 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToFu: Visual Tokens Reduction via Fusion for Multi-modal, Multi-patch, Multi-image Task
Mar 06, 2025



Large Multimodal Models (LMMs) are powerful tools that are capable of reasoning and understanding multimodal information beyond text and language. Despite their entrenched impact, the development of LMMs is hindered by the higher computational requirements compared to their unimodal counterparts. One of the main causes of this is the large amount of tokens needed to encode the visual input, which is especially evident for multi-image multimodal tasks. Recent approaches to reduce visual tokens depend on the visual encoder architecture, require fine-tuning the LLM to maintain the performance, and only consider single-image scenarios. To address these limitations, we propose ToFu, a visual encoder-agnostic, training-free Token Fusion strategy that combines redundant visual tokens of LMMs for high-resolution, multi-image, tasks. The core intuition behind our method is straightforward yet effective: preserve distinctive tokens while combining similar ones. We achieve this by sequentially examining visual tokens and deciding whether to merge them with others or keep them as separate entities. We validate our approach on the well-established LLaVA-Interleave Bench, which covers challenging multi-image tasks. In addition, we push to the extreme our method by testing it on a newly-created benchmark, ComPairs, focused on multi-image comparisons where a larger amount of images and visual tokens are inputted to the LMMs. Our extensive analysis, considering several LMM architectures, demonstrates the benefits of our approach both in terms of efficiency and performance gain.
UniCoRN: Unified Commented Retrieval Network with LMMs
Feb 12, 2025Multimodal retrieval methods have limitations in handling complex, compositional queries that require reasoning about the visual content of both the query and the retrieved entities. On the other hand, Large Multimodal Models (LMMs) can answer with language to more complex visual questions, but without the inherent ability to retrieve relevant entities to support their answers. We aim to address these limitations with UniCoRN, a Unified Commented Retrieval Network that combines the strengths of composed multimodal retrieval methods and generative language approaches, going beyond Retrieval-Augmented Generation (RAG). We introduce an entity adapter module to inject the retrieved multimodal entities back into the LMM, so it can attend to them while generating answers and comments. By keeping the base LMM frozen, UniCoRN preserves its original capabilities while being able to perform both retrieval and text generation tasks under a single integrated framework. To assess these new abilities, we introduce the Commented Retrieval task (CoR) and a corresponding dataset, with the goal of retrieving an image that accurately answers a given question and generate an additional textual response that provides further clarification and details about the visual information. We demonstrate the effectiveness of UniCoRN on several datasets showing improvements of +4.5% recall over the state of the art for composed multimodal retrieval and of +14.9% METEOR / +18.4% BEM over RAG for commenting in CoR.
LatteCLIP: Unsupervised CLIP Fine-Tuning via LMM-Synthetic Texts
Oct 10, 2024



Large-scale vision-language pre-trained (VLP) models (e.g., CLIP) are renowned for their versatility, as they can be applied to diverse applications in a zero-shot setup. However, when these models are used in specific domains, their performance often falls short due to domain gaps or the under-representation of these domains in the training data. While fine-tuning VLP models on custom datasets with human-annotated labels can address this issue, annotating even a small-scale dataset (e.g., 100k samples) can be an expensive endeavor, often requiring expert annotators if the task is complex. To address these challenges, we propose LatteCLIP, an unsupervised method for fine-tuning CLIP models on classification with known class names in custom domains, without relying on human annotations. Our method leverages Large Multimodal Models (LMMs) to generate expressive textual descriptions for both individual images and groups of images. These provide additional contextual information to guide the fine-tuning process in the custom domains. Since LMM-generated descriptions are prone to hallucination or missing details, we introduce a novel strategy to distill only the useful information and stabilize the training. Specifically, we learn rich per-class prototype representations from noisy generated texts and dual pseudo-labels. Our experiments on 10 domain-specific datasets show that LatteCLIP outperforms pre-trained zero-shot methods by an average improvement of +4.74 points in top-1 accuracy and other state-of-the-art unsupervised methods by +3.45 points.
ABO: Dataset and Benchmarks for Real-World 3D Object Understanding
Oct 12, 2021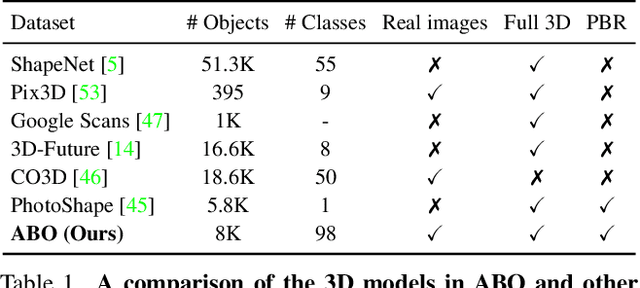
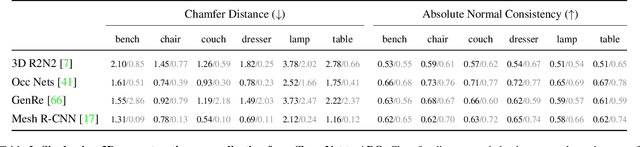
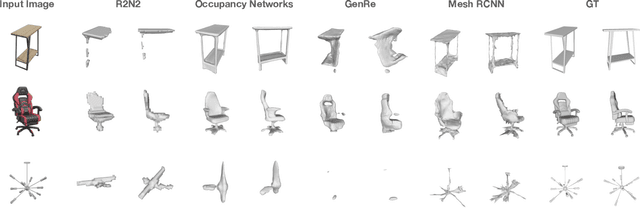
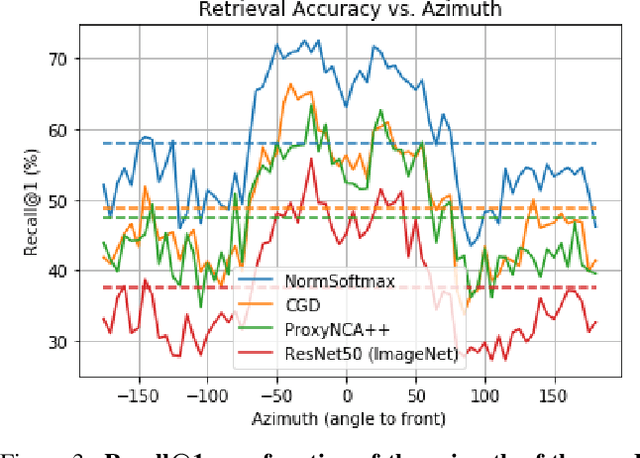
We introduce Amazon-Berkeley Objects (ABO), a new large-scale dataset of product images and 3D models corresponding to real household objects. We use this realistic, object-centric 3D dataset to measure the domain gap for single-view 3D reconstruction networks trained on synthetic objects. We also use multi-view images from ABO to measure the robustness of state-of-the-art metric learning approaches to different camera viewpoints. Finally, leveraging the physically-based rendering materials in ABO, we perform single- and multi-view material estimation for a variety of complex, real-world geometries. The full dataset is available for download at https://amazon-berkeley-objects.s3.amazonaws.com/index.html.
Closed-Form Training of Conditional Random Fields for Large Scale Image Segmentation
Mar 27, 2014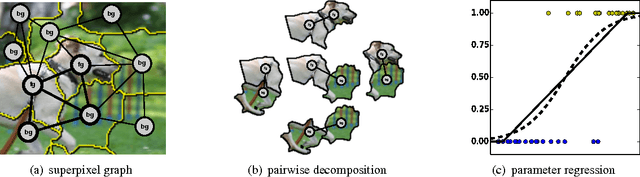
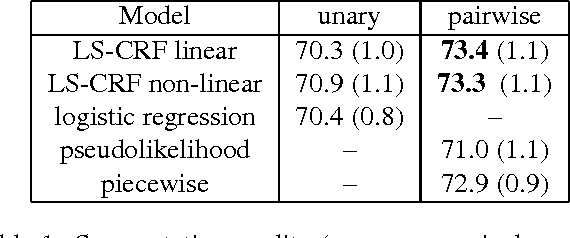
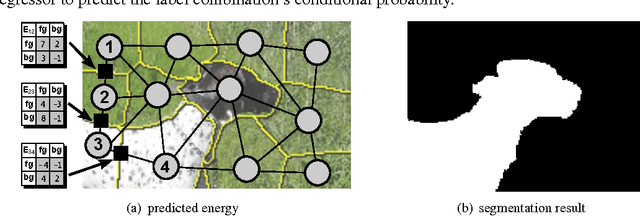
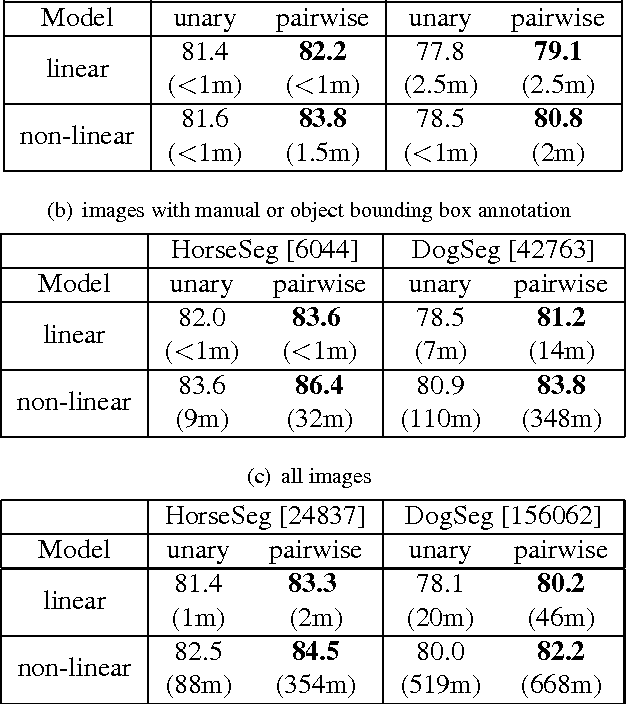
We present LS-CRF, a new method for very efficient large-scale training of Conditional Random Fields (CRFs). It is inspired by existing closed-form expressions for the maximum likelihood parameters of a generative graphical model with tree topology. LS-CRF training requires only solving a set of independent regression problems, for which closed-form expression as well as efficient iterative solvers are available. This makes it orders of magnitude faster than conventional maximum likelihood learning for CRFs that require repeated runs of probabilistic inference. At the same time, the models learned by our method still allow for joint inference at test time. We apply LS-CRF to the task of semantic image segmentation, showing that it is highly efficient, even for loopy models where probabilistic inference is problematic. It allows the training of image segmentation models from significantly larger training sets than had been used previously. We demonstrate this on two new datasets that form a second contribution of this paper. They consist of over 180,000 images with figure-ground segmentation annotations. Our large-scale experiments show that the possibilities of CRF-based image segmentation are far from exhausted, indicating, for example, that semi-supervised learning and the use of non-linear predictors are promising directions for achieving higher segmentation accuracy in the future.