 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiSCoMaT: Distantly Supervised Composition Extraction from Tables in Materials Science Articles
Jul 10, 2022

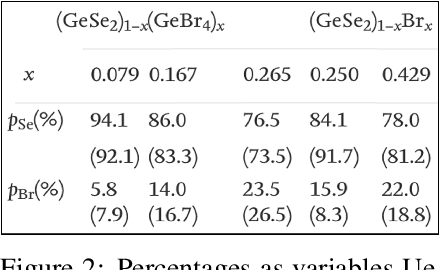
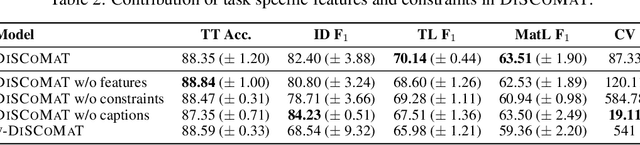
A crucial component in the curation of KB for a scientific domain is information extraction from tables in the domain's published articles -- tables carry important information (often numeric), which must be adequately extracted for a comprehensive machine understanding of an article. Existing table extractors assume prior knowledge of table structure and format, which may not be known in scientific tables. We study a specific and challenging table extraction problem: extracting compositions of materials (e.g., glasses, alloys). We first observe that materials science researchers organize similar compositions in a wide variety of table styles, necessitating an intelligent model for table understanding and composition extraction. Consequently, we define this novel task as a challenge for the ML community and create a training dataset comprising 4,408 distantly supervised tables, along with 1,475 manually annotated dev and test tables. We also present DiSCoMaT, a strong baseline geared towards this specific task, which combines multiple graph neural networks with several task-specific regular expressions, features, and constraints. We show that DiSCoMaT outperforms recent table processing architectures by significant margins.
ToolTango: Common sense Generalization in Predicting Sequential Tool Interactions for Robot Plan Synthesis
Jun 18, 2022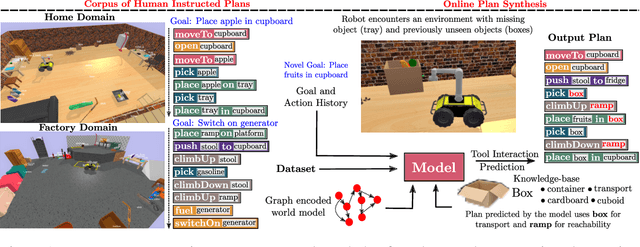
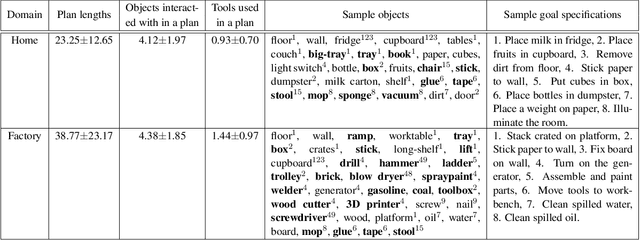
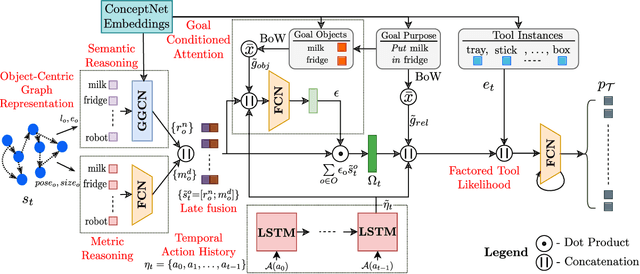

Robots assisting us in environments such as factories or homes must learn to make use of objects as tools to perform tasks, for instance using a tray to carry objects. We consider the problem of learning commonsense knowledge of when a tool may be useful and how its use may be composed with other tools to accomplish a high-level task instructed by a human. Specifically, we introduce a novel neural model, termed TOOLTANGO, that first predicts the next tool to be used, and then uses this information to predict the next action. We show that this joint model can inform learning of a fine-grained policy enabling the robot to use a particular tool in sequence and adds a significant value in making the model more accurate. TOOLTANGO encodes the world state, comprising objects and symbolic relationships between them, using a graph neural network and is trained using demonstrations from human teachers instructing a virtual robot in a physics simulator. The model learns to attend over the scene using knowledge of the goal and the action history, finally decoding the symbolic action to execute. Crucially, we address generalization to unseen environments where some known tools are missing, but alternative unseen tools are present. We show that by augmenting the representation of the environment with pre-trained embeddings derived from a knowledge-base, the model can generalize effectively to novel environments. Experimental results show at least 48.8-58.1% absolute improvement over the baselines in predicting successful symbolic plans for a simulated mobile manipulator in novel environments with unseen objects. This work takes a step in the direction of enabling robots to rapidly synthesize robust plans for complex tasks, particularly in novel settings
GoalNet: Inferring Conjunctive Goal Predicates from Human Plan Demonstrations for Robot Instruction Following
May 14, 2022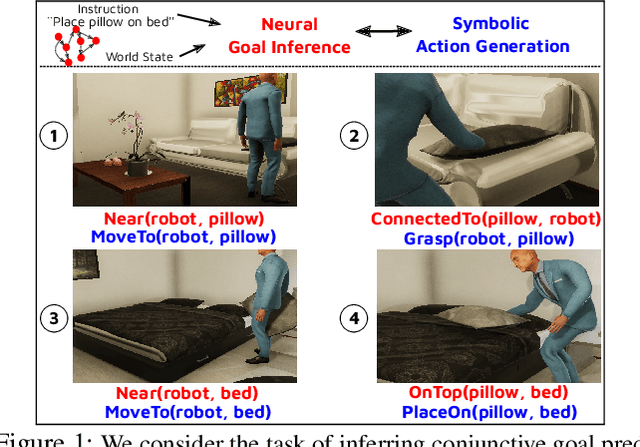

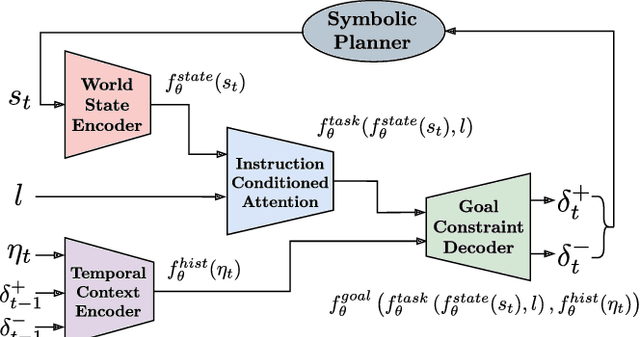
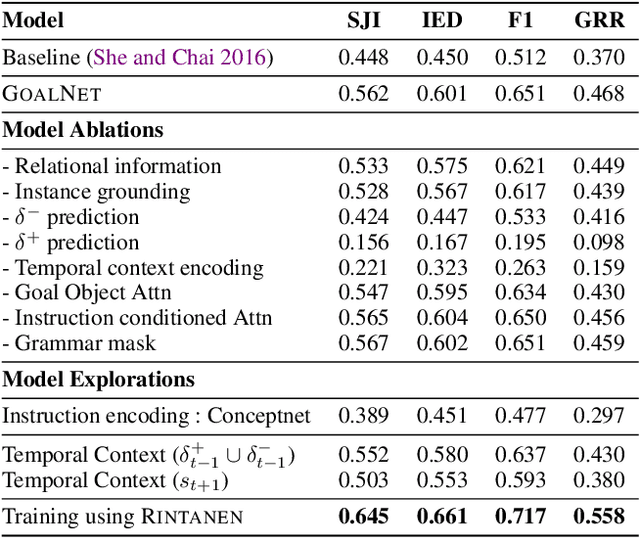
Our goal is to enable a robot to learn how to sequence its actions to perform tasks specified as natural language instructions, given successful demonstrations from a human partner. The ability to plan high-level tasks can be factored as (i) inferring specific goal predicates that characterize the task implied by a language instruction for a given world state and (ii) synthesizing a feasible goal-reaching action-sequence with such predicates. For the former, we leverage a neural network prediction model, while utilizing a symbolic planner for the latter. We introduce a novel neuro-symbolic model, GoalNet, for contextual and task dependent inference of goal predicates from human demonstrations and linguistic task descriptions. GoalNet combines (i) learning, where dense representations are acquired for language instruction and the world state that enables generalization to novel settings and (ii) planning, where the cause-effect modeling by the symbolic planner eschews irrelevant predicates facilitating multi-stage decision making in large domains. GoalNet demonstrates a significant improvement (51%) in the task completion rate in comparison to a state-of-the-art rule-based approach on a benchmark data set displaying linguistic variations, particularly for multi-stage instructions.
Matching Papers and Reviewers at Large Conferences
Mar 02, 2022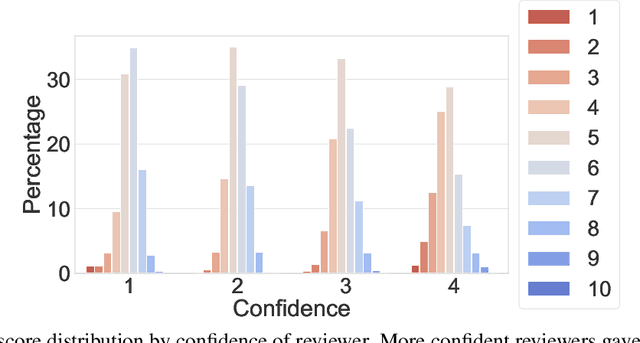

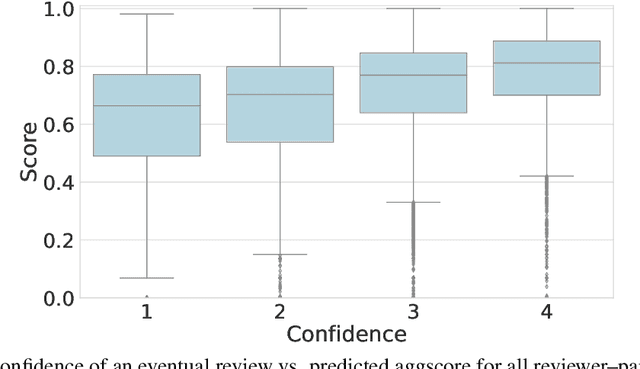

This paper studies a novel reviewer-paper matching approach that was recently deployed in the 35th AAAI Conference on Artificial Intelligence (AAAI 2021), and has since been adopted by other conferences including AAAI 2022 and ICML 2022. This approach has three main elements: (1) collecting and processing input data to identify problematic matches and generate reviewer-paper scores; (2) formulating and solving an optimization problem to find good reviewer-paper matchings; and (3) the introduction of a novel, two-phase reviewing process that shifted reviewing resources away from papers likely to be rejected and towards papers closer to the decision boundary. This paper also describes an evaluation of these innovations based on an extensive post-hoc analysis on real data -- including a comparison with the matching algorithm used in AAAI's previous (2020) iteration -- and supplements this with additional numerical experimentation.
Neural Models for Output-Space Invariance in Combinatorial Problems
Feb 07, 2022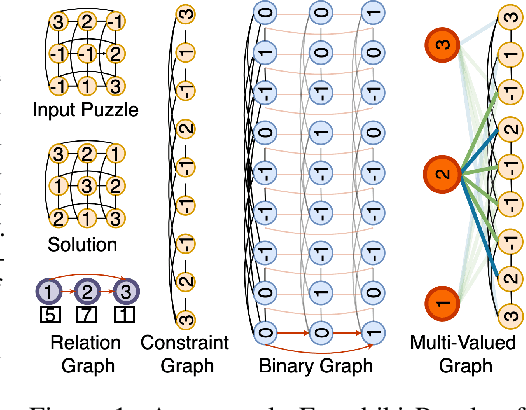
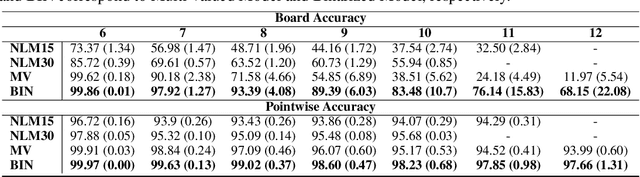
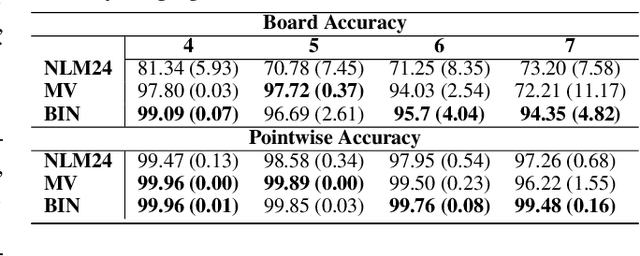
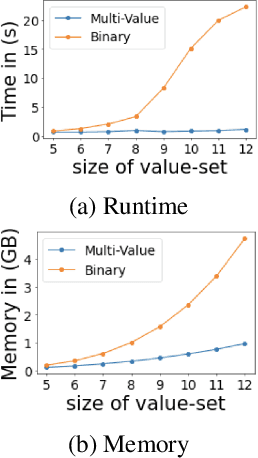
Recently many neural models have been proposed to solve combinatorial puzzles by implicitly learning underlying constraints using their solved instances, such as sudoku or graph coloring (GCP). One drawback of the proposed architectures, which are often based on Graph Neural Networks (GNN), is that they cannot generalize across the size of the output space from which variables are assigned a value, for example, set of colors in a GCP, or board-size in sudoku. We call the output space for the variables as 'value-set'. While many works have demonstrated generalization of GNNs across graph size, there has been no study on how to design a GNN for achieving value-set invariance for problems that come from the same domain. For example, learning to solve 16 x 16 sudoku after being trained on only 9 x 9 sudokus. In this work, we propose novel methods to extend GNN based architectures to achieve value-set invariance. Specifically, our model builds on recently proposed Recurrent Relational Networks. Our first approach exploits the graph-size invariance of GNNs by converting a multi-class node classification problem into a binary node classification problem. Our second approach works directly with multiple classes by adding multiple nodes corresponding to the values in the value-set, and then connecting variable nodes to value nodes depending on the problem initialization. Our experimental evaluation on three different combinatorial problems demonstrates that both our models perform well on our novel problem, compared to a generic neural reasoner. Between two of our models, we observe an inherent trade-off: while the binarized model gives better performance when trained on smaller value-sets, multi-valued model is much more memory efficient, resulting in improved performance when trained on larger value-sets, where binarized model fails to train.
A Simple, Strong and Robust Baseline for Distantly Supervised Relation Extraction
Oct 14, 2021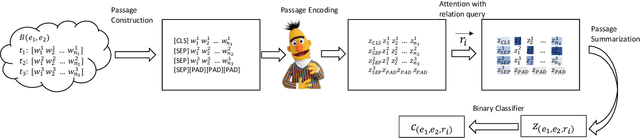
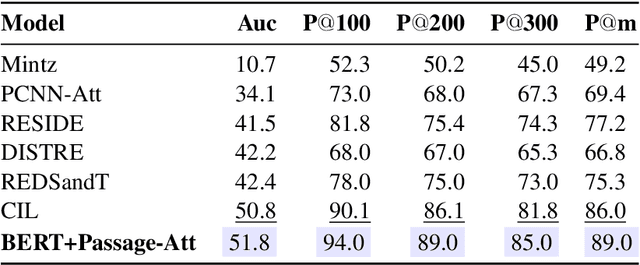
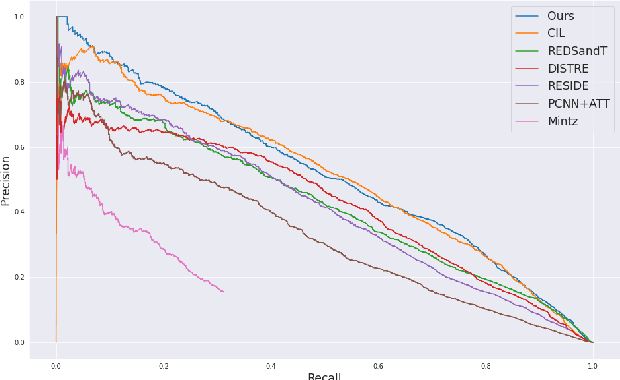

Distantly supervised relation extraction (DS-RE) is generally framed as a multi-instance multi-label (MI-ML) task, where the optimal aggregation of information from multiple instances is of key importance. Intra-bag attention (Lin et al., 2016) is an example of a popularly used aggregation scheme for this framework. Apart from this scheme, however, there is not much to choose from in the DS-RE literature as most of the advances in this field are focused on improving the instance-encoding step rather than the instance-aggregation step. With recent works leveraging large pre-trained language models as encoders, the increased capacity of models might allow for more flexibility in the instance-aggregation step. In this work, we explore this hypothesis and come up with a novel aggregation scheme which we call Passage-Att. Under this aggregation scheme, we combine all instances mentioning an entity pair into a "passage of instances", which is summarized independently for each relation class. These summaries are used to predict the validity of a potential triple. We show that our Passage-Att with BERT as passage encoder achieves state-of-the-art performance in three different settings (monolingual DS, monolingual DS with manually-annotated test set, multilingual DS).
MatSciBERT: A Materials Domain Language Model for Text Mining and Information Extraction
Sep 30, 2021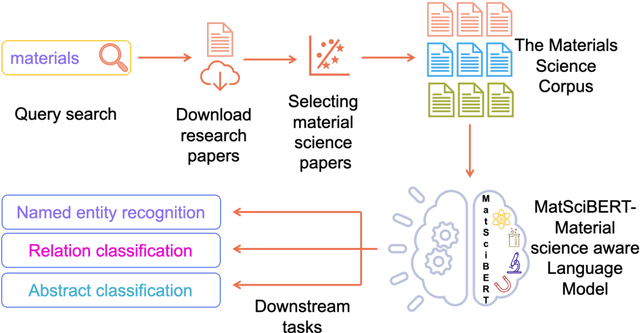
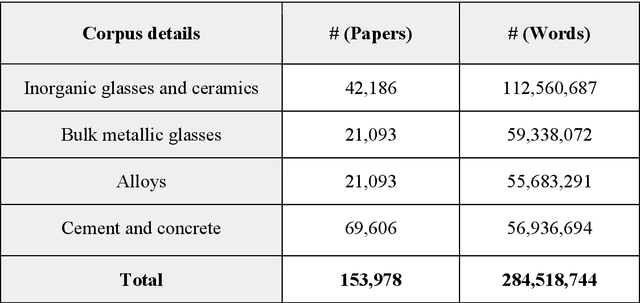
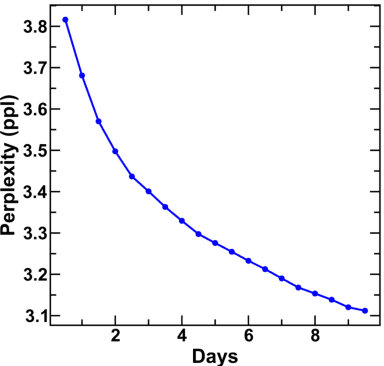
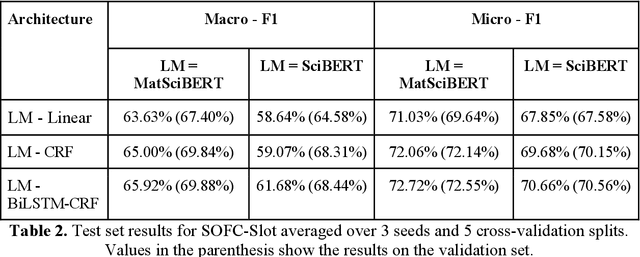
An overwhelmingly large amount of knowledge in the materials domain is generated and stored as text published in peer-reviewed scientific literature. Recent developments in natural language processing, such as bidirectional encoder representations from transformers (BERT) models, provide promising tools to extract information from these texts. However, direct application of these models in the materials domain may yield suboptimal results as the models themselves may not be trained on notations and jargon that are specific to the domain. Here, we present a materials-aware language model, namely, MatSciBERT, which is trained on a large corpus of scientific literature published in the materials domain. We further evaluate the performance of MatSciBERT on three downstream tasks, namely, abstract classification, named entity recognition, and relation extraction, on different materials datasets. We show that MatSciBERT outperforms SciBERT, a language model trained on science corpus, on all the tasks. Further, we discuss some of the applications of MatSciBERT in the materials domain for extracting information, which can, in turn, contribute to materials discovery or optimization. Finally, to make the work accessible to the larger materials community, we make the pretrained and finetuned weights and the models of MatSciBERT freely accessible.
Constraint based Knowledge Base Distillation in End-to-End Task Oriented Dialogs
Sep 15, 2021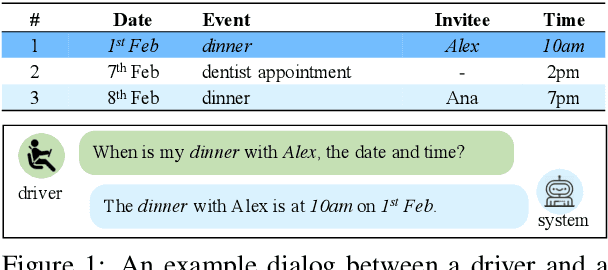

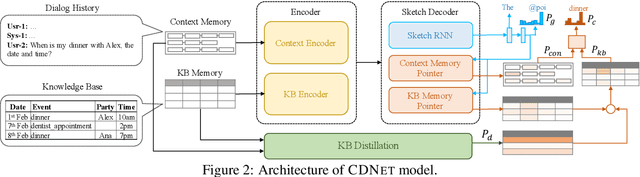
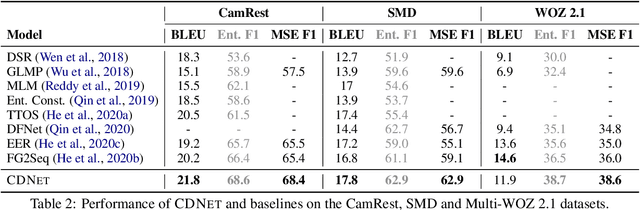
End-to-End task-oriented dialogue systems generate responses based on dialog history and an accompanying knowledge base (KB). Inferring those KB entities that are most relevant for an utterance is crucial for response generation. Existing state of the art scales to large KBs by softly filtering over irrelevant KB information. In this paper, we propose a novel filtering technique that consists of (1) a pairwise similarity based filter that identifies relevant information by respecting the n-ary structure in a KB record. and, (2) an auxiliary loss that helps in separating contextually unrelated KB information. We also propose a new metric -- multiset entity F1 which fixes a correctness issue in the existing entity F1 metric. Experimental results on three publicly available task-oriented dialog datasets show that our proposed approach outperforms existing state-of-the-art models.
End-to-End Learning of Flowchart Grounded Task-Oriented Dialogs
Sep 15, 2021
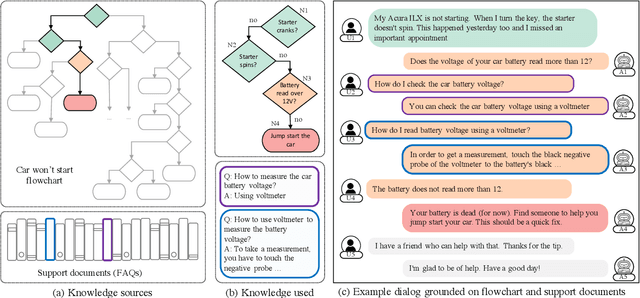
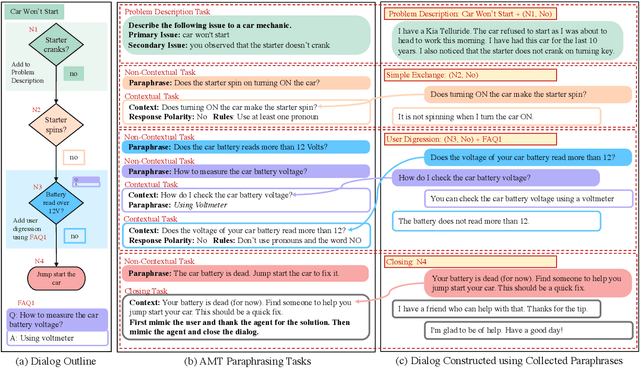
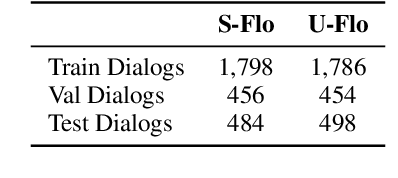
We propose a novel problem within end-to-end learning of task-oriented dialogs (TOD), in which the dialog system mimics a troubleshooting agent who helps a user by diagnosing their problem (e.g., car not starting). Such dialogs are grounded in domain-specific flowcharts, which the agent is supposed to follow during the conversation. Our task exposes novel technical challenges for neural TOD, such as grounding an utterance to the flowchart without explicit annotation, referring to additional manual pages when user asks a clarification question, and ability to follow unseen flowcharts at test time. We release a dataset (FloDial) consisting of 2,738 dialogs grounded on 12 different troubleshooting flowcharts. We also design a neural model, FloNet, which uses a retrieval-augmented generation architecture to train the dialog agent. Our experiments find that FloNet can do zero-shot transfer to unseen flowcharts, and sets a strong baseline for future research.
Contrastive Semi-Supervised Learning for 2D Medical Image Segmentation
Jul 10, 2021



Contrastive Learning (CL) is a recent representation learning approach, which encourages inter-class separability and intra-class compactness in learned image representations. Since medical images often contain multiple semantic classes in an image, using CL to learn representations of local features (as opposed to global) is important. In this work, we present a novel semi-supervised 2D medical segmentation solution that applies CL on image patches, instead of full images. These patches are meaningfully constructed using the semantic information of different classes obtained via pseudo labeling. We also propose a novel consistency regularization (CR) scheme, which works in synergy with CL. It addresses the problem of confirmation bias, and encourages better clustering in the feature space. We evaluate our method on four public medical segmentation datasets and a novel histopathology dataset that we introduce. Our method obtains consistent improvements over state-of-the-art semi-supervised segmentation approaches for all datasets.