 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyadic Human Motion Prediction
Dec 01, 2021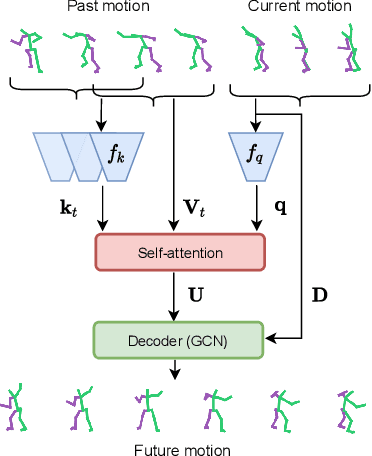
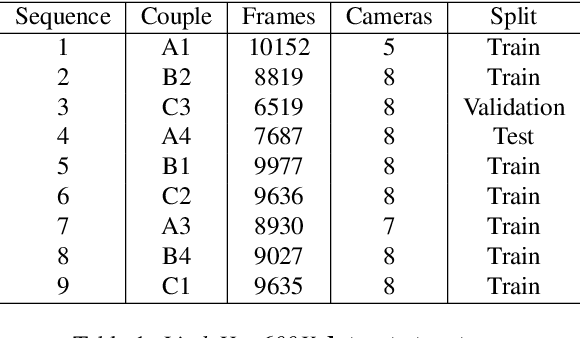
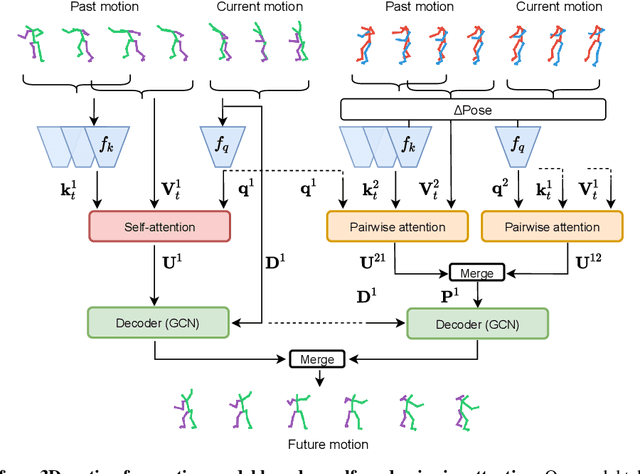

Prior work on human motion forecasting has mostly focused on predicting the future motion of single subjects in isolation from their past pose sequence. In the presence of closely interacting people, however, this strategy fails to account for the dependencies between the different subject's motions. In this paper, we therefore introduce a motion prediction framework that explicitly reasons about the interactions of two observed subjects. Specifically, we achieve this by introducing a pairwise attention mechanism that models the mutual dependencies in the motion history of the two subjects. This allows us to preserve the long-term motion dynamics in a more realistic way and more robustly predict unusual and fast-paced movements, such as the ones occurring in a dance scenario. To evaluate this, and because no existing motion prediction datasets depict two closely-interacting subjects, we introduce the LindyHop600K dance dataset. Our results evidence that our approach outperforms the state-of-the-art single person motion prediction techniques.
What Stops Learning-based 3D Registration from Working in the Real World?
Nov 19, 2021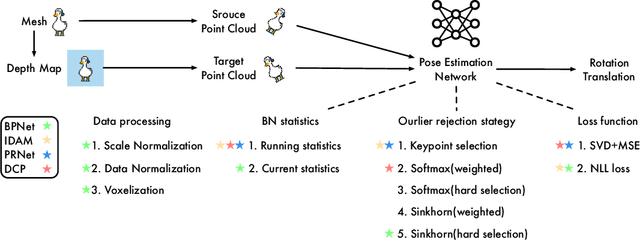



Much progress has been made on the task of learning-based 3D point cloud registration, with existing methods yielding outstanding results on standard benchmarks, such as ModelNet40, even in the partial-to-partial matching scenario. Unfortunately, these methods still struggle in the presence of real data. In this work, we identify the sources of these failures, analyze the reasons behind them, and propose solutions to tackle them. We summarise our findings into a set of guidelines and demonstrate their effectiveness by applying them to different baseline methods, DCP and IDAM. In short, our guidelines improve both their training convergence and testing accuracy. Ultimately, this translates to a best-practice 3D registration network (BPNet), constituting the first learning-based method able to handle previously-unseen objects in real-world data. Despite being trained only on synthetic data, our model generalizes to real data without any fine-tuning, reaching an accuracy of up to 67% on point clouds of unseen objects obtained with a commercial sensor.
Temporally-Consistent Surface Reconstruction using Metrically-Consistent Atlases
Nov 12, 2021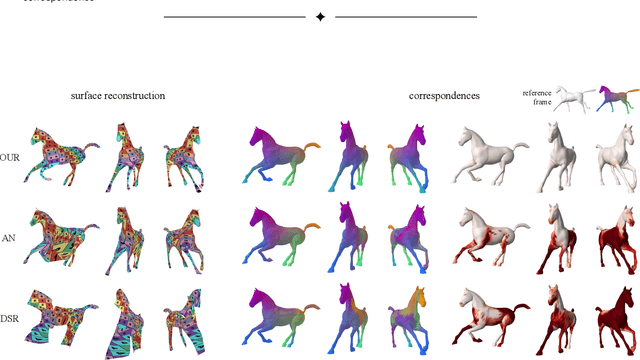
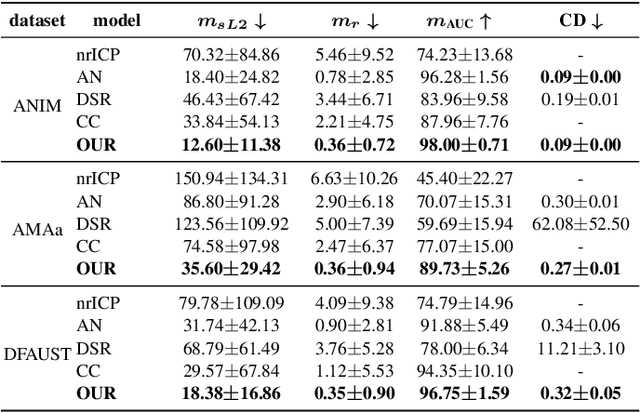
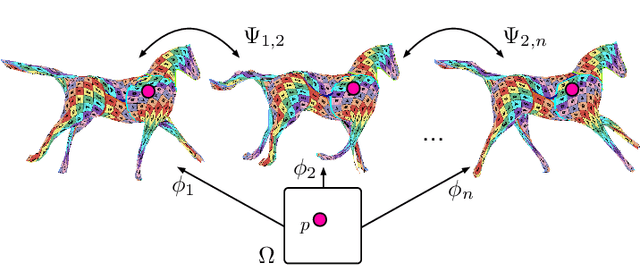
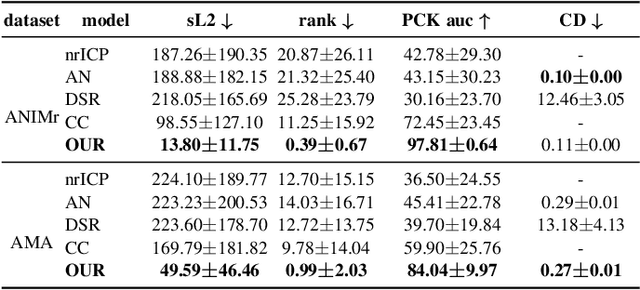
We propose a method for unsupervised reconstruction of a temporally-consistent sequence of surfaces from a sequence of time-evolving point clouds. It yields dense and semantically meaningful correspondences between frames. We represent the reconstructed surfaces as atlases computed by a neural network, which enables us to establish correspondences between frames. The key to making these correspondences semantically meaningful is to guarantee that the metric tensors computed at corresponding points are as similar as possible. We have devised an optimization strategy that makes our method robust to noise and global motions, without a priori correspondences or pre-alignment steps. As a result, our approach outperforms state-of-the-art ones on several challenging datasets. The code is available at https://github.com/bednarikjan/temporally_coherent_surface_reconstruction.
Estimating Image Depth in the Comics Domain
Oct 07, 2021
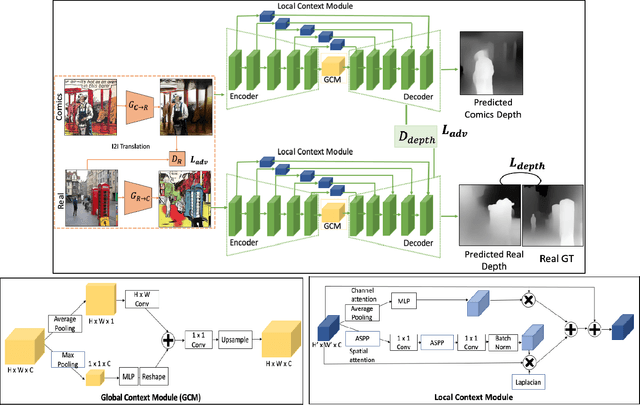
Estimating the depth of comics images is challenging as such images a) are monocular; b) lack ground-truth depth annotations; c) differ across different artistic styles; d) are sparse and noisy. We thus, use an off-the-shelf unsupervised image to image translation method to translate the comics images to natural ones and then use an attention-guided monocular depth estimator to predict their depth. This lets us leverage the depth annotations of existing natural images to train the depth estimator. Furthermore, our model learns to distinguish between text and images in the comics panels to reduce text-based artefacts in the depth estimates. Our method consistently outperforms the existing state-ofthe-art approaches across all metrics on both the DCM and eBDtheque images. Finally, we introduce a dataset to evaluate depth prediction on comics.
An Analysis of Super-Net Heuristics in Weight-Sharing NAS
Oct 04, 2021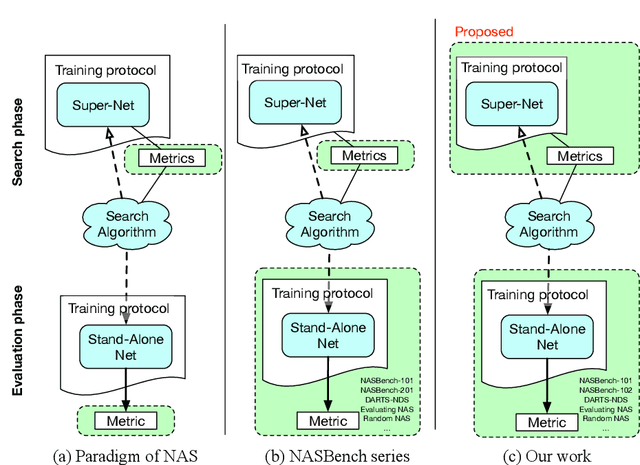
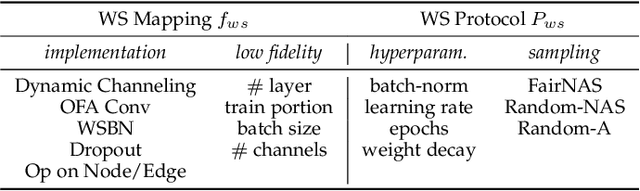
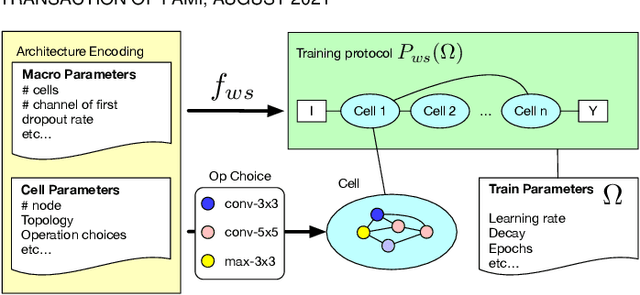
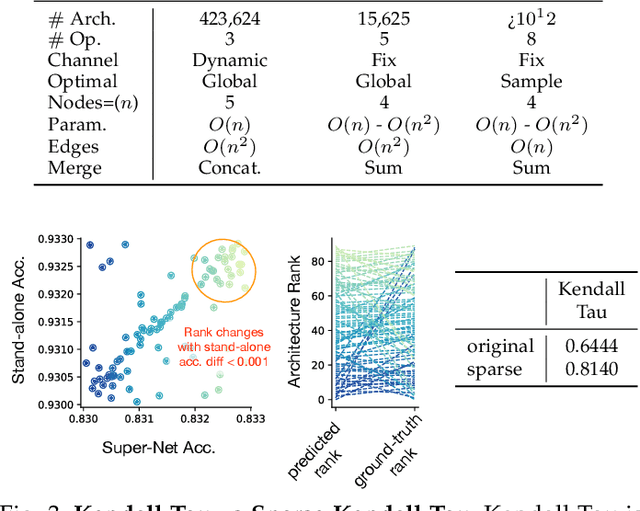
Weight sharing promises to make neural architecture search (NAS) tractable even on commodity hardware. Existing methods in this space rely on a diverse set of heuristics to design and train the shared-weight backbone network, a.k.a. the super-net. Since heuristics substantially vary across different methods and have not been carefully studied, it is unclear to which extent they impact super-net training and hence the weight-sharing NAS algorithms. In this paper, we disentangle super-net training from the search algorithm, isolate 14 frequently-used training heuristics, and evaluate them over three benchmark search spaces. Our analysis uncovers that several commonly-used heuristics negatively impact the correlation between super-net and stand-alone performance, whereas simple, but often overlooked factors, such as proper hyper-parameter settings, are key to achieve strong performance. Equipped with this knowledge, we show that simple random search achieves competitive performance to complex state-of-the-art NAS algorithms when the super-net is properly trained.
Generating Smooth Pose Sequences for Diverse Human Motion Prediction
Aug 21, 2021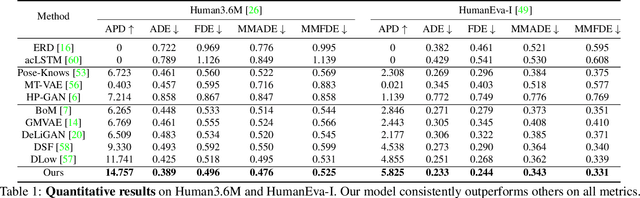
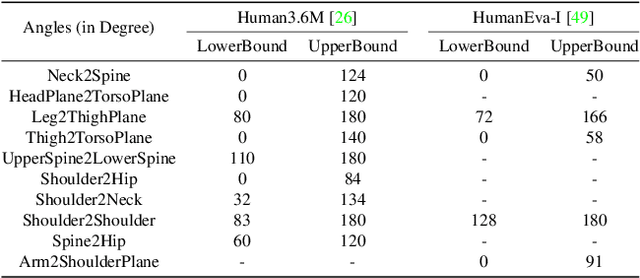
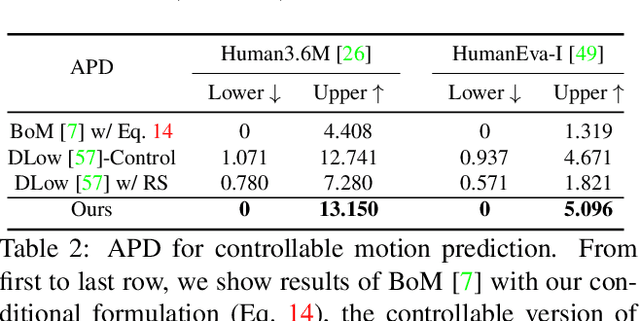
Recent progress in stochastic motion prediction, i.e., predicting multiple possible future human motions given a single past pose sequence, has led to producing truly diverse future motions and even providing control over the motion of some body parts. However, to achieve this, the state-of-the-art method requires learning several mappings for diversity and a dedicated model for controllable motion prediction. In this paper, we introduce a unified deep generative network for both diverse and controllable motion prediction. To this end, we leverage the intuition that realistic human motions consist of smooth sequences of valid poses, and that, given limited data, learning a pose prior is much more tractable than a motion one. We therefore design a generator that predicts the motion of different body parts sequentially, and introduce a normalizing flow based pose prior, together with a joint angle loss, to achieve motion realism.Our experiments on two standard benchmark datasets, Human3.6M and HumanEva-I, demonstrate that our approach outperforms the state-of-the-art baselines in terms of both sample diversity and accuracy. The code is available at https://github.com/wei-mao-2019/gsps
Multi-level Motion Attention for Human Motion Prediction
Jun 17, 2021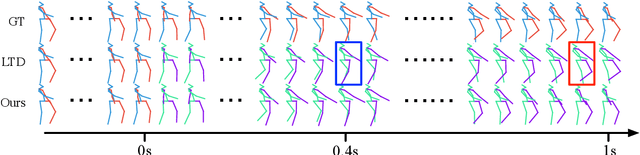
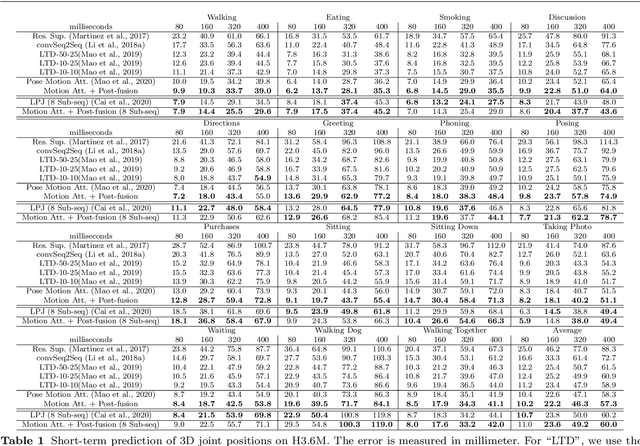
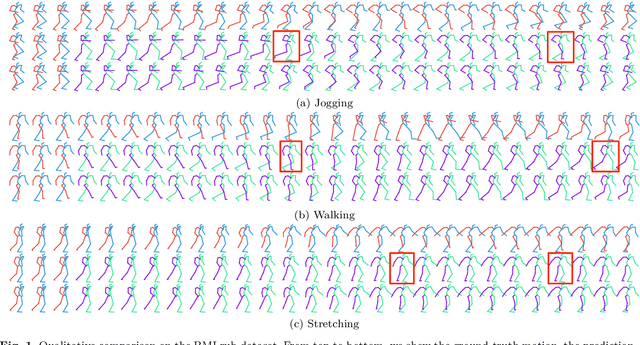

Human motion prediction aims to forecast future human poses given a historical motion. Whether based on recurrent or feed-forward neural networks, existing learning based methods fail to model the observation that human motion tends to repeat itself, even for complex sports actions and cooking activities. Here, we introduce an attention based feed-forward network that explicitly leverages this observation. In particular, instead of modeling frame-wise attention via pose similarity, we propose to extract motion attention to capture the similarity between the current motion context and the historical motion sub-sequences. In this context, we study the use of different types of attention, computed at joint, body part, and full pose levels. Aggregating the relevant past motions and processing the result with a graph convolutional network allows us to effectively exploit motion patterns from the long-term history to predict the future poses. Our experiments on Human3.6M, AMASS and 3DPW validate the benefits of our approach for both periodical and non-periodical actions. Thanks to our attention model, it yields state-of-the-art results on all three datasets. Our code is available at https://github.com/wei-mao-2019/HisRepItself.
Attention-based Domain Adaptation for Single Stage Detectors
Jun 14, 2021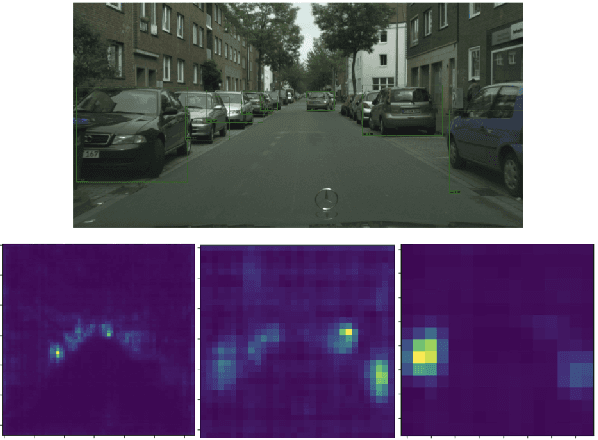
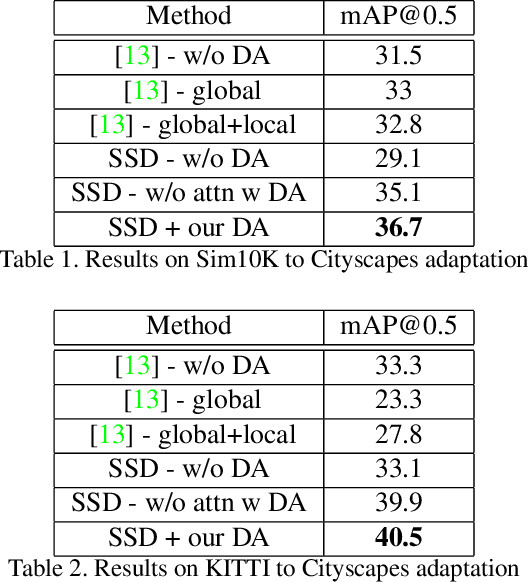
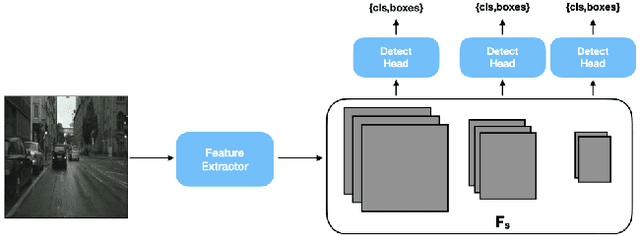
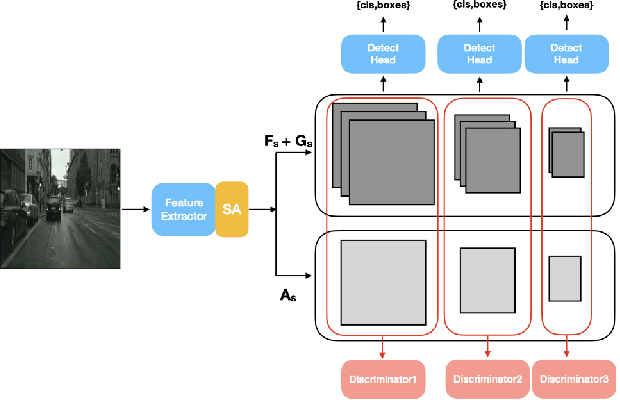
While domain adaptation has been used to improve the performance of object detectors when the training and test data follow different distributions, previous work has mostly focused on two-stage detectors. This is because their use of region proposals makes it possible to perform local adaptation, which has been shown to significantly improve the adaptation effectiveness. Here, by contrast, we target single-stage architectures, which are better suited to resource-constrained detection than two-stage ones but do not provide region proposals. To nonetheless benefit from the strength of local adaptation, we introduce an attention mechanism that lets us identify the important regions on which adaptation should focus. Our approach is generic and can be integrated into any single-stage detector. We demonstrate this on standard benchmark datasets by applying it to both SSD and YOLO. Furthermore, for an equivalent single-stage architecture, our method outperforms the state-of-the-art domain adaptation technique even though it was designed specifically for this particular detector.
Distilling Image Classifiers in Object Detectors
Jun 09, 2021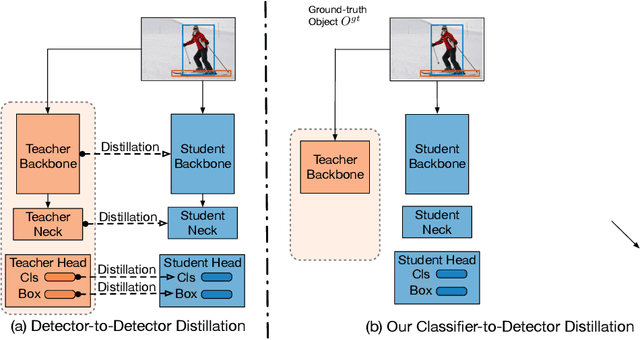
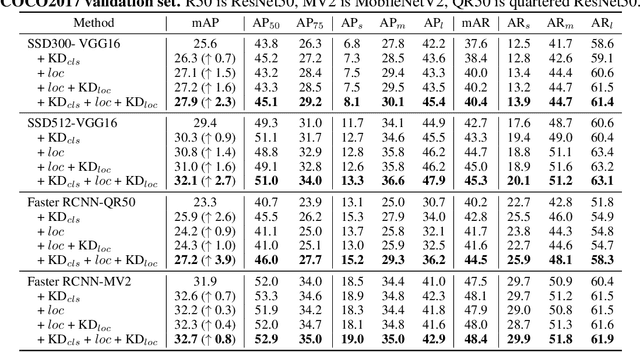
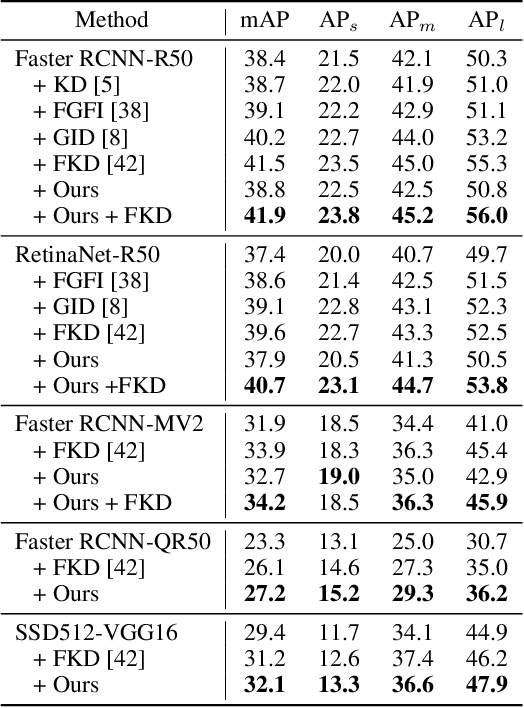

Knowledge distillation constitutes a simple yet effective way to improve the performance of a compact student network by exploiting the knowledge of a more powerful teacher. Nevertheless, the knowledge distillation literature remains limited to the scenario where the student and the teacher tackle the same task. Here, we investigate the problem of transferring knowledge not only across architectures but also across tasks. To this end, we study the case of object detection and, instead of following the standard detector-to-detector distillation approach, introduce a classifier-to-detector knowledge transfer framework. In particular, we propose strategies to exploit the classification teacher to improve both the detector's recognition accuracy and localization performance. Our experiments on several detectors with different backbones demonstrate the effectiveness of our approach, allowing us to outperform the state-of-the-art detector-to-detector distillation methods.
DAAIN: Detection of Anomalous and Adversarial Input using Normalizing Flows
May 30, 2021
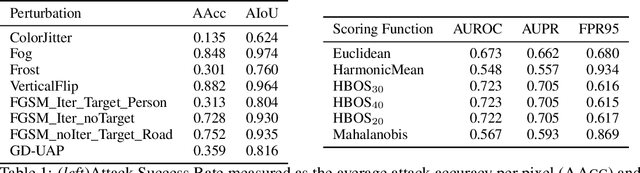
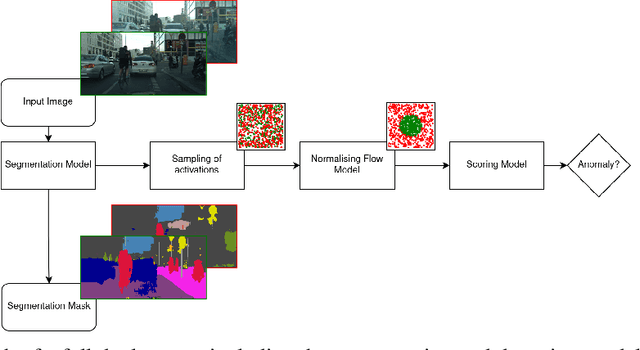
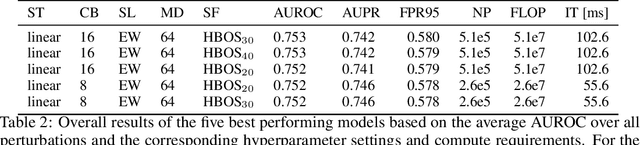
Despite much recent work, detecting out-of-distribution (OOD) inputs and adversarial attacks (AA) for computer vision models remains a challenge. In this work, we introduce a novel technique, DAAIN, to detect OOD inputs and AA for image segmentation in a unified setting. Our approach monitors the inner workings of a neural network and learns a density estimator of the activation distribution. We equip the density estimator with a classification head to discriminate between regular and anomalous inputs. To deal with the high-dimensional activation-space of typical segmentation networks, we subsample them to obtain a homogeneous spatial and layer-wise coverage. The subsampling pattern is chosen once per monitored model and kept fixed for all inputs. Since the attacker has access to neither the detection model nor the sampling key, it becomes harder for them to attack the segmentation network, as the attack cannot be backpropagated through the detector. We demonstrate the effectiveness of our approach using an ESPNet trained on the Cityscapes dataset as segmentation model, an affine Normalizing Flow as density estimator and use blue noise to ensure homogeneous sampling. Our model can be trained on a single GPU making it compute efficient and deployable without requiring specialized accelerators.