 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Advisor Q-Learning
Nov 08, 2021
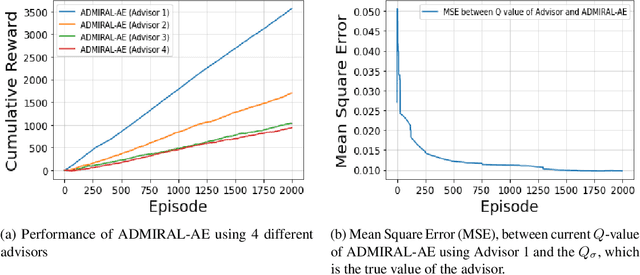
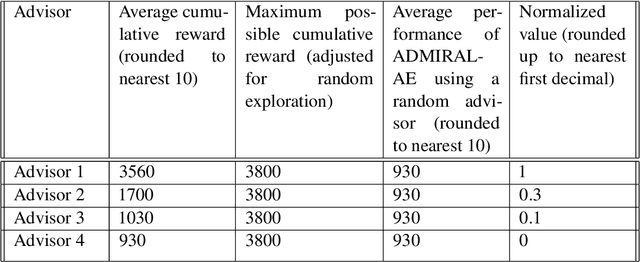
In the last decade, there have been significant advances in multi-agent reinforcement learning (MARL) but there are still numerous challenges, such as high sample complexity and slow convergence to stable policies, that need to be overcome before wide-spread deployment is possible. However, many real-world environments already, in practice, deploy sub-optimal or heuristic approaches for generating policies. An interesting question which arises is how to best use such approaches as advisors to help improve reinforcement learning in multi-agent domains. In this paper, we provide a principled framework for incorporating action recommendations from online sub-optimal advisors in multi-agent settings. We describe the problem of ADvising Multiple Intelligent Reinforcement Agents (ADMIRAL) in nonrestrictive general-sum stochastic game environments and present two novel Q-learning based algorithms: ADMIRAL - Decision Making (ADMIRAL-DM) and ADMIRAL - Advisor Evaluation (ADMIRAL-AE), which allow us to improve learning by appropriately incorporating advice from an advisor (ADMIRAL-DM), and evaluate the effectiveness of an advisor (ADMIRAL-AE). We analyze the algorithms theoretically and provide fixed-point guarantees regarding their learning in general-sum stochastic games. Furthermore, extensive experiments illustrate that these algorithms: can be used in a variety of environments, have performances that compare favourably to other related baselines, can scale to large state-action spaces, and are robust to poor advice from advisors.
The Atari Data Scraper
Apr 11, 2021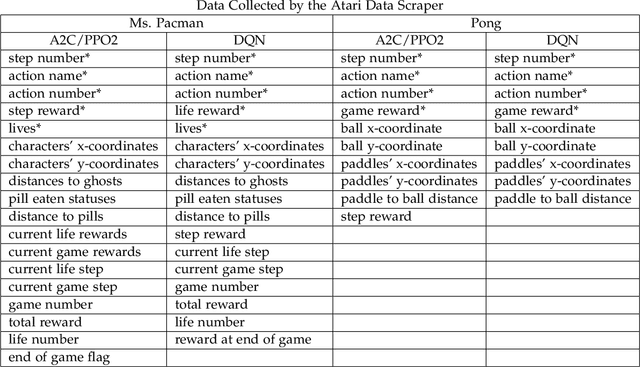
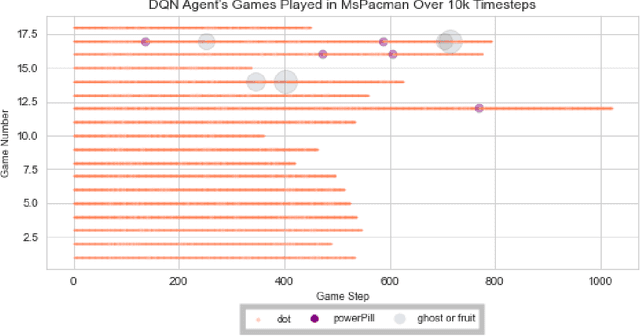
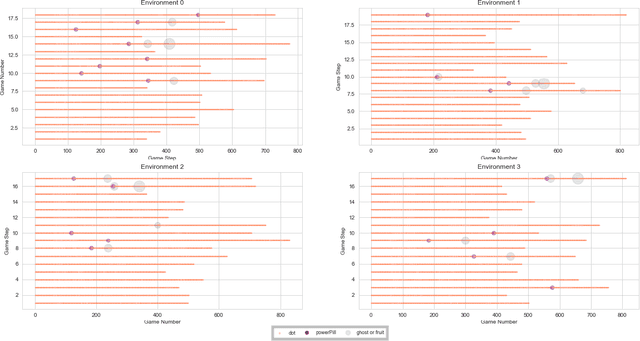
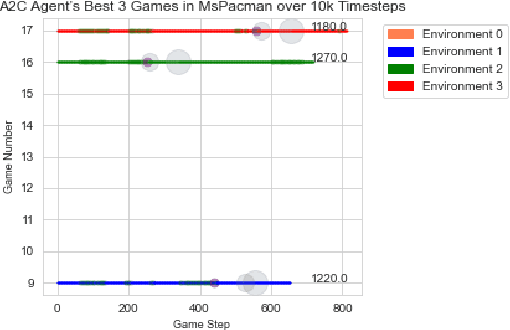
Reinforcement learning has made great strides in recent years due to the success of methods using deep neural networks. However, such neural networks act as a black box, obscuring the inner workings. While reinforcement learning has the potential to solve unique problems, a lack of trust and understanding of reinforcement learning algorithms could prevent their widespread adoption. Here, we present a library that attaches a "data scraper" to deep reinforcement learning agents, acting as an observer, and then show how the data collected by the Atari Data Scraper can be used to understand and interpret deep reinforcement learning agents. The code for the Atari Data Scraper can be found here: https://github.com/IRLL/Atari-Data-Scraper
The Effect of Q-function Reuse on the Total Regret of Tabular, Model-Free, Reinforcement Learning
Mar 07, 2021
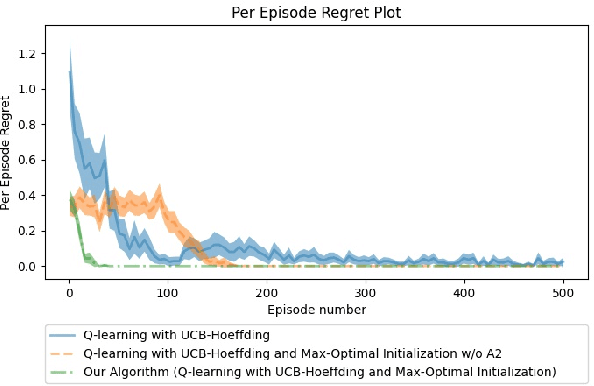
Some reinforcement learning methods suffer from high sample complexity causing them to not be practical in real-world situations. $Q$-function reuse, a transfer learning method, is one way to reduce the sample complexity of learning, potentially improving usefulness of existing algorithms. Prior work has shown the empirical effectiveness of $Q$-function reuse for various environments when applied to model-free algorithms. To the best of our knowledge, there has been no theoretical work showing the regret of $Q$-function reuse when applied to the tabular, model-free setting. We aim to bridge the gap between theoretical and empirical work in $Q$-function reuse by providing some theoretical insights on the effectiveness of $Q$-function reuse when applied to the $Q$-learning with UCB-Hoeffding algorithm. Our main contribution is showing that in a specific case if $Q$-function reuse is applied to the $Q$-learning with UCB-Hoeffding algorithm it has a regret that is independent of the state or action space. We also provide empirical results supporting our theoretical findings.
Model-Invariant State Abstractions for Model-Based Reinforcement Learning
Feb 19, 2021
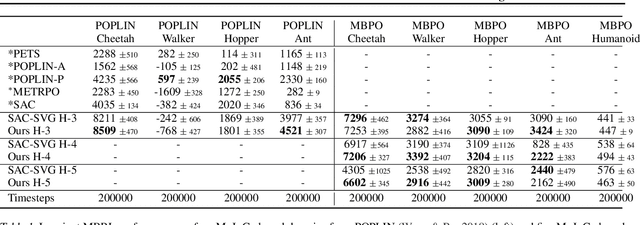

Accuracy and generalization of dynamics models is key to the success of model-based reinforcement learning (MBRL). As the complexity of tasks increases, learning dynamics models becomes increasingly sample inefficient for MBRL methods. However, many tasks also exhibit sparsity in the dynamics, i.e., actions have only a local effect on the system dynamics. In this paper, we exploit this property with a causal invariance perspective in the single-task setting, introducing a new type of state abstraction called \textit{model-invariance}. Unlike previous forms of state abstractions, a model-invariance state abstraction leverages causal sparsity over state variables. This allows for generalization to novel combinations of unseen values of state variables, something that non-factored forms of state abstractions cannot do. We prove that an optimal policy can be learned over this model-invariance state abstraction. Next, we propose a practical method to approximately learn a model-invariant representation for complex domains. We validate our approach by showing improved modeling performance over standard maximum likelihood approaches on challenging tasks, such as the MuJoCo-based Humanoid. Furthermore, within the MBRL setting we show strong performance gains w.r.t. sample efficiency across a host of other continuous control tasks.
Diverse Auto-Curriculum is Critical for Successful Real-World Multiagent Learning Systems
Feb 16, 2021Multiagent reinforcement learning (MARL) has achieved a remarkable amount of success in solving various types of video games. A cornerstone of this success is the auto-curriculum framework, which shapes the learning process by continually creating new challenging tasks for agents to adapt to, thereby facilitating the acquisition of new skills. In order to extend MARL methods to real-world domains outside of video games, we envision in this blue sky paper that maintaining a diversity-aware auto-curriculum is critical for successful MARL applications. Specifically, we argue that \emph{behavioural diversity} is a pivotal, yet under-explored, component for real-world multiagent learning systems, and that significant work remains in understanding how to design a diversity-aware auto-curriculum. We list four open challenges for auto-curriculum techniques, which we believe deserve more attention from this community. Towards validating our vision, we recommend modelling realistic interactive behaviours in autonomous driving as an important test bed, and recommend the SMARTS/ULTRA benchmark.
Improving Reinforcement Learning with Human Assistance: An Argument for Human Subject Studies with HIPPO Gym
Feb 02, 2021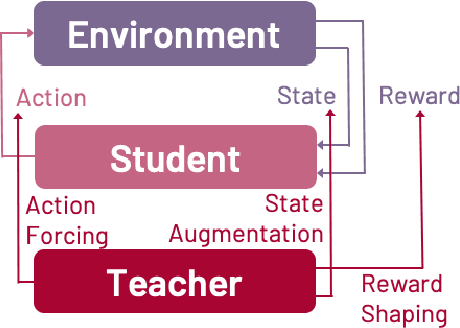
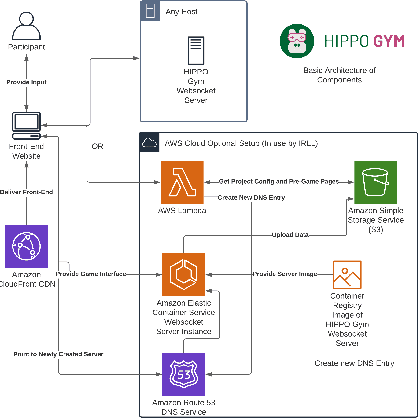
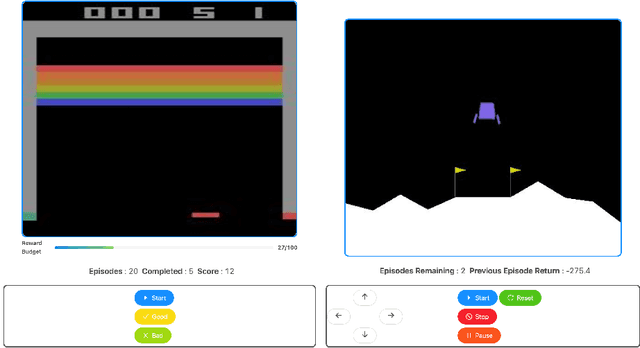
Reinforcement learning (RL) is a popular machine learning paradigm for game playing, robotics control, and other sequential decision tasks. However, RL agents often have long learning times with high data requirements because they begin by acting randomly. In order to better learn in complex tasks, this article argues that an external teacher can often significantly help the RL agent learn. OpenAI Gym is a common framework for RL research, including a large number of standard environments and agents, making RL research significantly more accessible. This article introduces our new open-source RL framework, the Human Input Parsing Platform for Openai Gym (HIPPO Gym), and the design decisions that went into its creation. The goal of this platform is to facilitate human-RL research, again lowering the bar so that more researchers can quickly investigate different ways that human teachers could assist RL agents, including learning from demonstrations, learning from feedback, or curriculum learning.
HAMMER: Multi-Level Coordination of Reinforcement Learning Agents via Learned Messaging
Jan 18, 2021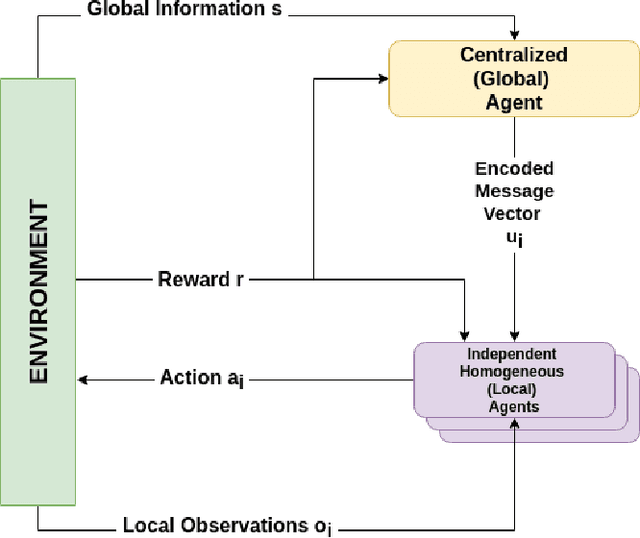
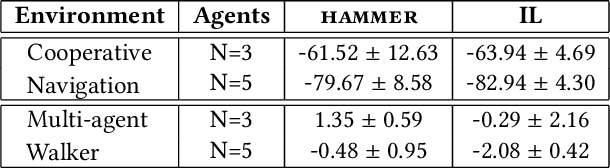


Cooperative multi-agent reinforcement learning (MARL) has achieved significant results, most notably by leveraging the representation learning abilities of deep neural networks. However, large centralized approaches quickly become infeasible as the number of agents scale, and fully decentralized approaches can miss important opportunities for information sharing and coordination. Furthermore, not all agents are equal - in some cases, individual agents may not even have the ability to send communication to other agents or explicitly model other agents. This paper considers the case where there is a single, powerful, central agent that can observe the entire observation space, and there are multiple, low powered, local agents that can only receive local observations and cannot communicate with each other. The job of the central agent is to learn what message to send to different local agents, based on the global observations, not by centrally solving the entire problem and sending action commands, but by determining what additional information an individual agent should receive so that it can make a better decision. After explaining our MARL algorithm, hammer, and where it would be most applicable, we implement it in the cooperative navigation and multi-agent walker domains. Empirical results show that 1) learned communication does indeed improve system performance, 2) results generalize to multiple numbers of agents, and 3) results generalize to different reward structures.
Useful Policy Invariant Shaping from Arbitrary Advice
Nov 02, 2020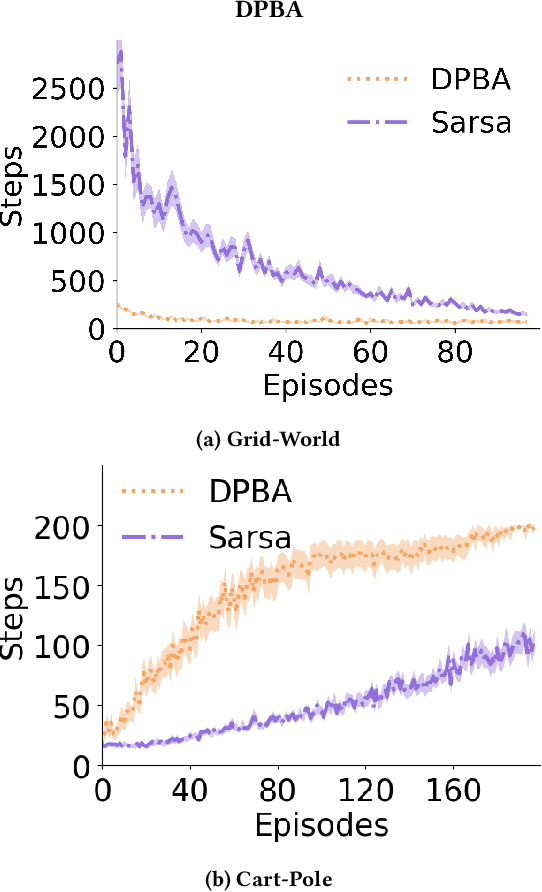

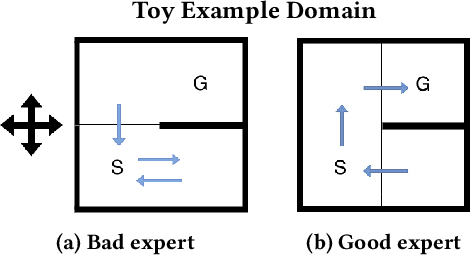

Reinforcement learning is a powerful learning paradigm in which agents can learn to maximize sparse and delayed reward signals. Although RL has had many impressive successes in complex domains, learning can take hours, days, or even years of training data. A major challenge of contemporary RL research is to discover how to learn with less data. Previous work has shown that domain information can be successfully used to shape the reward; by adding additional reward information, the agent can learn with much less data. Furthermore, if the reward is constructed from a potential function, the optimal policy is guaranteed to be unaltered. While such potential-based reward shaping (PBRS) holds promise, it is limited by the need for a well-defined potential function. Ideally, we would like to be able to take arbitrary advice from a human or other agent and improve performance without affecting the optimal policy. The recently introduced dynamic potential based advice (DPBA) method tackles this challenge by admitting arbitrary advice from a human or other agent and improves performance without affecting the optimal policy. The main contribution of this paper is to expose, theoretically and empirically, a flaw in DPBA. Alternatively, to achieve the ideal goals, we present a simple method called policy invariant explicit shaping (PIES) and show theoretically and empirically that PIES succeeds where DPBA fails.
Maximum Reward Formulation In Reinforcement Learning
Oct 08, 2020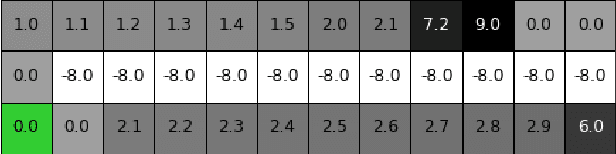
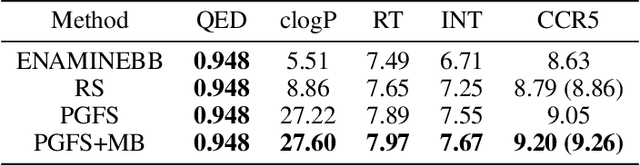
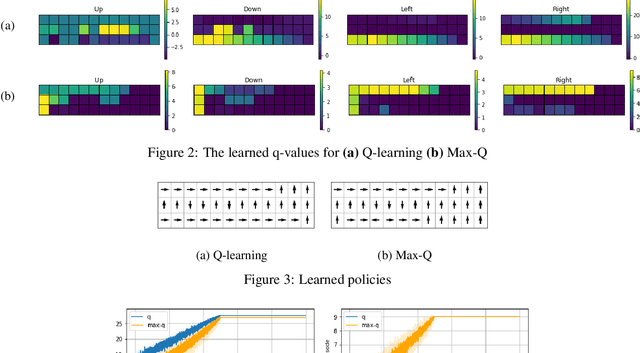
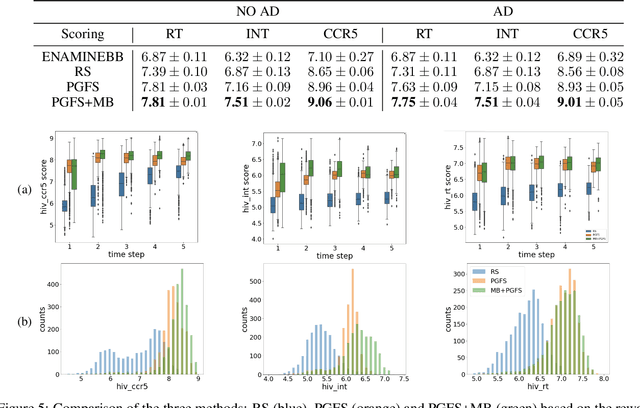
Reinforcement learning (RL) algorithms typically deal with maximizing the expected cumulative return (discounted or undiscounted, finite or infinite horizon). However, several crucial applications in the real world, such as drug discovery, do not fit within this framework because an RL agent only needs to identify states (molecules) that achieve the highest reward within a trajectory and does not need to optimize for the expected cumulative return. In this work, we formulate an objective function to maximize the expected maximum reward along a trajectory, derive a novel functional form of the Bellman equation, introduce the corresponding Bellman operators, and provide a proof of convergence. Using this formulation, we achieve state-of-the-art results on the task of molecule generation that mimics a real-world drug discovery pipeline.
Lucid Dreaming for Experience Replay: Refreshing Past States with the Current Policy
Sep 29, 2020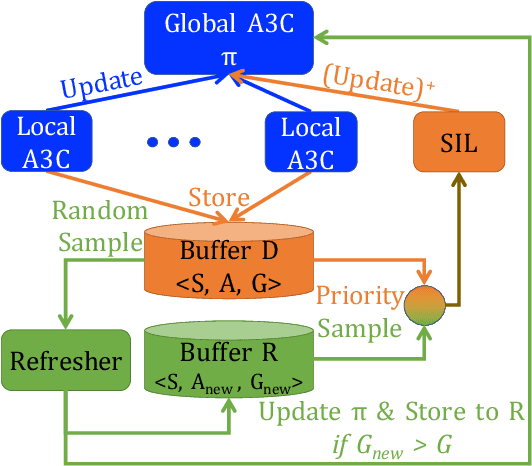

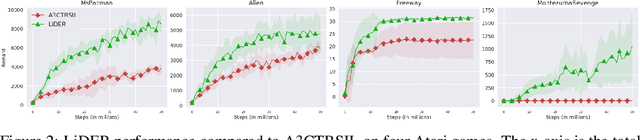
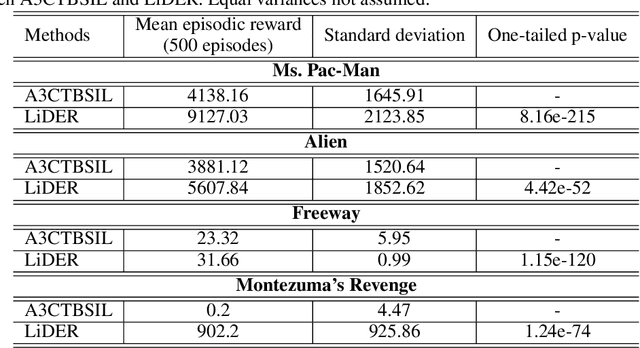
Experience replay (ER) improves the data efficiency of off-policy reinforcement learning (RL) algorithms by allowing an agent to store and reuse its past experiences in a replay buffer. While many techniques have been proposed to enhance ER by biasing how experiences are sampled from the buffer, thus far they have not considered strategies for refreshing experiences inside the buffer. In this work, we introduce Lucid Dreaming for Experience Replay (LiDER), a conceptually new framework that allows replay experiences to be refreshed by leveraging the agent's current policy. LiDER 1) moves an agent back to a past state; 2) lets the agent try following its current policy to execute different actions---as if the agent were "dreaming" about the past, but is aware of the situation and can control the dream to encounter new experiences; and 3) stores and reuses the new experience if it turned out better than what the agent previously experienced, i.e., to refresh its memories. LiDER is designed to be easily incorporated into off-policy, multi-worker RL algorithms that use ER; we present in this work a case study of applying LiDER to an actor-critic based algorithm. Results show LiDER consistently improves performance over the baseline in four Atari 2600 games. Our open-source implementation of LiDER and the data used to generate all plots in this paper are available at github.com/duyunshu/lucid-dreaming-for-exp-replay.