 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA gradual, semi-discrete approach to generative network training via explicit Wasserstein minimization
Jun 11, 2019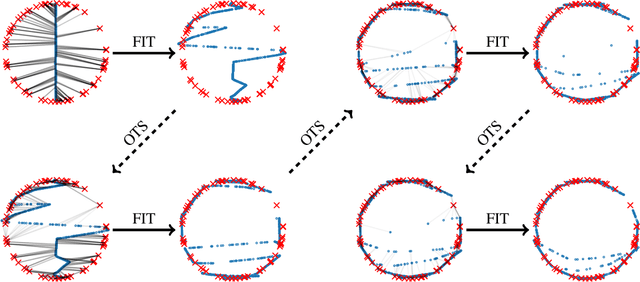
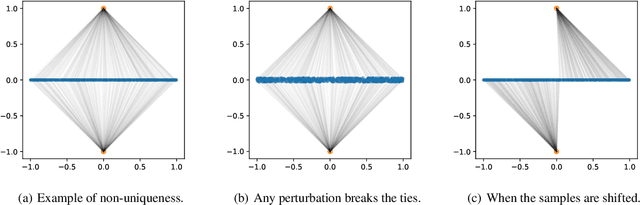
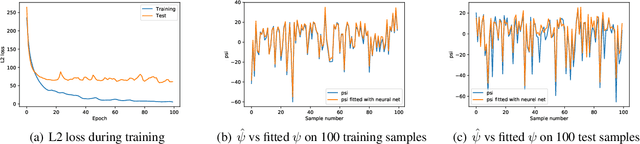
This paper provides a simple procedure to fit generative networks to target distributions, with the goal of a small Wasserstein distance (or other optimal transport costs). The approach is based on two principles: (a) if the source randomness of the network is a continuous distribution (the "semi-discrete" setting), then the Wasserstein distance is realized by a deterministic optimal transport mapping; (b) given an optimal transport mapping between a generator network and a target distribution, the Wasserstein distance may be decreased via a regression between the generated data and the mapped target points. The procedure here therefore alternates these two steps, forming an optimal transport and regressing against it, gradually adjusting the generator network towards the target distribution. Mathematically, this approach is shown to minimize the Wasserstein distance to both the empirical target distribution, and also its underlying population counterpart. Empirically, good performance is demonstrated on the training and testing sets of the MNIST and Thin-8 data. The paper closes with a discussion of the unsuitability of the Wasserstein distance for certain tasks, as has been identified in prior work [Arora et al., 2017, Huang et al., 2017].
A refined primal-dual analysis of the implicit bias
Jun 11, 2019Recent work shows that gradient descent on linearly separable data is implicitly biased towards the maximum margin solution. However, no convergence rate which is tight in both n (the dataset size) and t (the training time) is given. This work proves that the normalized gradient descent iterates converge to the maximum margin solution at a rate of O(ln(n)/ ln(t)), which is tight in both n and t. The proof is via a dual convergence result: gradient descent induces a multiplicative weights update on the (normalized) SVM dual objective, whose convergence rate leads to the tight implicit bias rate.
Size-Noise Tradeoffs in Generative Networks
Oct 26, 2018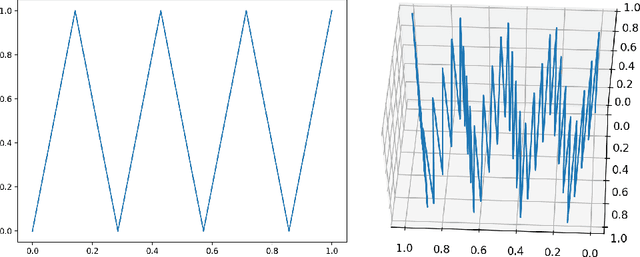
This paper investigates the ability of generative networks to convert their input noise distributions into other distributions. Firstly, we demonstrate a construction that allows ReLU networks to increase the dimensionality of their noise distribution by implementing a "space-filling" function based on iterated tent maps. We show this construction is optimal by analyzing the number of affine pieces in functions computed by multivariate ReLU networks. Secondly, we provide efficient ways (using polylog $(1/\epsilon)$ nodes) for networks to pass between univariate uniform and normal distributions, using a Taylor series approximation and a binary search gadget for computing function inverses. Lastly, we indicate how high dimensional distributions can be efficiently transformed into low dimensional distributions.
Social welfare and profit maximization from revealed preferences
Oct 06, 2018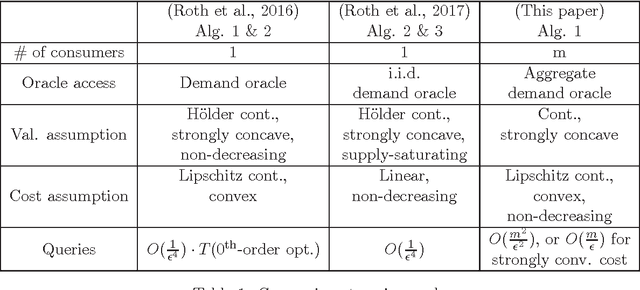
Consider the seller's problem of finding optimal prices for her $n$ (divisible) goods when faced with a set of $m$ consumers, given that she can only observe their purchased bundles at posted prices, i.e., revealed preferences. We study both social welfare and profit maximization with revealed preferences. Although social welfare maximization is a seemingly non-convex optimization problem in prices, we show that (i) it can be reduced to a dual convex optimization problem in prices, and (ii) the revealed preferences can be interpreted as supergradients of the concave conjugate of valuation, with which subgradients of the dual function can be computed. We thereby obtain a simple subgradient-based algorithm for strongly concave valuations and convex cost, with query complexity $O(m^2/\epsilon^2)$, where $\epsilon$ is the additive difference between the social welfare induced by our algorithm and the optimum social welfare. We also study social welfare maximization under the online setting, specifically the random permutation model, where consumers arrive one-by-one in a random order. For the case where consumer valuations can be arbitrary continuous functions, we propose a price posting mechanism that achieves an expected social welfare up to an additive factor of $O(\sqrt{mn})$ from the maximum social welfare. Finally, for profit maximization (which may be non-convex in simple cases), we give nearly matching upper and lower bounds on the query complexity for separable valuations and cost (i.e., each good can be treated independently).
Gradient descent aligns the layers of deep linear networks
Oct 04, 2018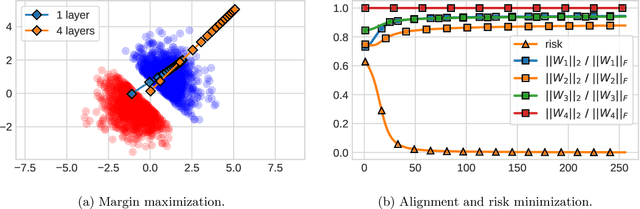
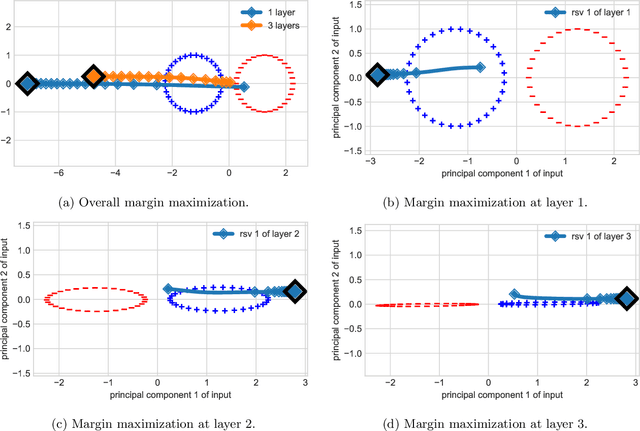
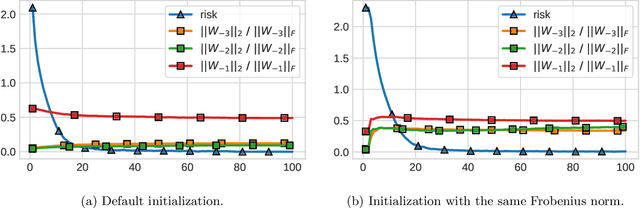
This paper establishes risk convergence and asymptotic weight matrix alignment --- a form of implicit regularization --- of gradient flow and gradient descent when applied to deep linear networks on linearly separable data. In more detail, for gradient flow applied to strictly decreasing loss functions (with similar results for gradient descent with particular decreasing step sizes): (i) the risk converges to 0; (ii) the normalized i-th weight matrix asymptotically equals its rank-1 approximation $u_iv_i^{\top}$; (iii) these rank-1 matrices are aligned across layers, meaning $|v_{i+1}^{\top}u_i|\to1$. In the case of the logistic loss (binary cross entropy), more can be said: the linear function induced by the network --- the product of its weight matrices --- converges to the same direction as the maximum margin solution. This last property was identified in prior work, but only under assumptions on gradient descent which here are implied by the alignment phenomenon.
Risk and parameter convergence of logistic regression
Jun 01, 2018
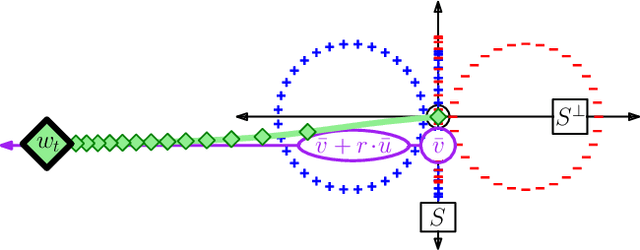
The logistic loss is strictly convex and does not attain its infimum; consequently the solutions of logistic regression are in general off at infinity. This work provides a convergence analysis of stochastic and batch gradient descent for logistic regression. Firstly, under the assumption of separability, stochastic gradient descent minimizes the population risk at rate $\mathcal{O}(\ln(t)^2/t)$ with high probability. Secondly, with or without separability, batch gradient descent minimizes the empirical risk at rate $\mathcal{O}(\ln(t)^2/t)$. Furthermore, parameter convergence can be characterized along a unique pair of complementary subspaces defined by the problem instance: one subspace along which strong convexity induces parameters to converge at rate $\mathcal{O}(\ln(t)^2/\sqrt{t})$, and its orthogonal complement along which separability induces parameters to converge in direction at rate $\mathcal{O}(\ln\ln(t) / \ln(t))$.
Spectrally-normalized margin bounds for neural networks
Dec 05, 2017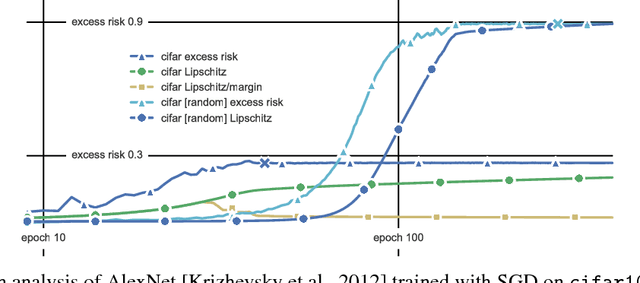
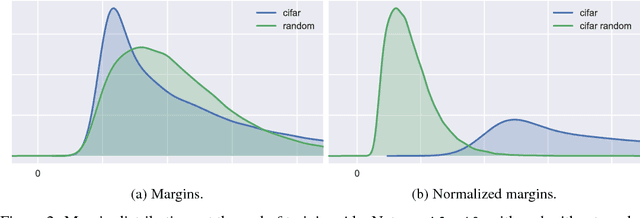
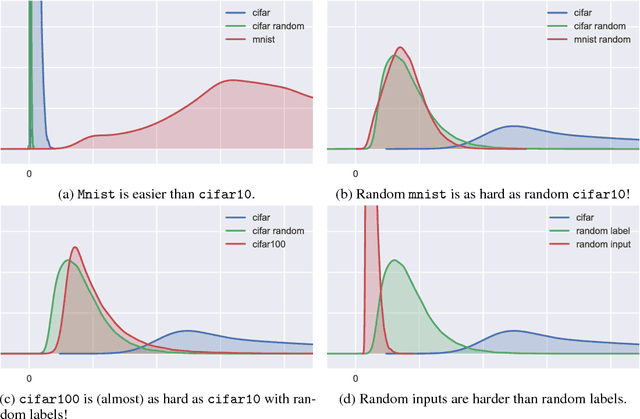
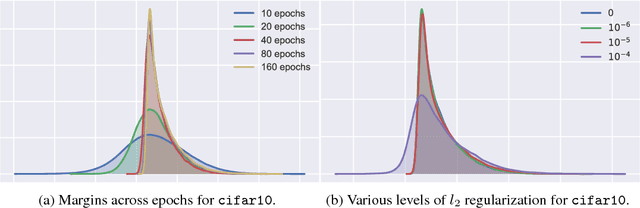
This paper presents a margin-based multiclass generalization bound for neural networks that scales with their margin-normalized "spectral complexity": their Lipschitz constant, meaning the product of the spectral norms of the weight matrices, times a certain correction factor. This bound is empirically investigated for a standard AlexNet network trained with SGD on the mnist and cifar10 datasets, with both original and random labels; the bound, the Lipschitz constants, and the excess risks are all in direct correlation, suggesting both that SGD selects predictors whose complexity scales with the difficulty of the learning task, and secondly that the presented bound is sensitive to this complexity.
Neural networks and rational functions
Jun 11, 2017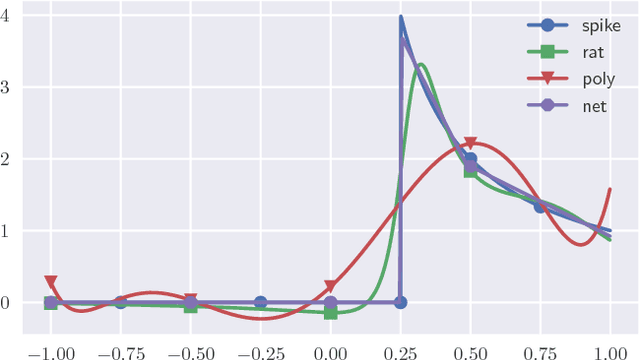
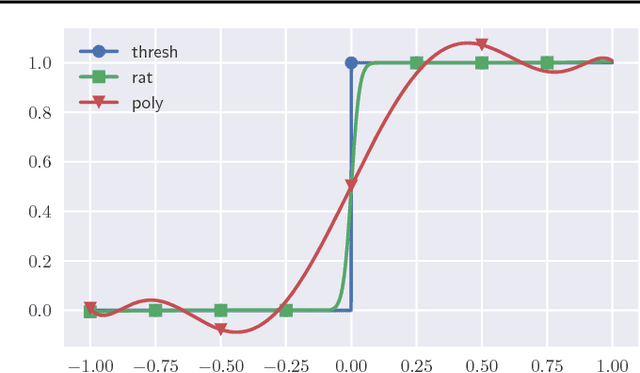
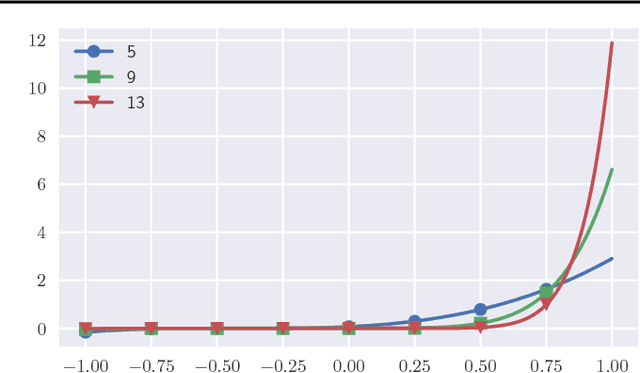
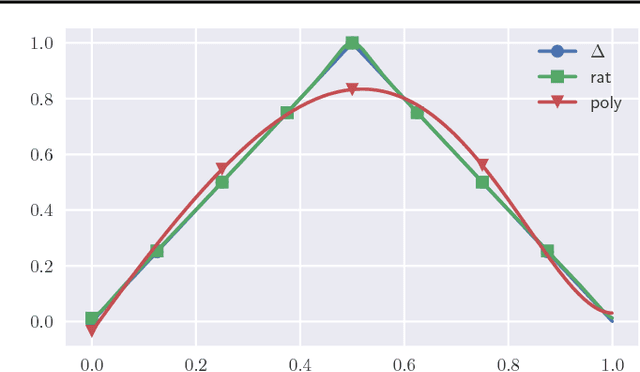
Neural networks and rational functions efficiently approximate each other. In more detail, it is shown here that for any ReLU network, there exists a rational function of degree $O(\text{polylog}(1/\epsilon))$ which is $\epsilon$-close, and similarly for any rational function there exists a ReLU network of size $O(\text{polylog}(1/\epsilon))$ which is $\epsilon$-close. By contrast, polynomials need degree $\Omega(\text{poly}(1/\epsilon))$ to approximate even a single ReLU. When converting a ReLU network to a rational function as above, the hidden constants depend exponentially on the number of layers, which is shown to be tight; in other words, a compositional representation can be beneficial even for rational functions.
Non-convex learning via Stochastic Gradient Langevin Dynamics: a nonasymptotic analysis
Jun 04, 2017Stochastic Gradient Langevin Dynamics (SGLD) is a popular variant of Stochastic Gradient Descent, where properly scaled isotropic Gaussian noise is added to an unbiased estimate of the gradient at each iteration. This modest change allows SGLD to escape local minima and suffices to guarantee asymptotic convergence to global minimizers for sufficiently regular non-convex objectives (Gelfand and Mitter, 1991). The present work provides a nonasymptotic analysis in the context of non-convex learning problems, giving finite-time guarantees for SGLD to find approximate minimizers of both empirical and population risks. As in the asymptotic setting, our analysis relates the discrete-time SGLD Markov chain to a continuous-time diffusion process. A new tool that drives the results is the use of weighted transportation cost inequalities to quantify the rate of convergence of SGLD to a stationary distribution in the Euclidean $2$-Wasserstein distance.
Greedy bi-criteria approximations for $k$-medians and $k$-means
Jul 21, 2016
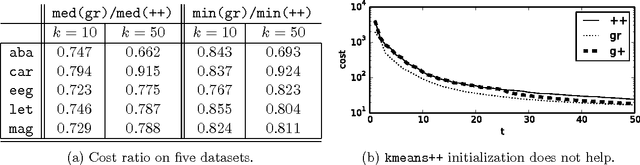
This paper investigates the following natural greedy procedure for clustering in the bi-criterion setting: iteratively grow a set of centers, in each round adding the center from a candidate set that maximally decreases clustering cost. In the case of $k$-medians and $k$-means, the key results are as follows. $\bullet$ When the method considers all data points as candidate centers, then selecting $\mathcal{O}(k\log(1/\varepsilon))$ centers achieves cost at most $2+\varepsilon$ times the optimal cost with $k$ centers. $\bullet$ Alternatively, the same guarantees hold if each round samples $\mathcal{O}(k/\varepsilon^5)$ candidate centers proportionally to their cluster cost (as with $\texttt{kmeans++}$, but holding centers fixed). $\bullet$ In the case of $k$-means, considering an augmented set of $n^{\lceil1/\varepsilon\rceil}$ candidate centers gives $1+\varepsilon$ approximation with $\mathcal{O}(k\log(1/\varepsilon))$ centers, the entire algorithm taking $\mathcal{O}(dk\log(1/\varepsilon)n^{1+\lceil1/\varepsilon\rceil})$ time, where $n$ is the number of data points in $\mathbb{R}^d$. $\bullet$ In the case of Euclidean $k$-medians, generating a candidate set via $n^{\mathcal{O}(1/\varepsilon^2)}$ executions of stochastic gradient descent with adaptively determined constraint sets will once again give approximation $1+\varepsilon$ with $\mathcal{O}(k\log(1/\varepsilon))$ centers in $dk\log(1/\varepsilon)n^{\mathcal{O}(1/\varepsilon^2)}$ time. Ancillary results include: guarantees for cluster costs based on powers of metrics; a brief, favorable empirical evaluation against $\texttt{kmeans++}$; data-dependent bounds allowing $1+\varepsilon$ in the first two bullets above, for example with $k$-medians over finite metric spaces.