 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAIGen: Training-Free Adversarial Image Generation via Diffusion Models
Aug 20, 2025Adversarial attacks from generative models often produce low-quality images and require substantial computational resources. Diffusion models, though capable of high-quality generation, typically need hundreds of sampling steps for adversarial generation. This paper introduces TAIGen, a training-free black-box method for efficient adversarial image generation. TAIGen produces adversarial examples using only 3-20 sampling steps from unconditional diffusion models. Our key finding is that perturbations injected during the mixing step interval achieve comparable attack effectiveness without processing all timesteps. We develop a selective RGB channel strategy that applies attention maps to the red channel while using GradCAM-guided perturbations on green and blue channels. This design preserves image structure while maximizing misclassification in target models. TAIGen maintains visual quality with PSNR above 30 dB across all tested datasets. On ImageNet with VGGNet as source, TAIGen achieves 70.6% success against ResNet, 80.8% against MNASNet, and 97.8% against ShuffleNet. The method generates adversarial examples 10x faster than existing diffusion-based attacks. Our method achieves the lowest robust accuracy, indicating it is the most impactful attack as the defense mechanism is least successful in purifying the images generated by TAIGen.
Discerning the Chaos: Detecting Adversarial Perturbations while Disentangling Intentional from Unintentional Noises
Sep 29, 2024Deep learning models, such as those used for face recognition and attribute prediction, are susceptible to manipulations like adversarial noise and unintentional noise, including Gaussian and impulse noise. This paper introduces CIAI, a Class-Independent Adversarial Intent detection network built on a modified vision transformer with detection layers. CIAI employs a novel loss function that combines Maximum Mean Discrepancy and Center Loss to detect both intentional (adversarial attacks) and unintentional noise, regardless of the image class. It is trained in a multi-step fashion. We also introduce the aspect of intent during detection that can act as an added layer of security. We further showcase the performance of our proposed detector on CelebA, CelebA-HQ, LFW, AgeDB, and CIFAR-10 datasets. Our detector is able to detect both intentional (like FGSM, PGD, and DeepFool) and unintentional (like Gaussian and Salt & Pepper noises) perturbations.
Adventures of Trustworthy Vision-Language Models: A Survey
Dec 07, 2023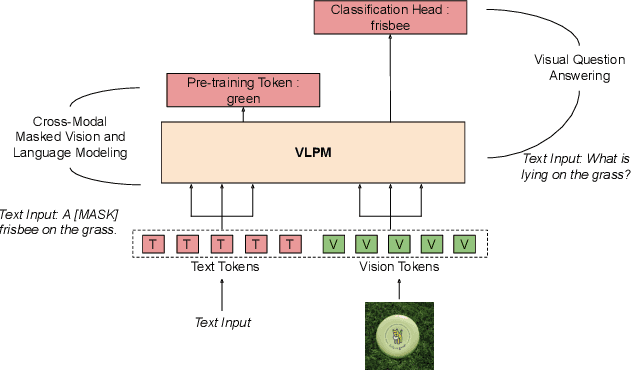
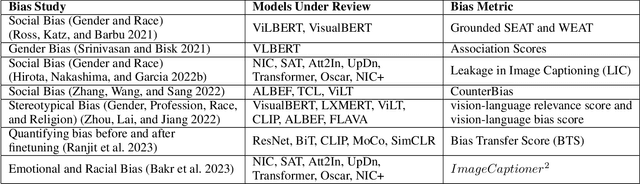
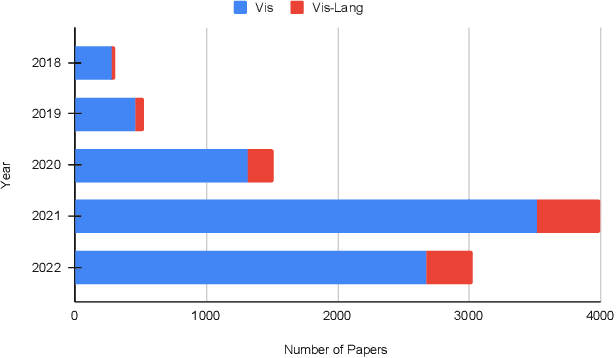
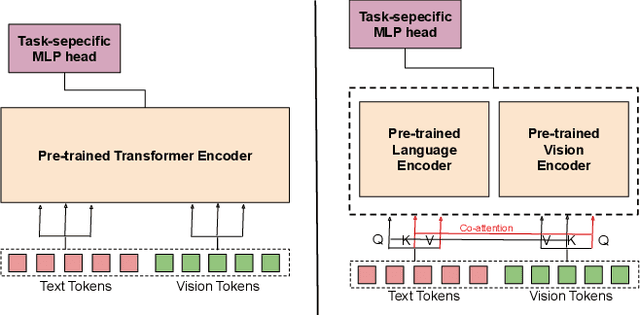
Recently, transformers have become incredibly popular in computer vision and vision-language tasks. This notable rise in their usage can be primarily attributed to the capabilities offered by attention mechanisms and the outstanding ability of transformers to adapt and apply themselves to a variety of tasks and domains. Their versatility and state-of-the-art performance have established them as indispensable tools for a wide array of applications. However, in the constantly changing landscape of machine learning, the assurance of the trustworthiness of transformers holds utmost importance. This paper conducts a thorough examination of vision-language transformers, employing three fundamental principles of responsible AI: Bias, Robustness, and Interpretability. The primary objective of this paper is to delve into the intricacies and complexities associated with the practical use of transformers, with the overarching goal of advancing our comprehension of how to enhance their reliability and accountability.