 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the limits of RNN Compression
Oct 09, 2019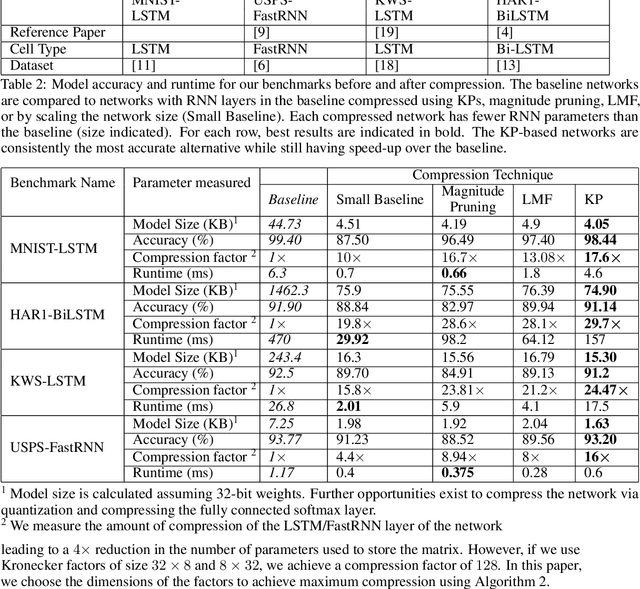
Recurrent Neural Networks (RNN) can be difficult to deploy on resource constrained devices due to their size. As a result, there is a need for compression techniques that can significantly compress RNNs without negatively impacting task accuracy. This paper introduces a method to compress RNNs for resource constrained environments using Kronecker product (KP). KPs can compress RNN layers by 16-38x with minimal accuracy loss. We show that KP can beat the task accuracy achieved by other state-of-the-art compression techniques (pruning and low-rank matrix factorization) across 4 benchmarks spanning 3 different applications, while simultaneously improving inference run-time.
* 6 pages. arXiv admin note: substantial text overlap with arXiv:1906.02876
Compressing RNNs for IoT devices by 15-38x using Kronecker Products
Jun 18, 2019
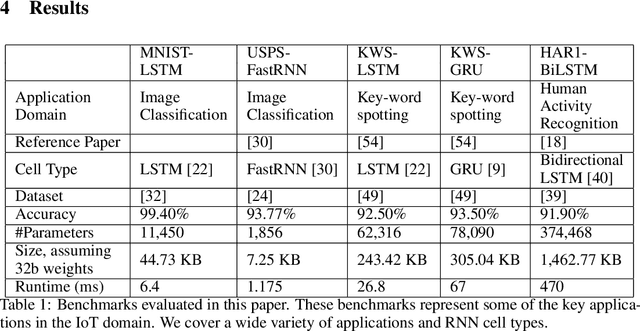
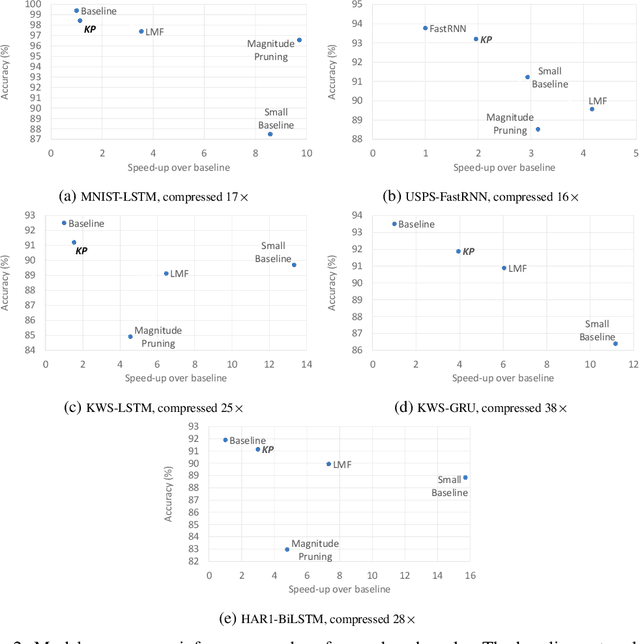
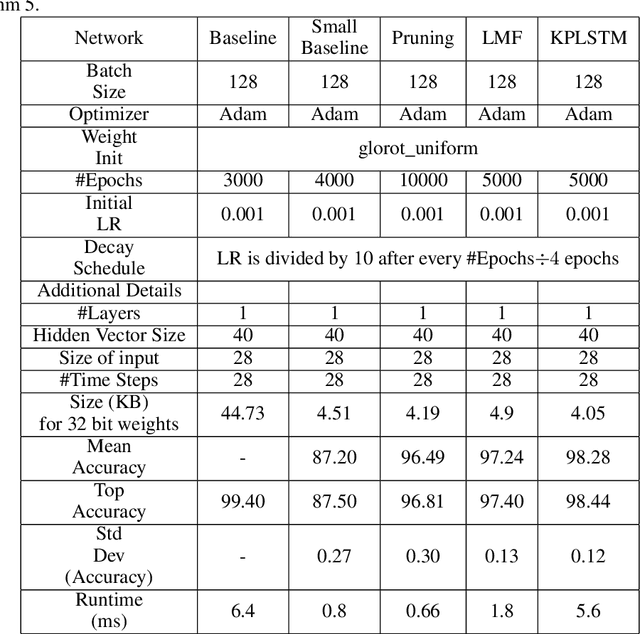
Recurrent Neural Networks (RNN) can be large and compute-intensive, making them hard to deploy on resource constrained devices. As a result, there is a need for compression technique that can significantly compress recurrent neural networks, without negatively impacting task accuracy. This paper introduces a method to compress RNNs for resource constrained environments using Kronecker products. We call the RNNs compressed using Kronecker products as Kronecker product Recurrent Neural Networks (KPRNNs). KPRNNs can compress the LSTM[22], GRU [9] and parameter optimized FastRNN [30] layers by 15 - 38x with minor loss in accuracy and can act as in-place replacement of most RNN cells in existing applications. By quantizing the Kronecker compressed networks to 8 bits, we further push the compression factor to 50x. We compare the accuracy and runtime of KPRNNs with other state-of-the-art compression techniques across 5 benchmarks spanning 3 different applications, showing its generality. Additionally, we show how to control the compression factors achieved by Kronecker products using a novel hybrid decomposition technique. We call the RNN cells compressed using Kronecker products with this control mechanism as hybrid Kronecker product RNNs (HKPRNN). Using HKPRNN, we compress RNN Cells in 2 benchmarks by 10x and 20x achieving better accuracy than other state-of-the-art compression techniques.
Run-Time Efficient RNN Compression for Inference on Edge Devices
Jun 18, 2019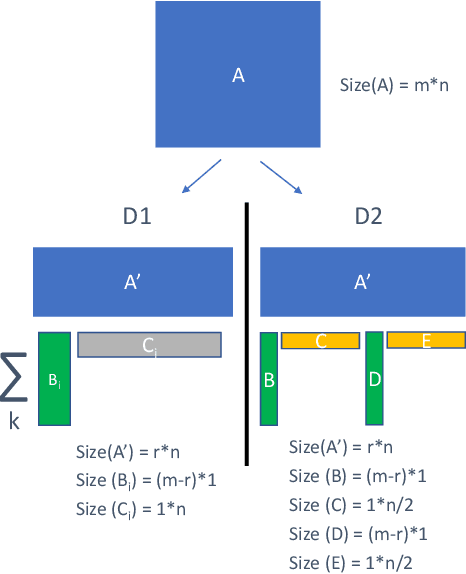
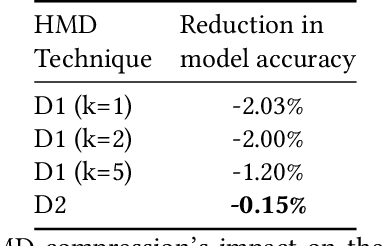
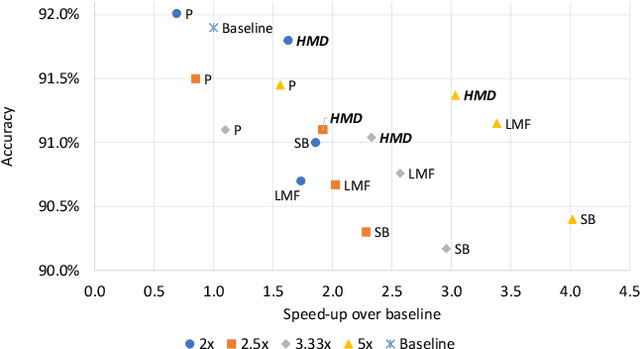
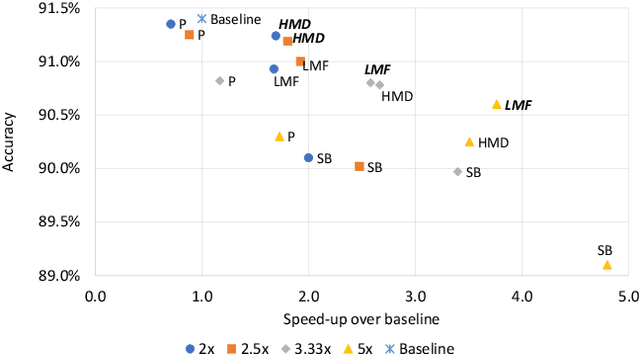
Recurrent neural networks can be large and compute-intensive, yet many applications that benefit from RNNs run on small devices with very limited compute and storage capabilities while still having run-time constraints. As a result, there is a need for compression techniques that can achieve significant compression without negatively impacting inference run-time and task accuracy. This paper explores a new compressed RNN cell implementation called Hybrid Matrix Decomposition (HMD) that achieves this dual objective. This scheme divides the weight matrix into two parts - an unconstrained upper half and a lower half composed of rank-1 blocks. This results in output features where the upper sub-vector has "richer" features while the lower-sub vector has "constrained" features". HMD can compress RNNs by a factor of 2-4x while having a faster run-time than pruning and retaining more model accuracy than matrix factorization. We evaluate this technique on 3 benchmarks.
SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers
May 28, 2019
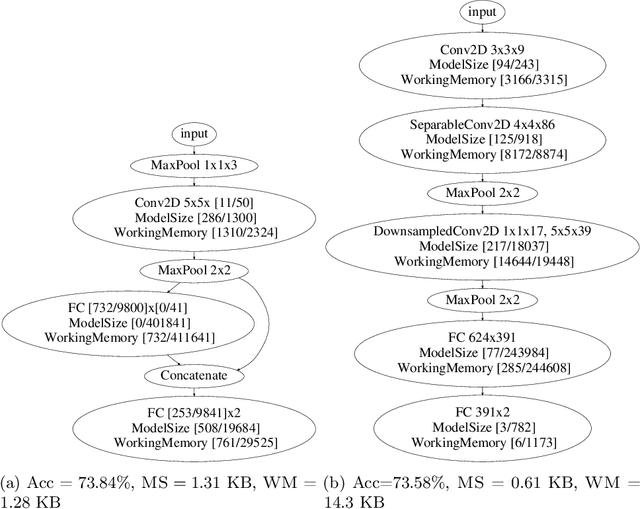
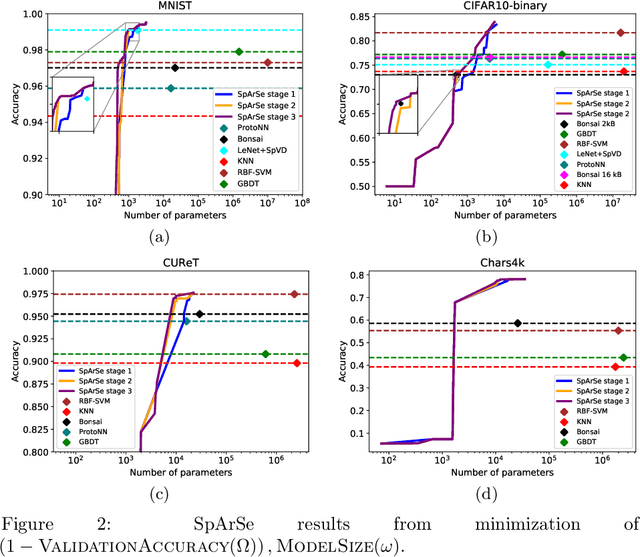
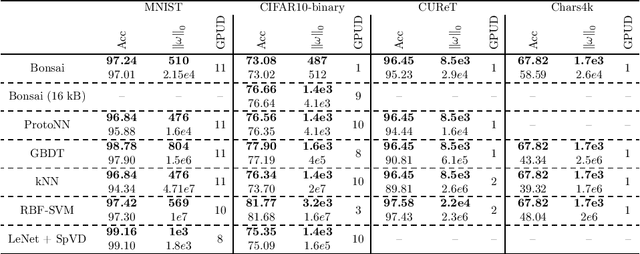
The vast majority of processors in the world are actually microcontroller units (MCUs), which find widespread use performing simple control tasks in applications ranging from automobiles to medical devices and office equipment. The Internet of Things (IoT) promises to inject machine learning into many of these every-day objects via tiny, cheap MCUs. However, these resource-impoverished hardware platforms severely limit the complexity of machine learning models that can be deployed. For example, although convolutional neural networks (CNNs) achieve state-of-the-art results on many visual recognition tasks, CNN inference on MCUs is challenging due to severe finite memory limitations. To circumvent the memory challenge associated with CNNs, various alternatives have been proposed that do fit within the memory budget of an MCU, albeit at the cost of prediction accuracy. This paper challenges the idea that CNNs are not suitable for deployment on MCUs. We demonstrate that it is possible to automatically design CNNs which generalize well, while also being small enough to fit onto memory-limited MCUs. Our Sparse Architecture Search method combines neural architecture search with pruning in a single, unified approach, which learns superior models on four popular IoT datasets. The CNNs we find are more accurate and up to $4.35\times$ smaller than previous approaches, while meeting the strict MCU working memory constraint.
Ternary Hybrid Neural-Tree Networks for Highly Constrained IoT Applications
Mar 04, 2019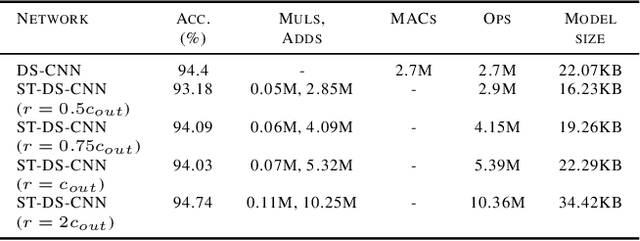
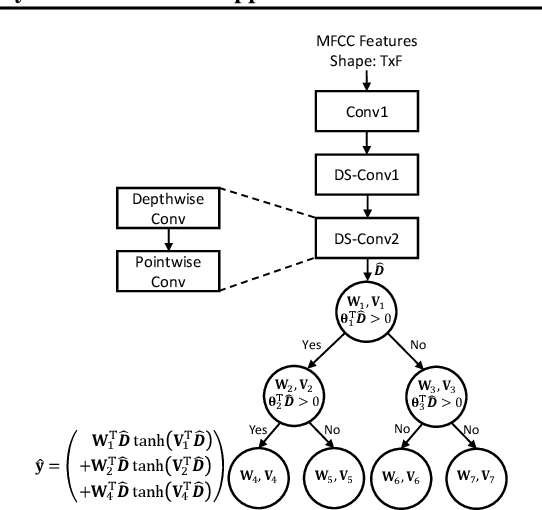
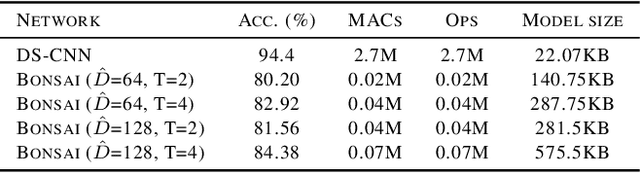
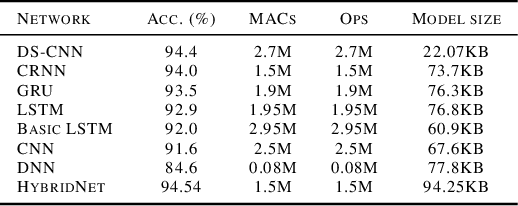
Machine learning-based applications are increasingly prevalent in IoT devices. The power and storage constraints of these devices make it particularly challenging to run modern neural networks, limiting the number of new applications that can be deployed on an IoT system. A number of compression techniques have been proposed, each with its own trade-offs. We propose a hybrid network which combines the strengths of current neural- and tree-based learning techniques in conjunction with ternary quantization, and show a detailed analysis of the associated model design space. Using this hybrid model we obtained a 11.1% reduction in the number of computations, a 52.2% reduction in the model size, and a 30.6% reduction in the overall memory footprint over a state-of-the-art keyword-spotting neural network, with negligible loss in accuracy.
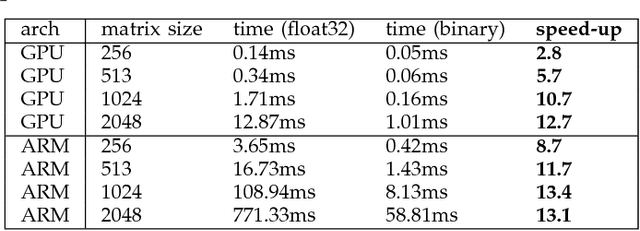
Efficient Winograd or Cook-Toom Convolution Kernel Implementation on Widely Used Mobile CPUs
Mar 04, 2019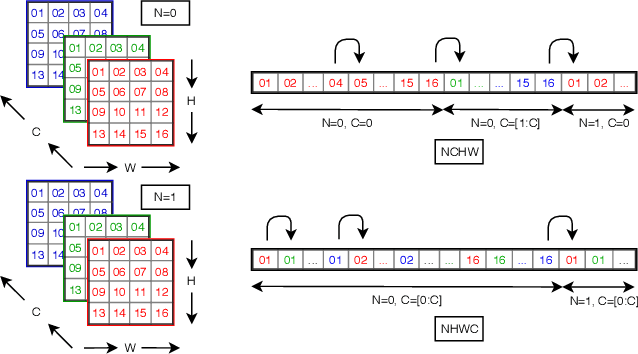

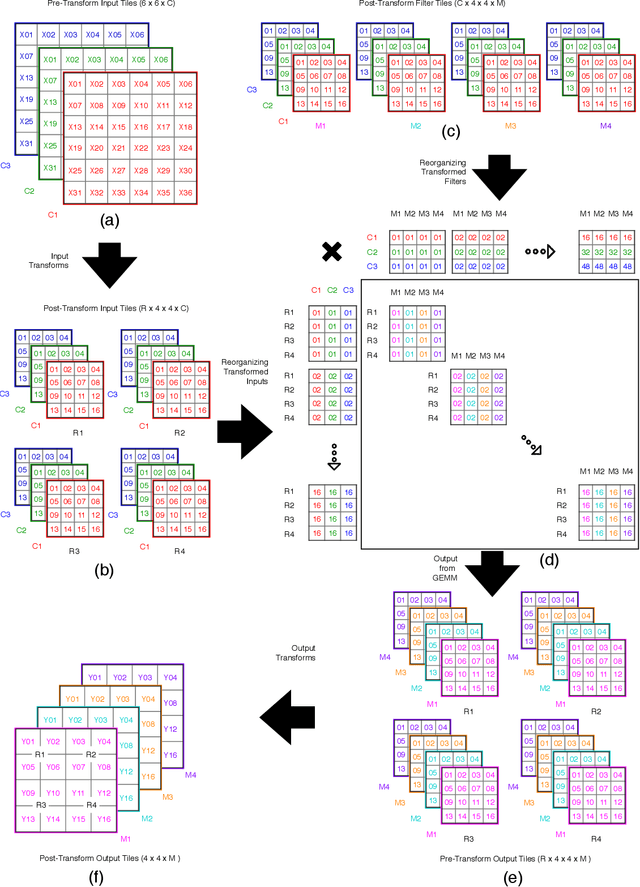
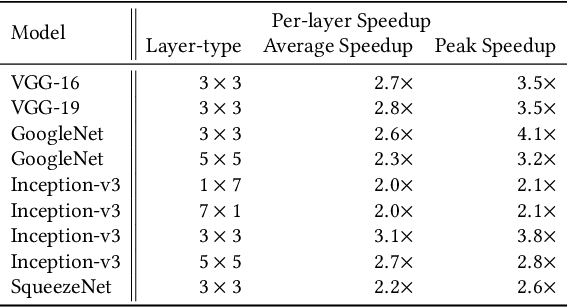
The Winograd or Cook-Toom class of algorithms help to reduce the overall compute complexity of many modern deep convolutional neural networks (CNNs). Although there has been a lot of research done on model and algorithmic optimization of CNN, little attention has been paid to the efficient implementation of these algorithms on embedded CPUs, which usually have very limited memory and low power budget. This paper aims to fill this gap and focuses on the efficient implementation of Winograd or Cook-Toom based convolution on modern Arm Cortex-A CPUs, widely used in mobile devices today. Specifically, we demonstrate a reduction in inference latency by using a set of optimization strategies that improve the utilization of computational resources, and by effectively leveraging the ARMv8-A NEON SIMD instruction set. We evaluated our proposed region-wise multi-channel implementations on Arm Cortex-A73 platform using several representative CNNs. The results show significant performance improvements in full network, up to 60%, over existing im2row/im2col based optimization techniques
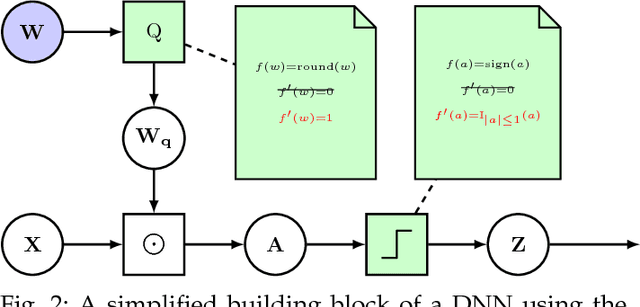
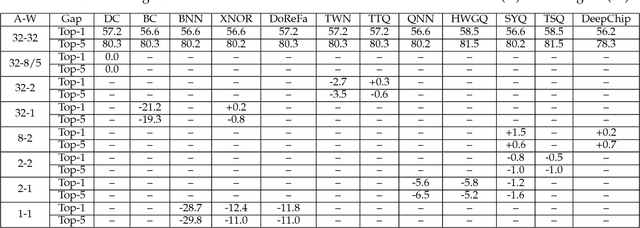
Learning low-precision neural networks without Straight-Through Estimator(STE)
Mar 04, 2019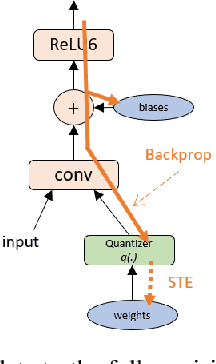
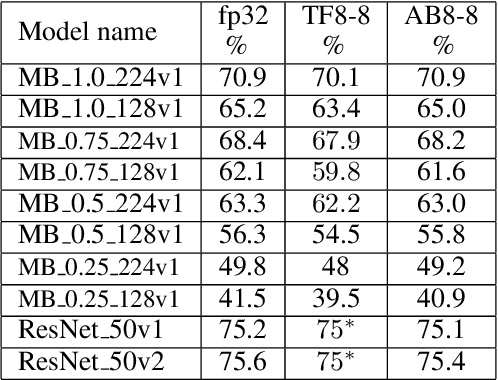
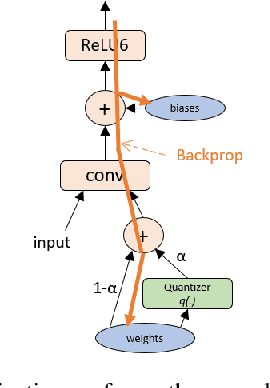
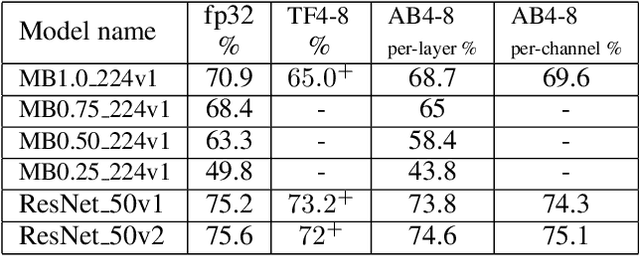
The Straight-Through Estimator (STE) is widely used for back-propagating gradients through the quantization function, but the STE technique lacks a complete theoretical understanding. We propose an alternative methodology called alpha-blending (AB), which quantizes neural networks to low-precision using stochastic gradient descent (SGD). Our method (AB) avoids STE approximation by replacing the quantized weight in the loss function by an affine combination of the quantized weight w_q and the corresponding full-precision weight w with non-trainable scalar coefficient $\alpha$ and $1-\alpha$. During training, $\alpha$ is gradually increased from 0 to 1; the gradient updates to the weights are through the full-precision term, $(1-\alpha)w$, of the affine combination; the model is converted from full-precision to low-precision progressively. To evaluate the method, a 1-bit BinaryNet on CIFAR10 dataset and 8-bits, 4-bits MobileNet v1, ResNet_50 v1/2 on ImageNet dataset are trained using the alpha-blending approach, and the evaluation indicates that AB improves top-1 accuracy by 0.9%, 0.82% and 2.93% respectively compared to the results of STE based quantization.
FixyNN: Efficient Hardware for Mobile Computer Vision via Transfer Learning
Feb 27, 2019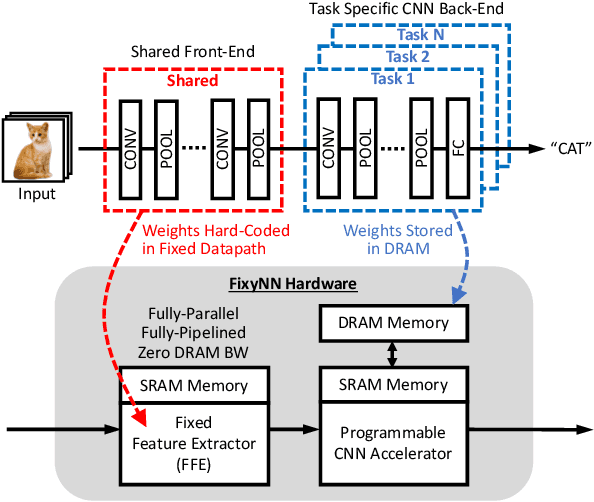
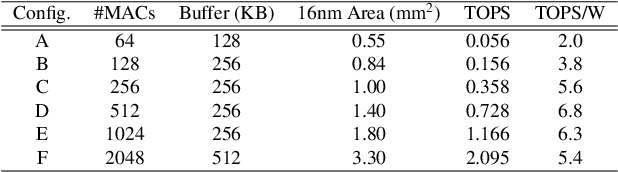
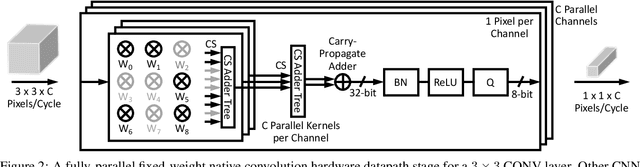
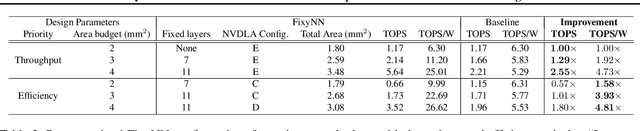
The computational demands of computer vision tasks based on state-of-the-art Convolutional Neural Network (CNN) image classification far exceed the energy budgets of mobile devices. This paper proposes FixyNN, which consists of a fixed-weight feature extractor that generates ubiquitous CNN features, and a conventional programmable CNN accelerator which processes a dataset-specific CNN. Image classification models for FixyNN are trained end-to-end via transfer learning, with the common feature extractor representing the transfered part, and the programmable part being learnt on the target dataset. Experimental results demonstrate FixyNN hardware can achieve very high energy efficiencies up to 26.6 TOPS/W ($4.81 \times$ better than iso-area programmable accelerator). Over a suite of six datasets we trained models via transfer learning with an accuracy loss of $<1\%$ resulting in up to 11.2 TOPS/W - nearly $2 \times$ more efficient than a conventional programmable CNN accelerator of the same area.
Efficient and Robust Machine Learning for Real-World Systems
Dec 05, 2018
While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation and the vision of the Internet-of-Things fuel the interest in resource efficient approaches. These approaches require a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. On top of this, it is crucial to treat uncertainty in a consistent manner in all but the simplest applications of machine learning systems. In particular, a desideratum for any real-world system is to be robust in the presence of outliers and corrupted data, as well as being `aware' of its limits, i.e.\ the system should maintain and provide an uncertainty estimate over its own predictions. These complex demands are among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology into every day's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. First we provide a comprehensive review of resource-efficiency in deep neural networks with focus on techniques for model size reduction, compression and reduced precision. These techniques can be applied during training or as post-processing and are widely used to reduce both computational complexity and memory footprint. As most (practical) neural networks are limited in their ways to treat uncertainty, we contrast them with probabilistic graphical models, which readily serve these desiderata by means of probabilistic inference. In that way, we provide an extensive overview of the current state-of-the-art of robust and efficient machine learning for real-world systems.
Energy Efficient Hardware for On-Device CNN Inference via Transfer Learning
Dec 04, 2018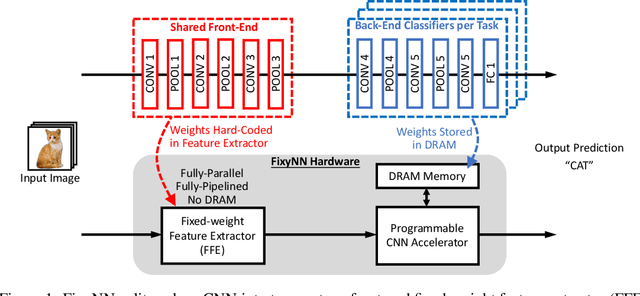

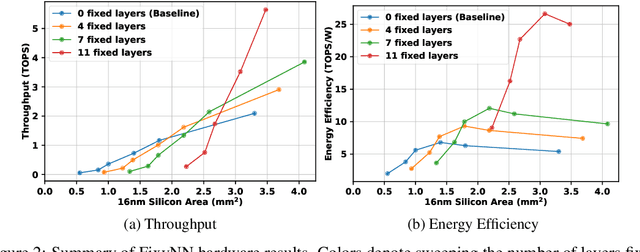
On-device CNN inference for real-time computer vision applications can result in computational demands that far exceed the energy budgets of mobile devices. This paper proposes FixyNN, a co-designed hardware accelerator platform which splits a CNN model into two parts: a set of layers that are fixed in the hardware platform as a front-end fixed-weight feature extractor, and the remaining layers which become a back-end classifier running on a conventional programmable CNN accelerator. The common front-end provides ubiquitous CNN features for all FixyNN models, while the back-end is programmable and specific to a given dataset. Image classification models for FixyNN are trained end-to-end via transfer learning, with front-end layers fixed for the shared feature extractor, and back-end layers fine-tuned for a specific task. Over a suite of six datasets, we trained models via transfer learning with an accuracy loss of <1%, resulting in a FixyNN hardware platform with nearly 2 times better energy efficiency than a conventional programmable CNN accelerator of the same silicon area (i.e. hardware cost).