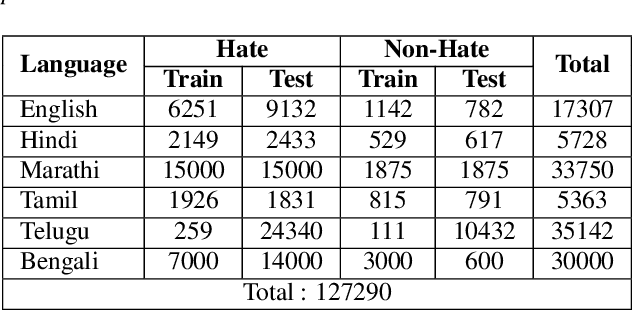
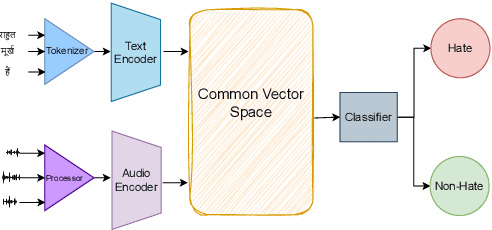
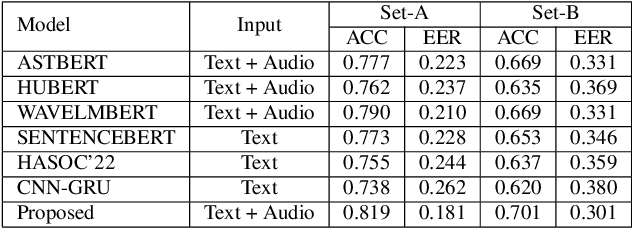
This paper introduces a novel multimodal framework for hate speech detection in deepfake audio, excelling even in zero-shot scenarios. Unlike previous approaches, our method uses contrastive learning to jointly align audio and text representations across languages. We present the first benchmark dataset with 127,290 paired text and synthesized speech samples in six languages: English and five low-resource Indian languages (Hindi, Bengali, Marathi, Tamil, Telugu). Our model learns a shared semantic embedding space, enabling robust cross-lingual and cross-modal classification. Experiments on two multilingual test sets show our approach outperforms baselines, achieving accuracies of 0.819 and 0.701, and generalizes well to unseen languages. This demonstrates the advantage of combining modalities for hate speech detection in synthetic media, especially in low-resource settings where unimodal models falter. The Dataset is available at https://www.iab-rubric.org/resources.