 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsychlab: A Psychology Laboratory for Deep Reinforcement Learning Agents
Feb 04, 2018


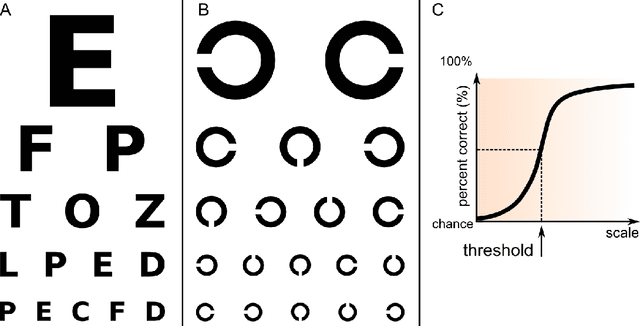
Psychlab is a simulated psychology laboratory inside the first-person 3D game world of DeepMind Lab (Beattie et al. 2016). Psychlab enables implementations of classical laboratory psychological experiments so that they work with both human and artificial agents. Psychlab has a simple and flexible API that enables users to easily create their own tasks. As examples, we are releasing Psychlab implementations of several classical experimental paradigms including visual search, change detection, random dot motion discrimination, and multiple object tracking. We also contribute a study of the visual psychophysics of a specific state-of-the-art deep reinforcement learning agent: UNREAL (Jaderberg et al. 2016). This study leads to the surprising conclusion that UNREAL learns more quickly about larger target stimuli than it does about smaller stimuli. In turn, this insight motivates a specific improvement in the form of a simple model of foveal vision that turns out to significantly boost UNREAL's performance, both on Psychlab tasks, and on standard DeepMind Lab tasks. By open-sourcing Psychlab we hope to facilitate a range of future such studies that simultaneously advance deep reinforcement learning and improve its links with cognitive science.
Structure Learning in Motor Control:A Deep Reinforcement Learning Model
Jul 13, 2017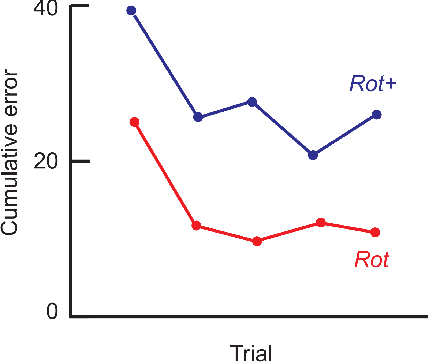

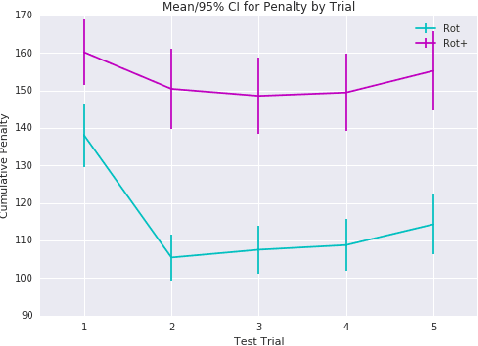
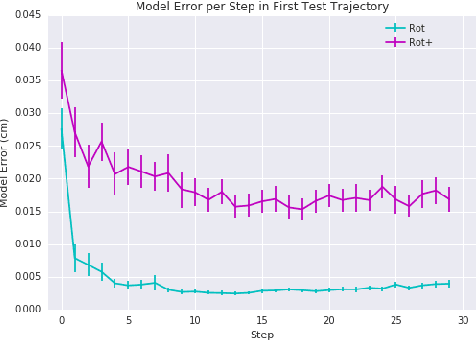
Motor adaptation displays a structure-learning effect: adaptation to a new perturbation occurs more quickly when the subject has prior exposure to perturbations with related structure. Although this `learning-to-learn' effect is well documented, its underlying computational mechanisms are poorly understood. We present a new model of motor structure learning, approaching it from the point of view of deep reinforcement learning. Previous work outside of motor control has shown how recurrent neural networks can account for learning-to-learn effects. We leverage this insight to address motor learning, by importing it into the setting of model-based reinforcement learning. We apply the resulting processing architecture to empirical findings from a landmark study of structure learning in target-directed reaching (Braun et al., 2009), and discuss its implications for a wider range of learning-to-learn phenomena.