 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance-Weighted Graph Neural Networks on FPGAs for Real-Time Particle Reconstruction in High Energy Physics
Aug 08, 2020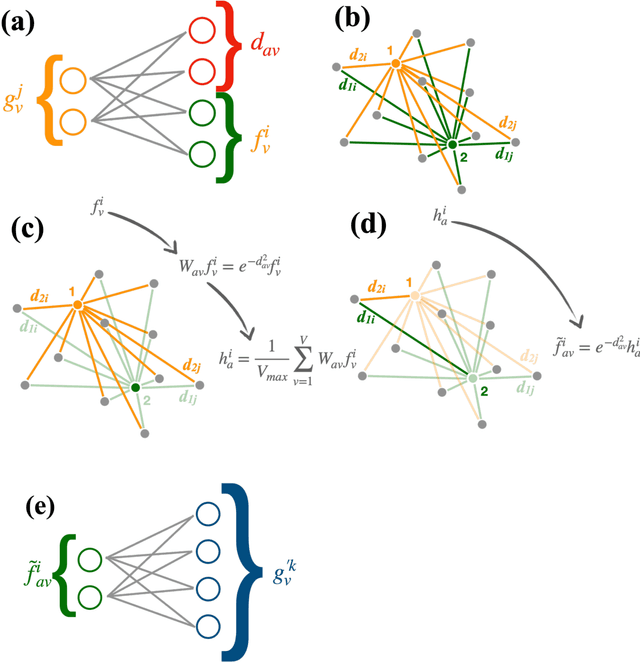


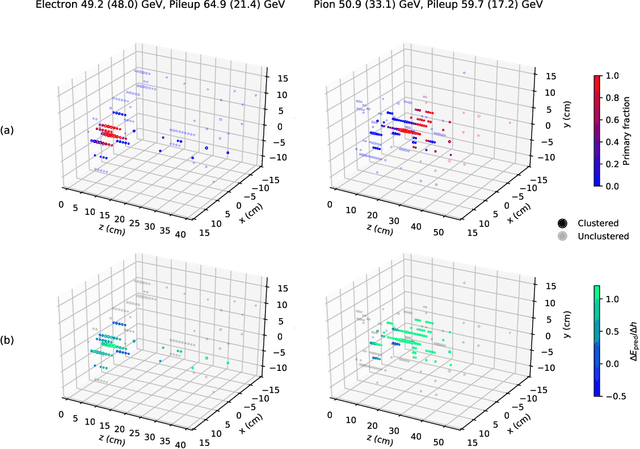
Graph neural networks have been shown to achieve excellent performance for several crucial tasks in particle physics, such as charged particle tracking, jet tagging, and clustering. An important domain for the application of these networks is the FGPA-based first layer of real-time data filtering at the CERN Large Hadron Collider, which has strict latency and resource constraints. We discuss how to design distance-weighted graph networks that can be executed with a latency of less than 1$\mu\mathrm{s}$ on an FPGA. To do so, we consider a representative task associated to particle reconstruction and identification in a next-generation calorimeter operating at a particle collider. We use a graph network architecture developed for such purposes, and apply additional simplifications to match the computing constraints of Level-1 trigger systems, including weight quantization. Using the $\mathtt{hls4ml}$ library, we convert the compressed models into firmware to be implemented on an FPGA. Performance of the synthesized models is presented both in terms of inference accuracy and resource usage.
Ultra Low-latency, Low-area Inference Accelerators using Heterogeneous Deep Quantization with QKeras and hls4ml
Jun 15, 2020



In this paper, we introduce the QKeras library, an extension of the Keras library allowing for the creation of heterogeneously quantized versions of deep neural network models, through drop-in replacement of Keras layers. These models are trained quantization-aware, where the user can trade off model area or energy consumption by accuracy. We demonstrate how the reduction of numerical precision, through quantization-aware training, significantly reduces resource consumption while retaining high accuracy when implemented on FPGA hardware. Together with the hls4ml library, this allows for a fully automated deployment of quantized Keras models on chip, crucial for ultra low-latency inference. As a benchmark problem, we consider a classification task for the triggering of events in proton-proton collisions at the CERN Large Hadron Collider, where a latency of ${\mathcal O}(1)~\mu$s is required.
Adversarially Learned Anomaly Detection on CMS Open Data: re-discovering the top quark
May 04, 2020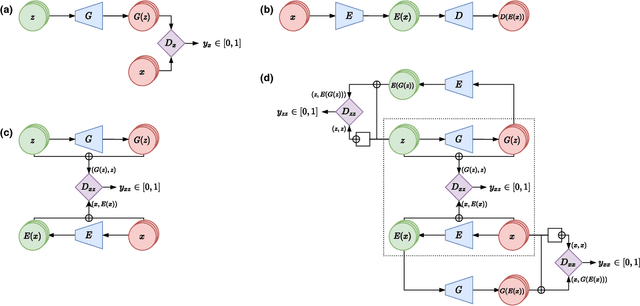
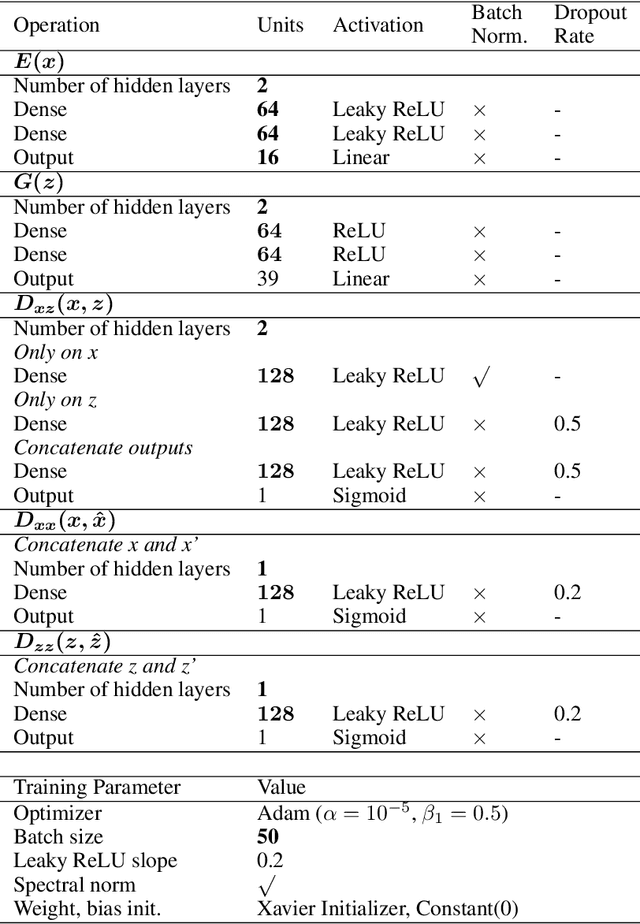
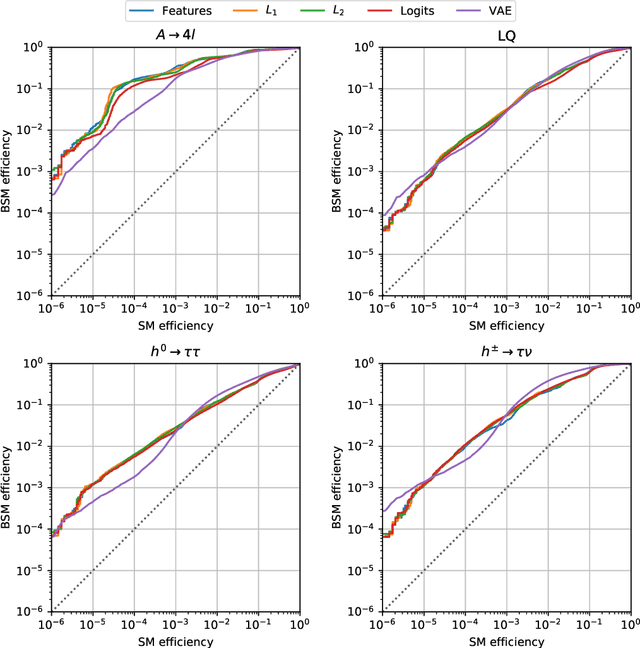
We apply an Adversarially Learned Anomaly Detection (ALAD) algorithm to the problem of detecting new physics processes in proton-proton collisions at the Large Hadron Collider. Anomaly detection based on ALAD matches performances reached by Variational Autoencoders, with a substantial improvement in some cases. Training the ALAD algorithm on 4.4 fb-1 of 8 TeV CMS Open Data, we show how a data-driven anomaly detection and characterization would work in real life, re-discovering the top quark by identifying the main features of the t-tbar experimental signature at the LHC.
Compressing deep neural networks on FPGAs to binary and ternary precision with HLS4ML
Mar 11, 2020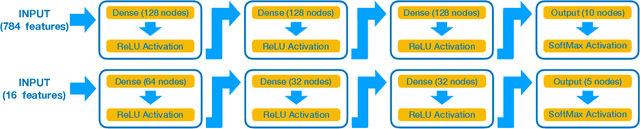
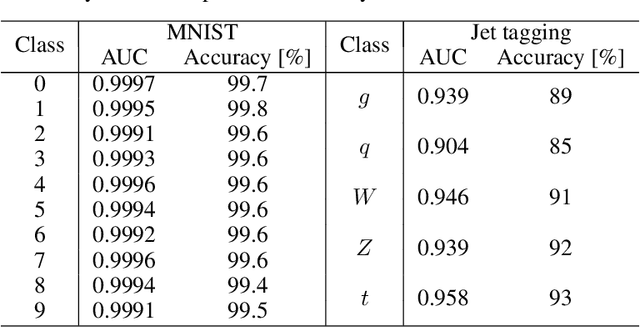
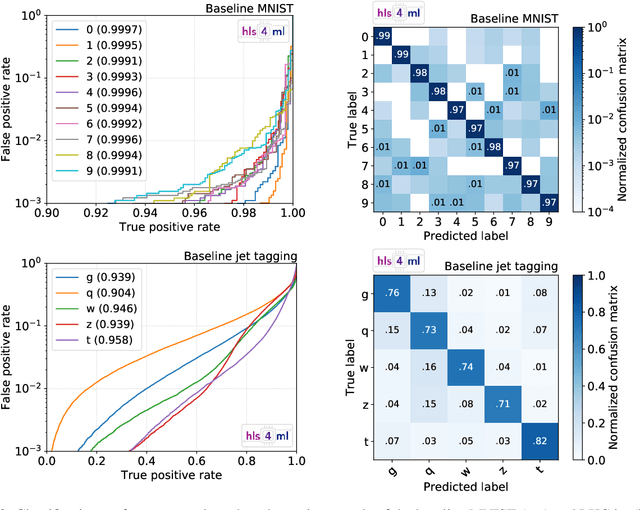

We present the implementation of binary and ternary neural networks in the hls4ml library, designed to automatically convert deep neural network models to digital circuits with FPGA firmware. Starting from benchmark models trained with floating point precision, we investigate different strategies to reduce the network's resource consumption by reducing the numerical precision of the network parameters to binary or ternary. We discuss the trade-off between model accuracy and resource consumption. In addition, we show how to balance between latency and accuracy by retaining full precision on a selected subset of network components. As an example, we consider two multiclass classification tasks: handwritten digit recognition with the MNIST data set and jet identification with simulated proton-proton collisions at the CERN Large Hadron Collider. The binary and ternary implementation has similar performance to the higher precision implementation while using drastically fewer FPGA resources.
Fast inference of Boosted Decision Trees in FPGAs for particle physics
Feb 19, 2020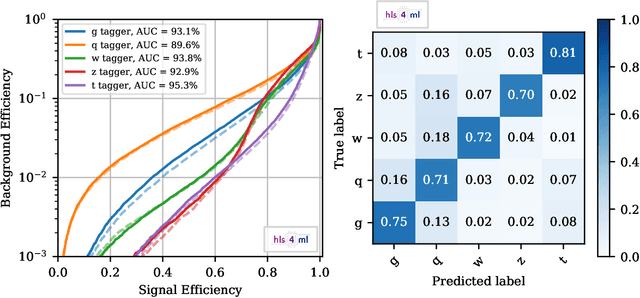

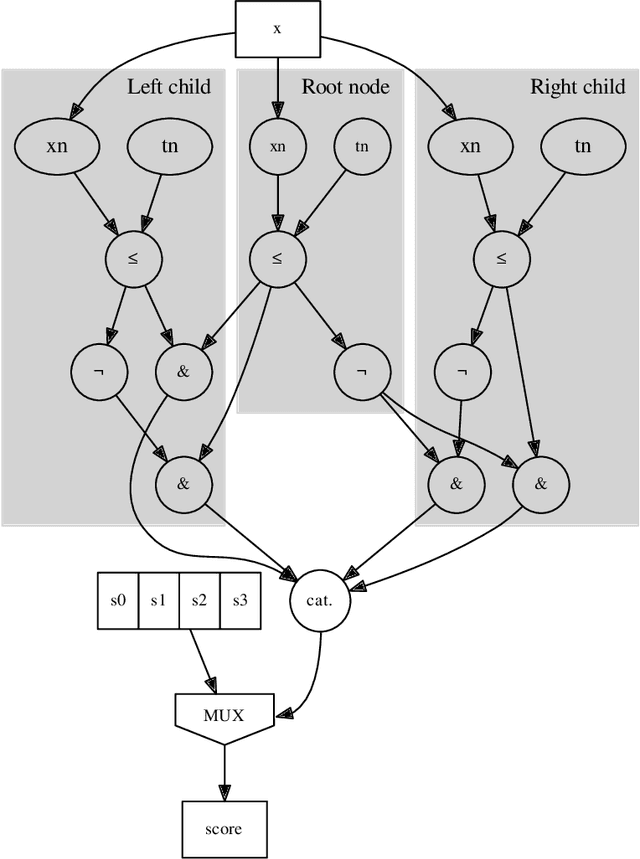
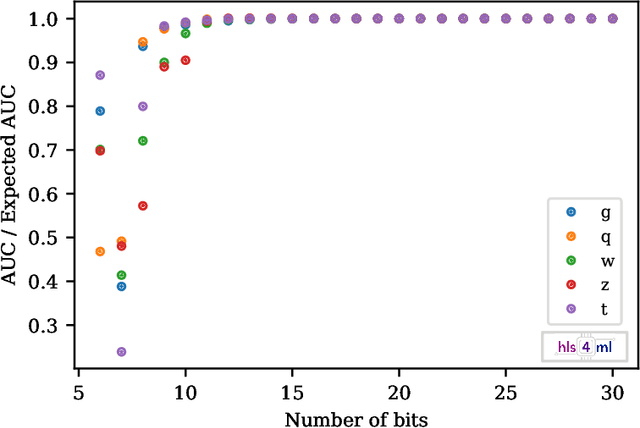
We describe the implementation of Boosted Decision Trees in the hls4ml library, which allows the translation of a trained model into FPGA firmware through an automated conversion process. Thanks to its fully on-chip implementation, hls4ml performs inference of Boosted Decision Tree models with extremely low latency. With a typical latency less than 100 ns, this solution is suitable for FPGA-based real-time processing, such as in the Level-1 Trigger system of a collider experiment. These developments open up prospects for physicists to deploy BDTs in FPGAs for identifying the origin of jets, better reconstructing the energies of muons, and enabling better selection of rare signal processes.
Calorimetry with Deep Learning: Particle Simulation and Reconstruction for Collider Physics
Jan 08, 2020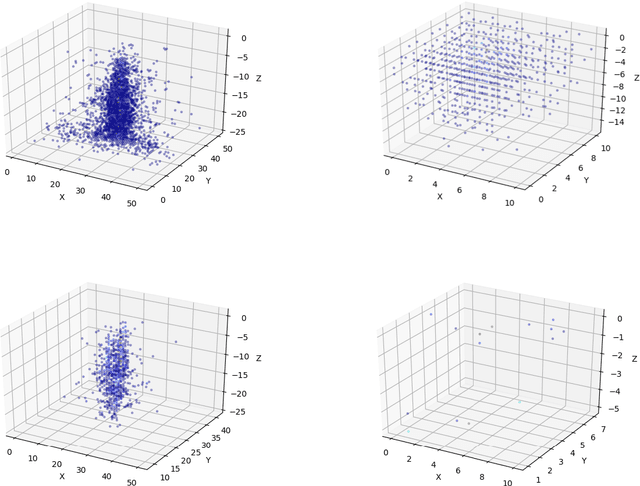
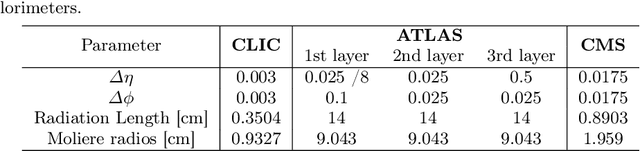
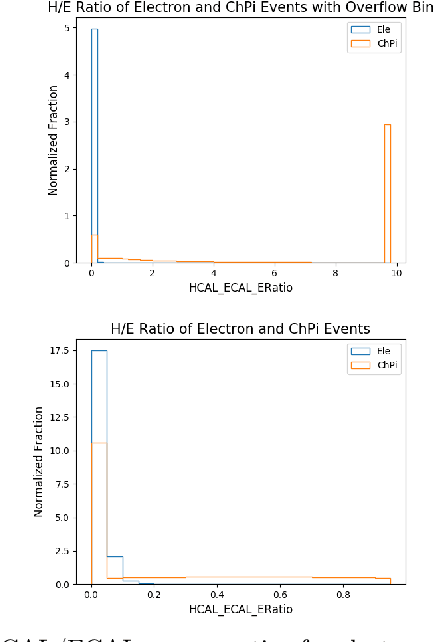
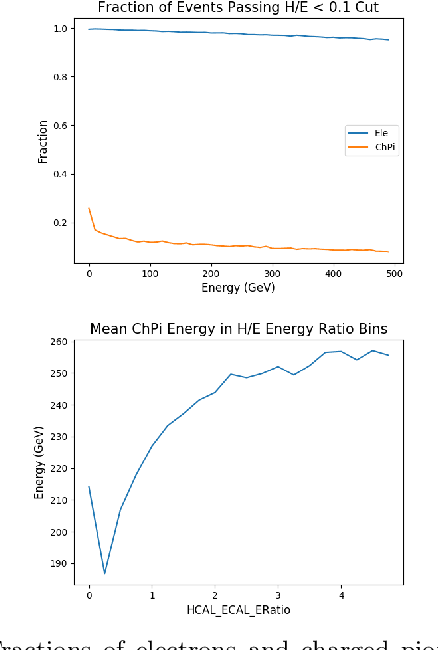
Using detailed simulations of calorimeter showers as training data, we investigate the use of deep learning algorithms for the simulation and reconstruction of particles produced in high-energy physics collisions. We train neural networks on shower data at the calorimeter-cell level, and show significant improvements for simulation and reconstruction when using these networks compared to methods which rely on currently-used state-of-the-art algorithms. We define two models: an end-to-end reconstruction network which performs simultaneous particle identification and energy regression of particles when given calorimeter shower data, and a generative network which can provide reasonable modeling of calorimeter showers for different particle types at specified angles and energies. We investigate the optimization of our models with hyperparameter scans. Furthermore, we demonstrate the applicability of the reconstruction model to shower inputs from other detector geometries, specifically ATLAS-like and CMS-like geometries. These networks can serve as fast and computationally light methods for particle shower simulation and reconstruction for current and future experiments at particle colliders.
Learning representations of irregular particle-detector geometry with distance-weighted graph networks
Feb 21, 2019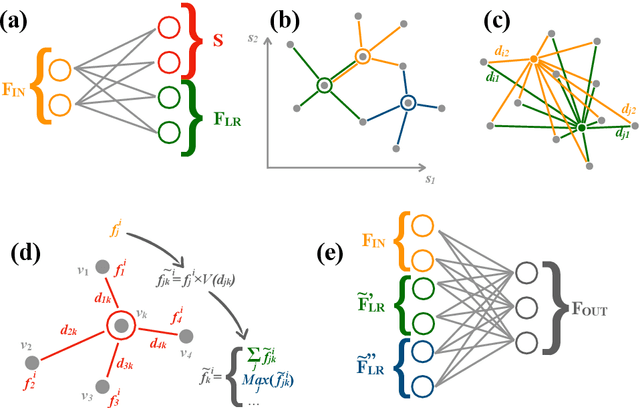
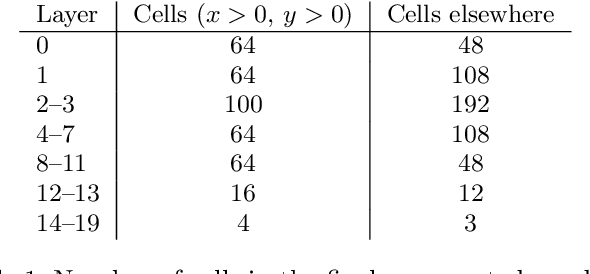
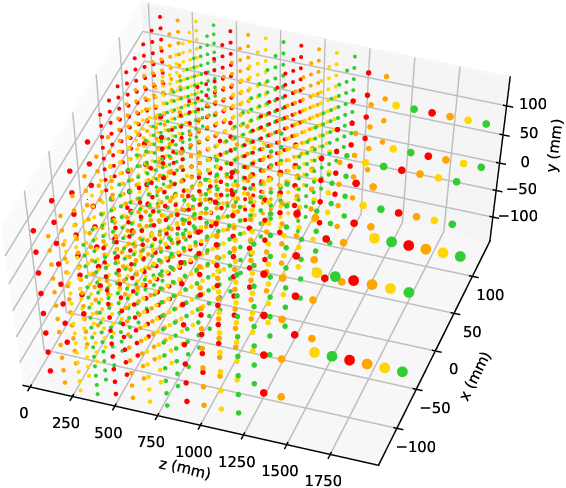
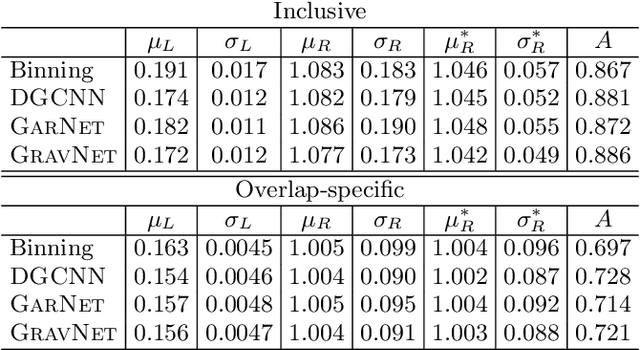
We explore the use of graph networks to deal with irregular-geometry detectors in the context of particle reconstruction. Thanks to their representation-learning capabilities, graph networks can exploit the full detector granularity, while natively managing the event sparsity and arbitrarily complex detector geometries. We introduce two distance-weighted graph network architectures, dubbed GarNet and GravNet layers, and apply them to a typical particle reconstruction task. The performance of the new architectures is evaluated on a data set of simulated particle interactions on a toy model of a highly granular calorimeter, loosely inspired by the endcap calorimeter to be installed in the CMS detector for the High-Luminosity LHC phase. We study the clustering of energy depositions, which is the basis for calorimetric particle reconstruction, and provide a quantitative comparison to alternative approaches. The proposed algorithms outperform existing methods or reach competitive performance with lower computing-resource consumption. Being geometry-agnostic, the new architectures are not restricted to calorimetry and can be easily adapted to other use cases, such as tracking in silicon detectors.
LHC analysis-specific datasets with Generative Adversarial Networks
Jan 16, 2019
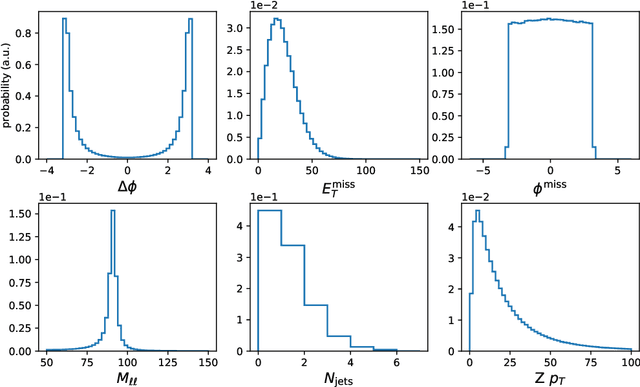
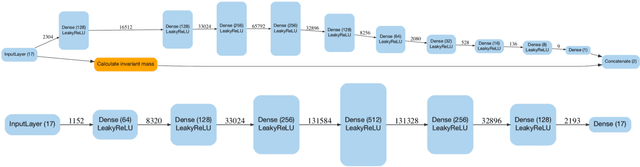
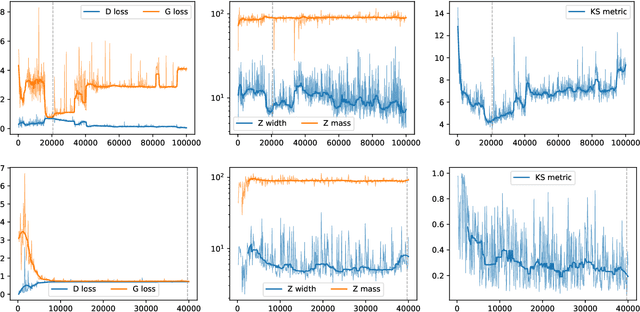
Using generative adversarial networks (GANs), we investigate the possibility of creating large amounts of analysis-specific simulated LHC events at limited computing cost. This kind of generative model is analysis specific in the sense that it directly generates the high-level features used in the last stage of a given physics analyses, learning the N-dimensional distribution of relevant features in the context of a specific analysis selection. We apply this idea to the generation of muon four-momenta in $Z \to \mu\mu$ events at the LHC. We highlight how use-case specific issues emerge when the distributions of the considered quantities exhibit particular features. We show how substantial performance improvements and convergence speed-up can be obtained by including regression terms in the loss function of the generator. We develop an objective criterion to assess the geenrator performance in a quantitative way. With further development, a generalization of this approach could substantially reduce the needed amount of centrally produced fully simulated events in large particle physics experiments.
Variational Autoencoders for New Physics Mining at the Large Hadron Collider
Dec 05, 2018
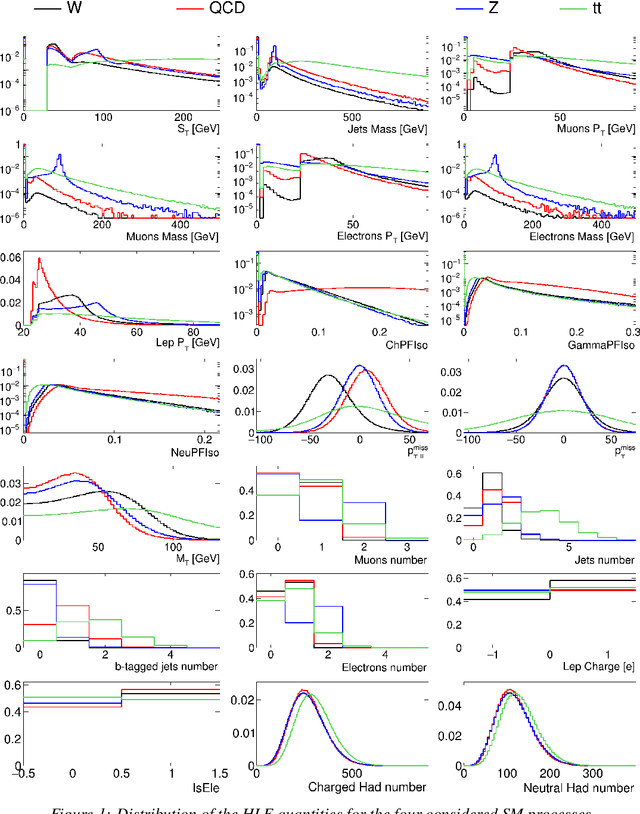
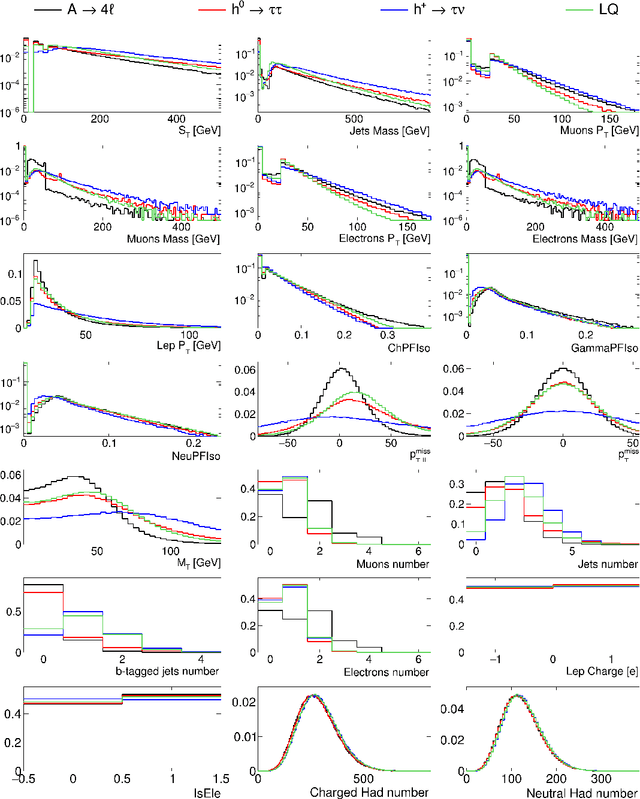
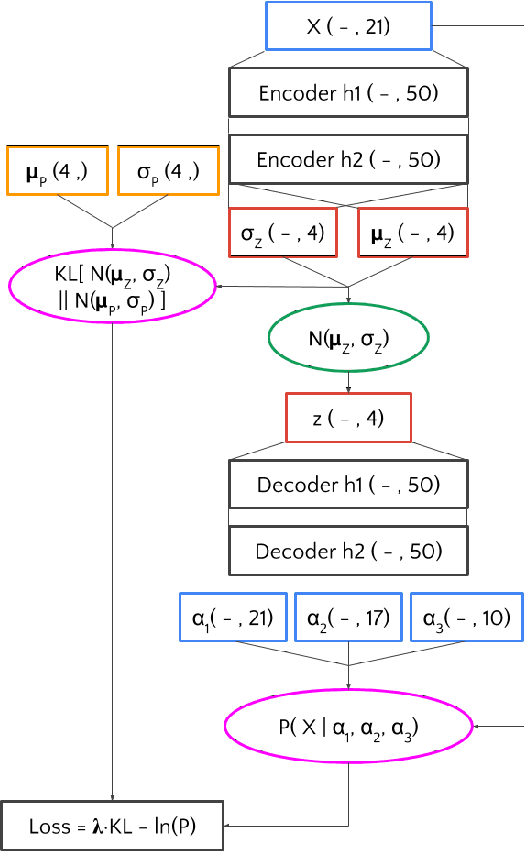
Using variational autoencoders trained on known physics processes, we develop a one-side p-value test to isolate previously unseen processes as outlier events. Since the autoencoder training does not depend on any specific new physics signature, the proposed procedure has a weak dependence on underlying assumptions about the nature of new physics. An event selection based on this algorithm would be complementary to classic LHC searches, typically based on model-dependent hypothesis testing. Such an algorithm would deliver a list of anomalous events, that the experimental collaborations could further scrutinize and even release as a catalog, similarly to what is typically done in other scientific domains. Repeated patterns in this dataset could motivate new scenarios for beyond-the-standard-model physics and inspire new searches, to be performed on future data with traditional supervised approaches. Running in the trigger system of the LHC experiments, such an application could identify anomalous events that would be otherwise lost, extending the scientific reach of the LHC.
Topology classification with deep learning to improve real-time event selection at the LHC
Aug 01, 2018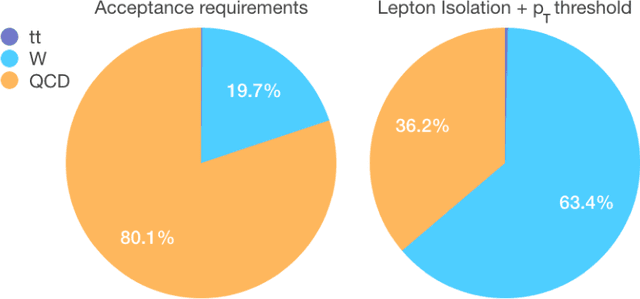
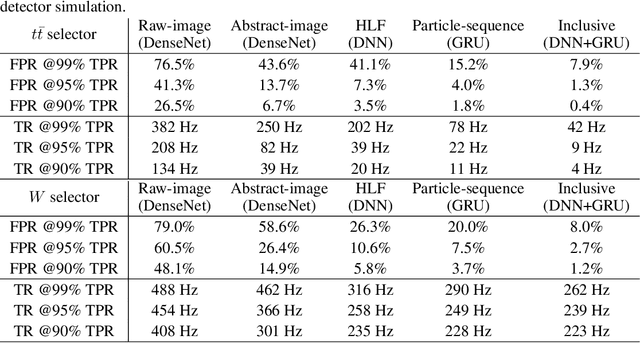
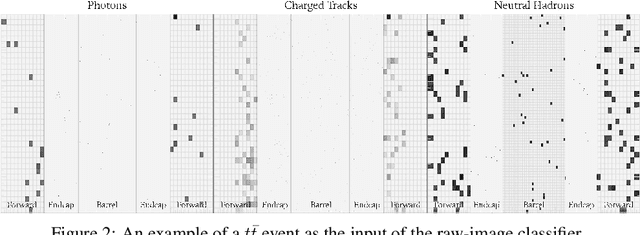
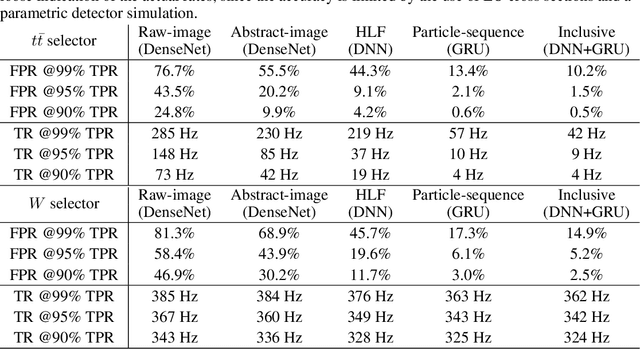
We show how event topology classification based on deep learning could be used to improve the purity of data samples selected in real time at at the Large Hadron Collider. We consider different data representations, on which different kinds of multi-class classifiers are trained. Both raw data and high-level features are utilized. In the considered examples, a filter based on the classifier's score can be trained to retain ~99% of the interesting events and reduce the false-positive rate by as much as one order of magnitude for certain background processes. By operating such a filter as part of the online event selection infrastructure of the LHC experiments, one could benefit from a more flexible and inclusive selection strategy while reducing the amount of downstream resources wasted in processing false positives. The saved resources could be translated into a reduction of the detector operation cost or into an effective increase of storage and processing capabilities, which could be reinvested to extend the physics reach of the LHC experiments.