 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Neuro-Symbolic Architecture for Image-to-Image Reasoning Tasks
Jun 06, 2021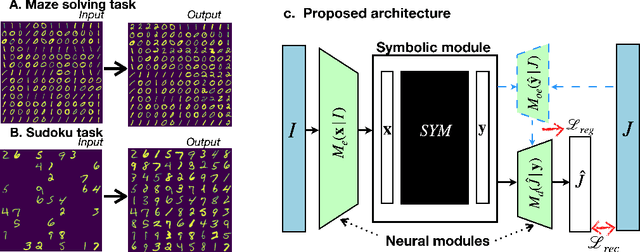
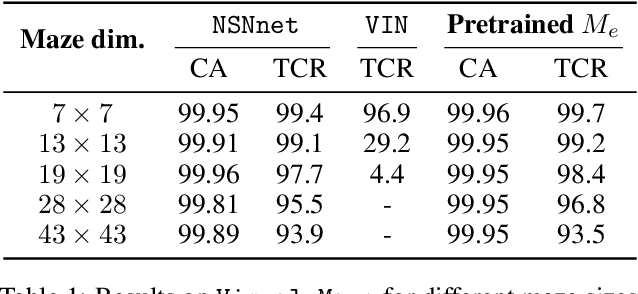

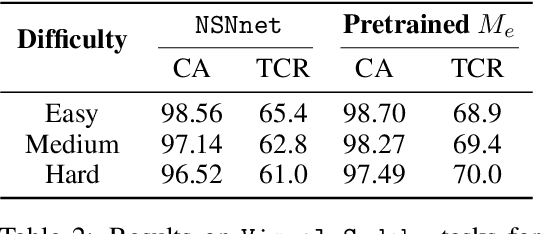
Neural models and symbolic algorithms have recently been combined for tasks requiring both perception and reasoning. Neural models ground perceptual input into a conceptual vocabulary, on which a classical reasoning algorithm is applied to generate output. A key limitation is that such neural-to-symbolic models can only be trained end-to-end for tasks where the output space is symbolic. In this paper, we study neural-symbolic-neural models for reasoning tasks that require a conversion from an image input (e.g., a partially filled sudoku) to an image output (e.g., the image of the completed sudoku). While designing such a three-step hybrid architecture may be straightforward, the key technical challenge is end-to-end training -- how to backpropagate without intermediate supervision through the symbolic component. We propose NSNnet, an architecture that combines an image reconstruction loss with a novel output encoder to generate a supervisory signal, develops update algorithms that leverage policy gradient methods for supervision, and optimizes loss using a novel subsampling heuristic. We experiment on problem settings where symbolic algorithms are easily specified: a visual maze solving task and a visual Sudoku solver where the supervision is in image form. Experiments show high accuracy with significantly less data compared to purely neural approaches.
TANGO: Commonsense Generalization in Predicting Tool Interactions for Mobile Manipulators
May 23, 2021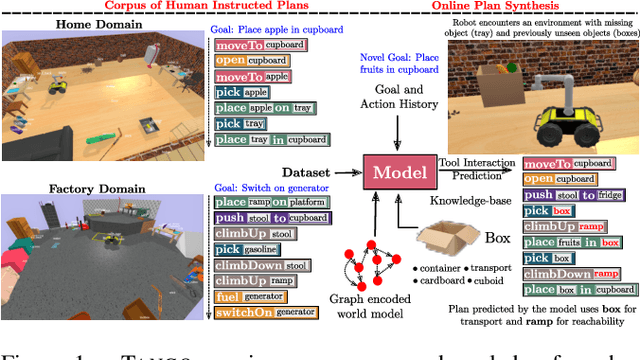
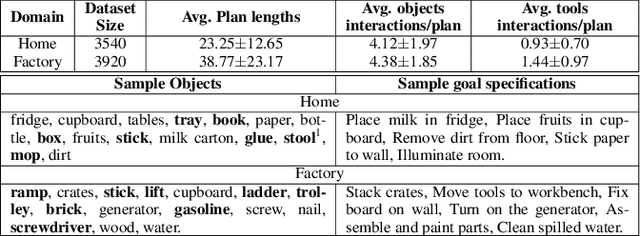
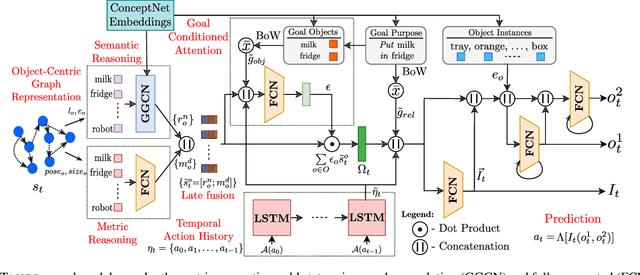
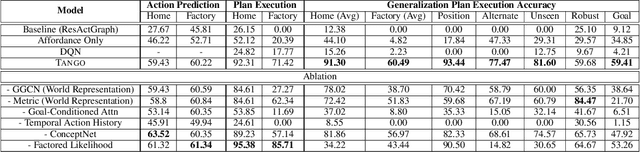
Robots assisting us in factories or homes must learn to make use of objects as tools to perform tasks, e.g., a tray for carrying objects. We consider the problem of learning commonsense knowledge of when a tool may be useful and how its use may be composed with other tools to accomplish a high-level task instructed by a human. We introduce a novel neural model, termed TANGO, for predicting task-specific tool interactions, trained using demonstrations from human teachers instructing a virtual robot. TANGO encodes the world state, comprising objects and symbolic relationships between them, using a graph neural network. The model learns to attend over the scene using knowledge of the goal and the action history, finally decoding the symbolic action to execute. Crucially, we address generalization to unseen environments where some known tools are missing, but alternative unseen tools are present. We show that by augmenting the representation of the environment with pre-trained embeddings derived from a knowledge-base, the model can generalize effectively to novel environments. Experimental results show a 60.5-78.9% absolute improvement over the baseline in predicting successful symbolic plans in unseen settings for a simulated mobile manipulator.
Multilingual Knowledge Graph Completion with Joint Relation and Entity Alignment
Apr 18, 2021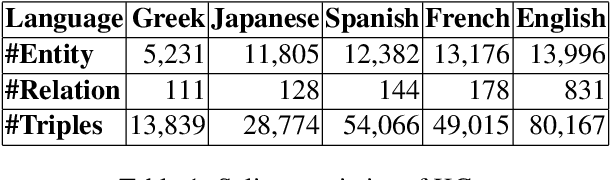
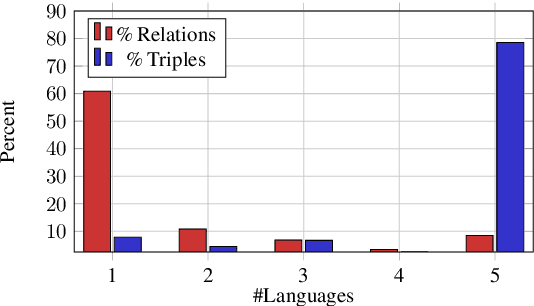
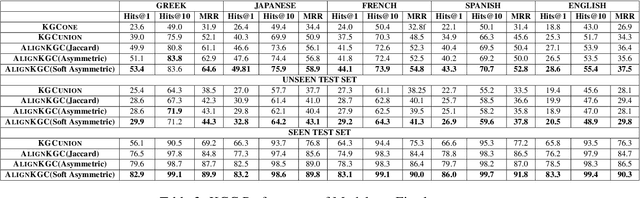

Knowledge Graph Completion (KGC) predicts missing facts in an incomplete Knowledge Graph. Almost all of existing KGC research is applicable to only one KG at a time, and in one language only. However, different language speakers may maintain separate KGs in their language and no individual KG is expected to be complete. Moreover, common entities or relations in these KGs have different surface forms and IDs, leading to ID proliferation. Entity alignment (EA) and relation alignment (RA) tasks resolve this by recognizing pairs of entity (relation) IDs in different KGs that represent the same entity (relation). This can further help prediction of missing facts, since knowledge from one KG is likely to benefit completion of another. High confidence predictions may also add valuable information for the alignment tasks. In response, we study the novel task of jointly training multilingual KGC, relation alignment and entity alignment models. We present ALIGNKGC, which uses some seed alignments to jointly optimize all three of KGC, EA and RA losses. A key component of ALIGNKGC is an embedding based soft notion of asymmetric overlap defined on the (subject, object) set signatures of relations this aids in better predicting relations that are equivalent to or implied by other relations. Extensive experiments with DBPedia in five languages establish the benefits of joint training for all tasks, achieving 10-32 MRR improvements of ALIGNKGC over a strong state-of-the-art single-KGC system completion model over each monolingual KG . Further, ALIGNKGC achieves reasonable gains in EA and RA tasks over a vanilla completion model over a KG that combines all facts without alignment, underscoring the value of joint training for these tasks.
CEAR: Cross-Entity Aware Reranker for Knowledge Base Completion
Apr 18, 2021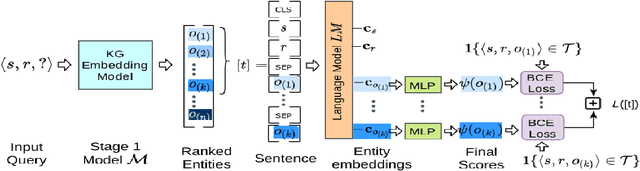
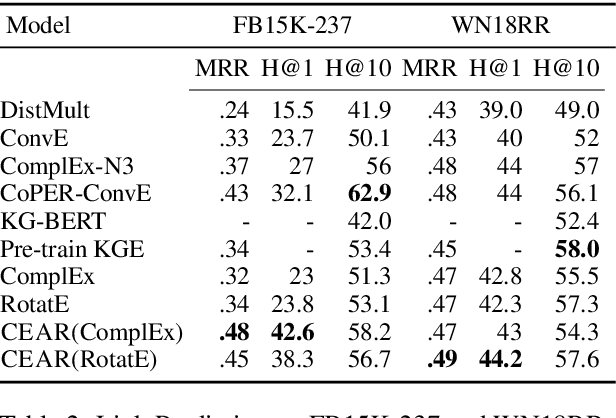

Pre-trained language models (LMs) like BERT have shown to store factual knowledge about the world. This knowledge can be used to augment the information present in Knowledge Bases, which tend to be incomplete. However, prior attempts at using BERT for task of Knowledge Base Completion (KBC) resulted in performance worse than embedding based techniques that rely only on the graph structure. In this work we develop a novel model, Cross-Entity Aware Reranker (CEAR), that uses BERT to re-rank the output of existing KBC models with cross-entity attention. Unlike prior work that scores each entity independently, CEAR uses BERT to score the entities together, which is effective for exploiting its factual knowledge. CEAR establishes a new state of the art performance with 42.6 HITS@1 in FB15k-237 (32.7% relative improvement) and 5.3 pt improvement in HITS@1 for Open Link Prediction.
DiS-ReX: A Multilingual Dataset for Distantly Supervised Relation Extraction
Apr 17, 2021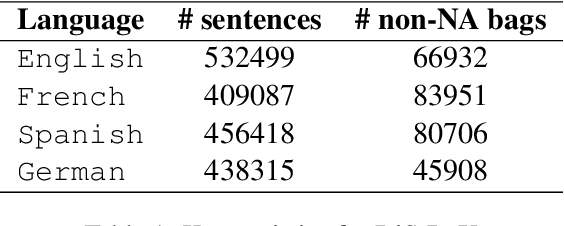
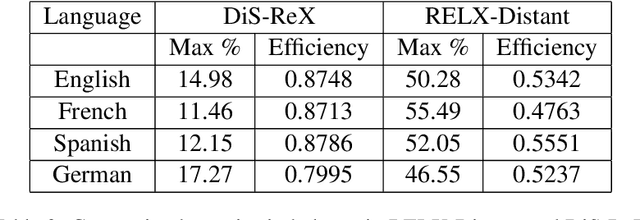
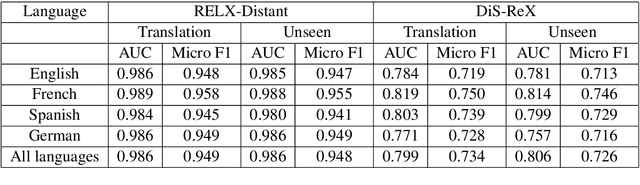
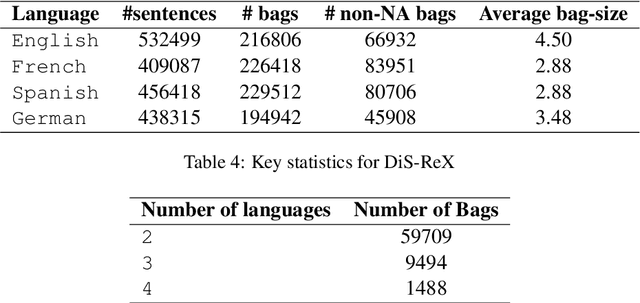
Distant supervision (DS) is a well established technique for creating large-scale datasets for relation extraction (RE) without using human annotations. However, research in DS-RE has been mostly limited to the English language. Constraining RE to a single language inhibits utilization of large amounts of data in other languages which could allow extraction of more diverse facts. Very recently, a dataset for multilingual DS-RE has been released. However, our analysis reveals that the proposed dataset exhibits unrealistic characteristics such as 1) lack of sentences that do not express any relation, and 2) all sentences for a given entity pair expressing exactly one relation. We show that these characteristics lead to a gross overestimation of the model performance. In response, we propose a new dataset, DiS-ReX, which alleviates these issues. Our dataset has more than 1.5 million sentences, spanning across 4 languages with 36 relation classes + 1 no relation (NA) class. We also modify the widely used bag attention models by encoding sentences using mBERT and provide the first benchmark results on multilingual DS-RE. Unlike the competing dataset, we show that our dataset is challenging and leaves enough room for future research to take place in this field.
Joint Spatio-Textual Reasoning for Answering Tourism Questions
Oct 19, 2020

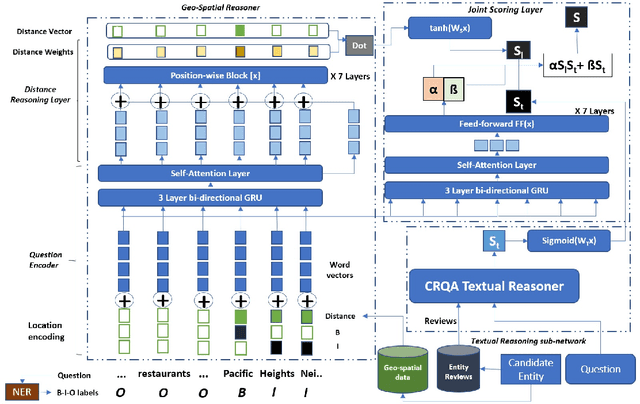
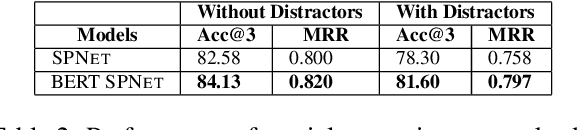
Our goal is to answer real-world tourism questions that seek Points-of-Interest (POI) recommendations. Such questions express various kinds of spatial and non-spatial constraints, necessitating a combination of textual and spatial reasoning. In response, we develop the first joint spatio-textual reasoning model, which combines geo-spatial knowledge with information in textual corpora to answer questions. We first develop a modular spatial-reasoning network that uses geo-coordinates of location names mentioned in a question, and of candidate answer POIs, to reason over only spatial constraints. We then combine our spatial-reasoner with a textual reasoner in a joint model and present experiments on a real world POI recommendation task. We report substantial improvements over existing models with-out joint spatio-textual reasoning.
OpenIE6: Iterative Grid Labeling and Coordination Analysis for Open Information Extraction
Oct 07, 2020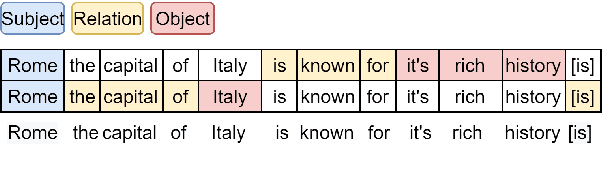

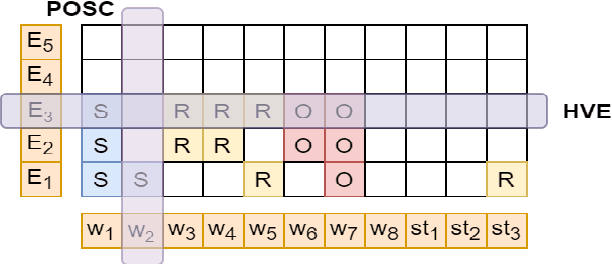
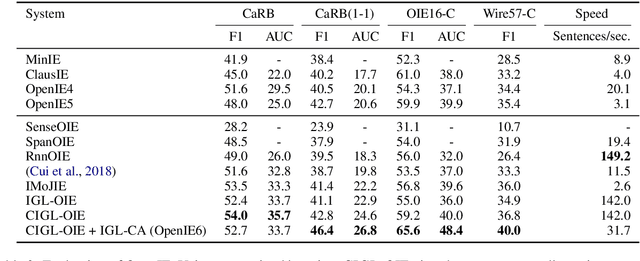
A recent state-of-the-art neural open information extraction (OpenIE) system generates extractions iteratively, requiring repeated encoding of partial outputs. This comes at a significant computational cost. On the other hand, sequence labeling approaches for OpenIE are much faster, but worse in extraction quality. In this paper, we bridge this trade-off by presenting an iterative labeling-based system that establishes a new state of the art for OpenIE, while extracting 10x faster. This is achieved through a novel Iterative Grid Labeling (IGL) architecture, which treats OpenIE as a 2-D grid labeling task. We improve its performance further by applying coverage (soft) constraints on the grid at training time. Moreover, on observing that the best OpenIE systems falter at handling coordination structures, our OpenIE system also incorporates a new coordination analyzer built with the same IGL architecture. This IGL based coordination analyzer helps our OpenIE system handle complicated coordination structures, while also establishing a new state of the art on the task of coordination analysis, with a 12.3 pts improvement in F1 over previous analyzers. Our OpenIE system, OpenIE6, beats the previous systems by as much as 4 pts in F1, while being much faster.
Neural Learning of One-of-Many Solutions for Combinatorial Problems in Structured Output Spaces
Aug 27, 2020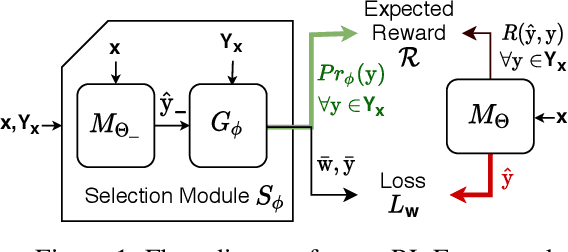

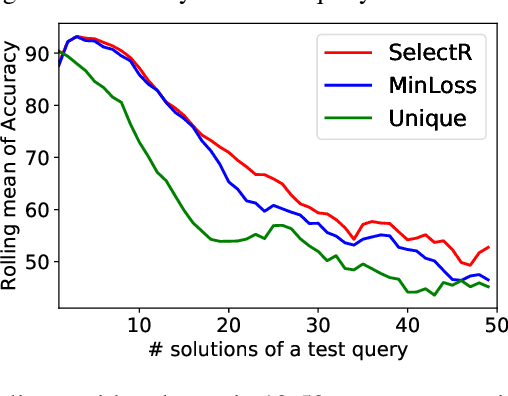
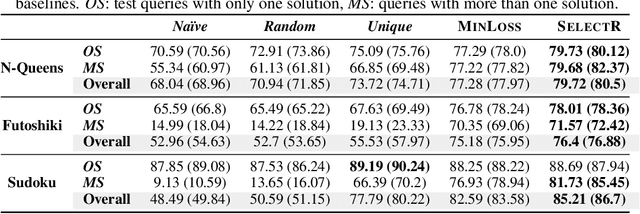
Recent research has proposed neural architectures for solving combinatorial problems in structured output spaces. In many such problems, there may exist multiple solutions for a given input, e.g. a partially filled Sudoku puzzle may have many completions satisfying all constraints. Further, we are often interested in finding {\em any one} of the possible solutions, without any preference between them. Existing approaches completely ignore this solution multiplicity. In this paper, we argue that being oblivious to the presence of multiple solutions can severely hamper their training ability. Our contribution is two fold. First, we formally define the task of learning one-of-many solutions for combinatorial problems in structured output spaces, which is applicable for solving several problems of interest such as N-Queens, and Sudoku. Second, we present a generic learning framework that adapts an existing prediction network for a combinatorial problem to handle solution multiplicity. Our framework uses a selection module, whose goal is to dynamically determine, for every input, the solution that is most effective for training the network parameters in any given learning iteration. We propose an RL based approach to jointly train the selection module with the prediction network. Experiments on three different domains, and using two different prediction networks, demonstrate that our framework significantly improves the accuracy in our setting, obtaining up to $21$ pt gain over the baselines.
ToolNet: Using Commonsense Generalization for Predicting Tool Use for Robot Plan Synthesis
Jun 18, 2020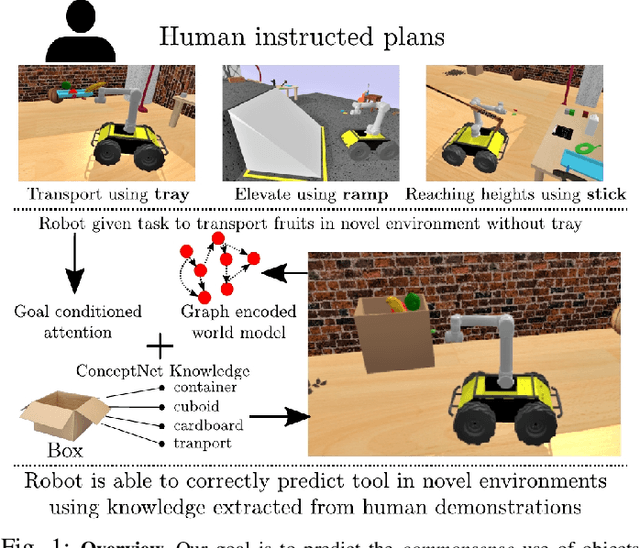
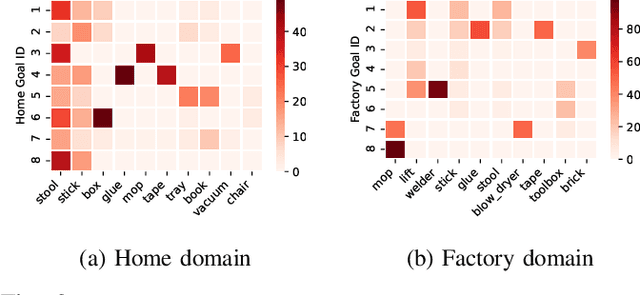
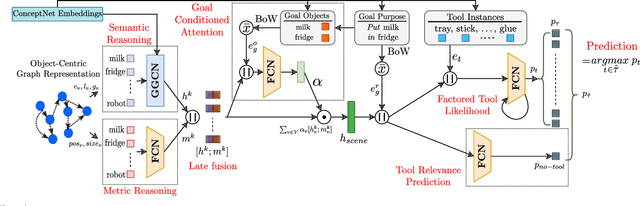
A robot working in a physical environment (like home or factory) needs to learn to use various available tools for accomplishing different tasks, for instance, a mop for cleaning and a tray for carrying objects. The number of possible tools is large and it may not be feasible to demonstrate usage of each individual tool during training. Can a robot learn commonsense knowledge and adapt to novel settings where some known tools are missing, but alternative unseen tools are present? We present a neural model that predicts the best tool from the available objects for achieving a given declarative goal. This model is trained by user demonstrations, which we crowd-source through humans instructing a robot in a physics simulator. This dataset maintains user plans involving multi-step object interactions along with symbolic state changes. Our neural model, ToolNet, combines a graph neural network to encode the current environment state, and goal-conditioned spatial attention to predict the appropriate tool. We find that providing metric and semantic properties of objects, and pre-trained object embeddings derived from a commonsense knowledge repository such as ConceptNet, significantly improves the model's ability to generalize to unseen tools. The model makes accurate and generalizable tool predictions. When compared to a graph neural network baseline, it achieves 14-27% accuracy improvement for predicting known tools from new world scenes, and 44-67% improvement in generalization for novel objects not encountered during training.
IMoJIE: Iterative Memory-Based Joint Open Information Extraction
May 17, 2020
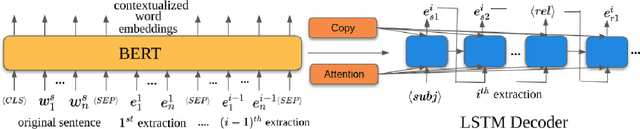


While traditional systems for Open Information Extraction were statistical and rule-based, recently neural models have been introduced for the task. Our work builds upon CopyAttention, a sequence generation OpenIE model (Cui et. al., 2018). Our analysis reveals that CopyAttention produces a constant number of extractions per sentence, and its extracted tuples often express redundant information. We present IMoJIE, an extension to CopyAttention, which produces the next extraction conditioned on all previously extracted tuples. This approach overcomes both shortcomings of CopyAttention, resulting in a variable number of diverse extractions per sentence. We train IMoJIE on training data bootstrapped from extractions of several non-neural systems, which have been automatically filtered to reduce redundancy and noise. IMoJIE outperforms CopyAttention by about 18 F1 pts, and a BERT-based strong baseline by 2 F1 pts, establishing a new state of the art for the task.