 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRUST: Leveraging Text Robustness for Unsupervised Domain Adaptation
Aug 08, 2025Recent unsupervised domain adaptation (UDA) methods have shown great success in addressing classical domain shifts (e.g., synthetic-to-real), but they still suffer under complex shifts (e.g. geographical shift), where both the background and object appearances differ significantly across domains. Prior works showed that the language modality can help in the adaptation process, exhibiting more robustness to such complex shifts. In this paper, we introduce TRUST, a novel UDA approach that exploits the robustness of the language modality to guide the adaptation of a vision model. TRUST generates pseudo-labels for target samples from their captions and introduces a novel uncertainty estimation strategy that uses normalised CLIP similarity scores to estimate the uncertainty of the generated pseudo-labels. Such estimated uncertainty is then used to reweight the classification loss, mitigating the adverse effects of wrong pseudo-labels obtained from low-quality captions. To further increase the robustness of the vision model, we propose a multimodal soft-contrastive learning loss that aligns the vision and language feature spaces, by leveraging captions to guide the contrastive training of the vision model on target images. In our contrastive loss, each pair of images acts as both a positive and a negative pair and their feature representations are attracted and repulsed with a strength proportional to the similarity of their captions. This solution avoids the need for hardly determining positive and negative pairs, which is critical in the UDA setting. Our approach outperforms previous methods, setting the new state-of-the-art on classical (DomainNet) and complex (GeoNet) domain shifts. The code will be available upon acceptance.
TADM: Temporally-Aware Diffusion Model for Neurodegenerative Progression on Brain MRI
Jun 18, 2024



Generating realistic images to accurately predict changes in the structure of brain MRI is a crucial tool for clinicians. Such applications help assess patients' outcomes and analyze how diseases progress at the individual level. However, existing methods for this task present some limitations. Some approaches attempt to model the distribution of MRI scans directly by conditioning the model on patients' ages, but they fail to explicitly capture the relationship between structural changes in the brain and time intervals, especially on age-unbalanced datasets. Other approaches simply rely on interpolation between scans, which limits their clinical application as they do not predict future MRIs. To address these challenges, we propose a Temporally-Aware Diffusion Model (TADM), which introduces a novel approach to accurately infer progression in brain MRIs. TADM learns the distribution of structural changes in terms of intensity differences between scans and combines the prediction of these changes with the initial baseline scans to generate future MRIs. Furthermore, during training, we propose to leverage a pre-trained Brain-Age Estimator (BAE) to refine the model's training process, enhancing its ability to produce accurate MRIs that match the expected age gap between baseline and generated scans. Our assessment, conducted on the OASIS-3 dataset, uses similarity metrics and region sizes computed by comparing predicted and real follow-up scans on 3 relevant brain regions. TADM achieves large improvements over existing approaches, with an average decrease of 24% in region size error and an improvement of 4% in similarity metrics. These evaluations demonstrate the improvement of our model in mimicking temporal brain neurodegenerative progression compared to existing methods. Our approach will benefit applications, such as predicting patient outcomes or improving treatments for patients.
Uncertainty-guided Open-Set Source-Free Unsupervised Domain Adaptation with Target-private Class Segregation
Apr 16, 2024Standard Unsupervised Domain Adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target but usually requires simultaneous access to both source and target data. Moreover, UDA approaches commonly assume that source and target domains share the same labels space. Yet, these two assumptions are hardly satisfied in real-world scenarios. This paper considers the more challenging Source-Free Open-set Domain Adaptation (SF-OSDA) setting, where both assumptions are dropped. We propose a novel approach for SF-OSDA that exploits the granularity of target-private categories by segregating their samples into multiple unknown classes. Starting from an initial clustering-based assignment, our method progressively improves the segregation of target-private samples by refining their pseudo-labels with the guide of an uncertainty-based sample selection module. Additionally, we propose a novel contrastive loss, named NL-InfoNCELoss, that, integrating negative learning into self-supervised contrastive learning, enhances the model robustness to noisy pseudo-labels. Extensive experiments on benchmark datasets demonstrate the superiority of the proposed method over existing approaches, establishing new state-of-the-art performance. Notably, additional analyses show that our method is able to learn the underlying semantics of novel classes, opening the possibility to perform novel class discovery.
Guiding Pseudo-labels with Uncertainty Estimation for Source-free Unsupervised Domain Adaptation
Mar 17, 2023



Standard Unsupervised Domain Adaptation (UDA) methods assume the availability of both source and target data during the adaptation. In this work, we investigate Source-free Unsupervised Domain Adaptation (SF-UDA), a specific case of UDA where a model is adapted to a target domain without access to source data. We propose a novel approach for the SF-UDA setting based on a loss reweighting strategy that brings robustness against the noise that inevitably affects the pseudo-labels. The classification loss is reweighted based on the reliability of the pseudo-labels that is measured by estimating their uncertainty. Guided by such reweighting strategy, the pseudo-labels are progressively refined by aggregating knowledge from neighbouring samples. Furthermore, a self-supervised contrastive framework is leveraged as a target space regulariser to enhance such knowledge aggregation. A novel negative pairs exclusion strategy is proposed to identify and exclude negative pairs made of samples sharing the same class, even in presence of some noise in the pseudo-labels. Our method outperforms previous methods on three major benchmarks by a large margin. We set the new SF-UDA state-of-the-art on VisDA-C and DomainNet with a performance gain of +1.8% on both benchmarks and on PACS with +12.3% in the single-source setting and +6.6% in multi-target adaptation. Additional analyses demonstrate that the proposed approach is robust to the noise, which results in significantly more accurate pseudo-labels compared to state-of-the-art approaches.
Single architecture and multiple task deep neural network for altered fingerprint analysis
Jul 09, 2020

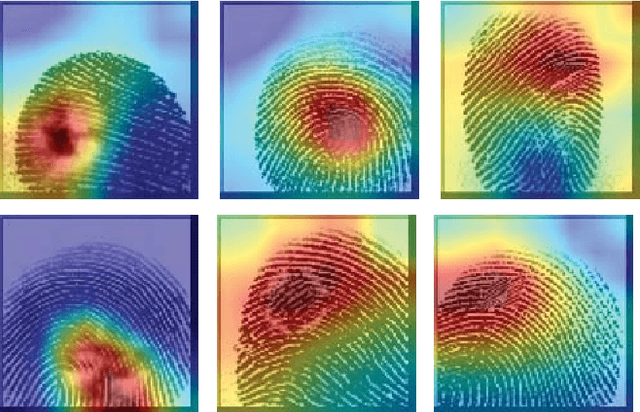
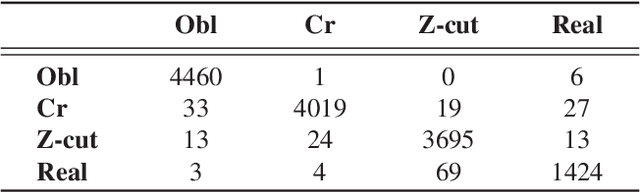
Fingerprints are one of the most copious evidence in a crime scene and, for this reason, they are frequently used by law enforcement for identification of individuals. But fingerprints can be altered. "Altered fingerprints", refers to intentionally damage of the friction ridge pattern and they are often used by smart criminals in hope to evade law enforcement. We use a deep neural network approach training an Inception-v3 architecture. This paper proposes a method for detection of altered fingerprints, identification of types of alterations and recognition of gender, hand and fingers. We also produce activation maps that show which part of a fingerprint the neural network has focused on, in order to detect where alterations are positioned. The proposed approach achieves an accuracy of 98.21%, 98.46%, 92.52%, 97.53% and 92,18% for the classification of fakeness, alterations, gender, hand and fingers, respectively on the SO.CO.FING. dataset.