 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models are Realistic Tabular Data Generators
Oct 12, 2022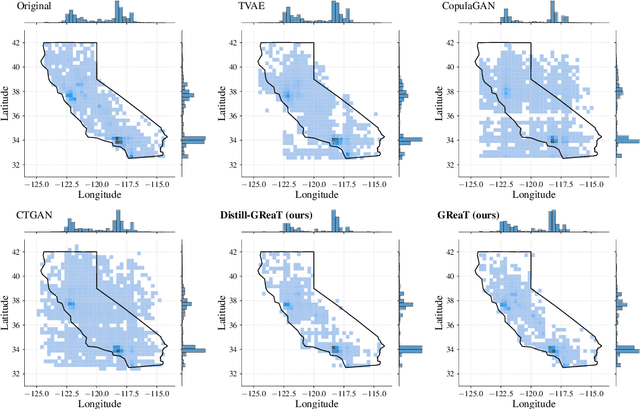
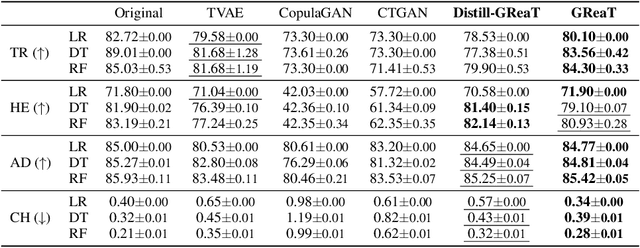
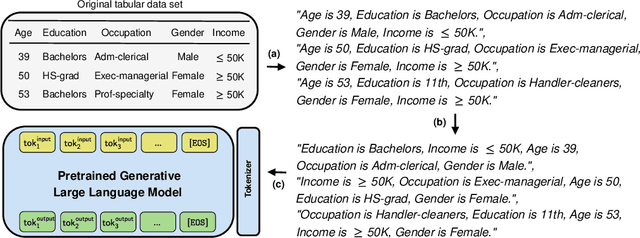
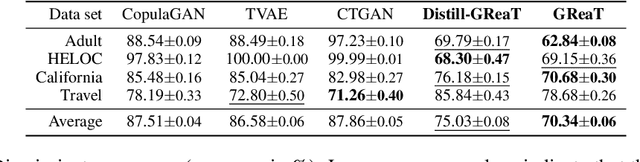
Tabular data is among the oldest and most ubiquitous forms of data. However, the generation of synthetic samples with the original data's characteristics still remains a significant challenge for tabular data. While many generative models from the computer vision domain, such as autoencoders or generative adversarial networks, have been adapted for tabular data generation, less research has been directed towards recent transformer-based large language models (LLMs), which are also generative in nature. To this end, we propose GReaT (Generation of Realistic Tabular data), which exploits an auto-regressive generative LLM to sample synthetic and yet highly realistic tabular data. Furthermore, GReaT can model tabular data distributions by conditioning on any subset of features; the remaining features are sampled without additional overhead. We demonstrate the effectiveness of the proposed approach in a series of experiments that quantify the validity and quality of the produced data samples from multiple angles. We find that GReaT maintains state-of-the-art performance across many real-world data sets with heterogeneous feature types.
On the Trade-Off between Actionable Explanations and the Right to be Forgotten
Aug 30, 2022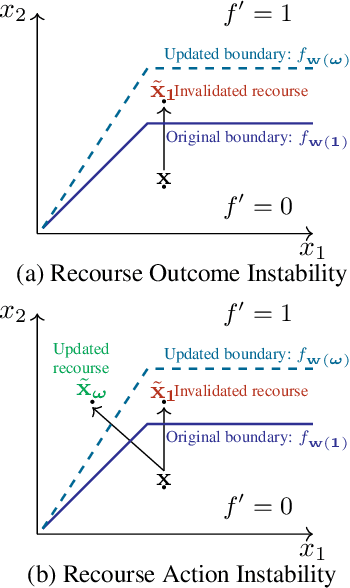

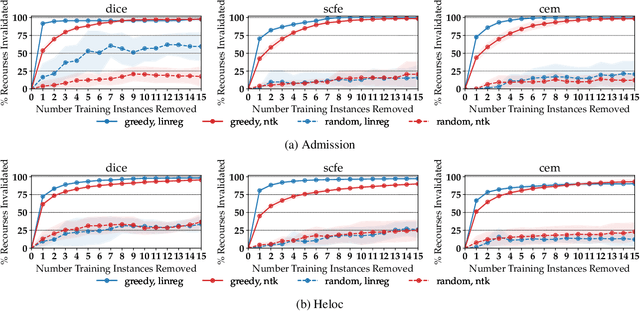
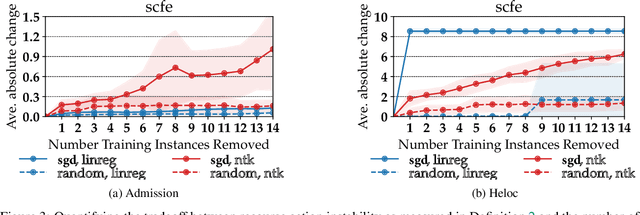
As machine learning (ML) models are increasingly being deployed in high-stakes applications, policymakers have suggested tighter data protection regulations (e.g., GDPR, CCPA). One key principle is the ``right to be forgotten'' which gives users the right to have their data deleted. Another key principle is the right to an actionable explanation, also known as algorithmic recourse, allowing users to reverse unfavorable decisions. To date it is unknown whether these two principles can be operationalized simultaneously. Therefore, we introduce and study the problem of recourse invalidation in the context of data deletion requests. More specifically, we theoretically and empirically analyze the behavior of popular state-of-the-art algorithms and demonstrate that the recourses generated by these algorithms are likely to be invalidated if a small number of data deletion requests (e.g., 1 or 2) warrant updates of the predictive model. For the setting of linear models and overparameterized neural networks -- studied through the lens of neural tangent kernels (NTKs) -- we suggest a framework to identify a minimal subset of critical training points, which when removed, would lead to maximize the fraction of invalidated recourses. Using our framework, we empirically establish that the removal of as little as 2 data instances from the training set can invalidate up to 95 percent of all recourses output by popular state-of-the-art algorithms. Thus, our work raises fundamental questions about the compatibility of ``the right to an actionable explanation'' in the context of the ``right to be forgotten''.
OpenXAI: Towards a Transparent Evaluation of Model Explanations
Jun 22, 2022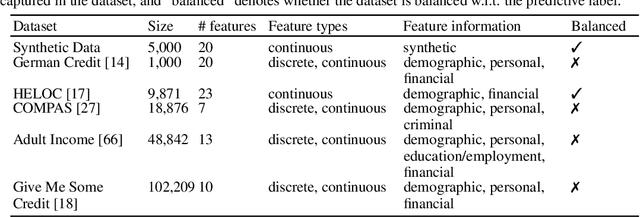
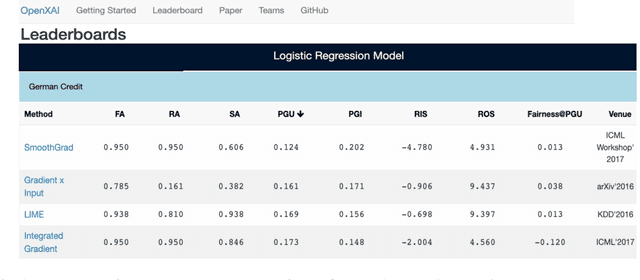
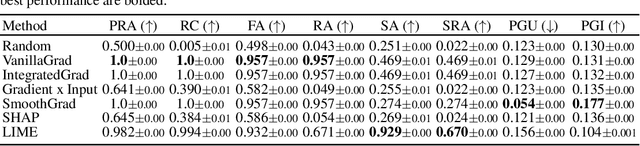
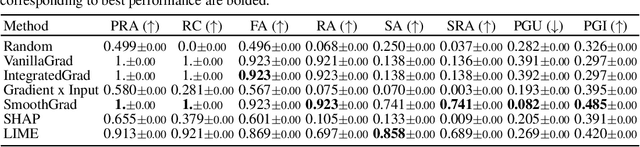
While several types of post hoc explanation methods (e.g., feature attribution methods) have been proposed in recent literature, there is little to no work on systematically benchmarking these methods in an efficient and transparent manner. Here, we introduce OpenXAI, a comprehensive and extensible open source framework for evaluating and benchmarking post hoc explanation methods. OpenXAI comprises of the following key components: (i) a flexible synthetic data generator and a collection of diverse real-world datasets, pre-trained models, and state-of-the-art feature attribution methods, (ii) open-source implementations of twenty-two quantitative metrics for evaluating faithfulness, stability (robustness), and fairness of explanation methods, and (iii) the first ever public XAI leaderboards to benchmark explanations. OpenXAI is easily extensible, as users can readily evaluate custom explanation methods and incorporate them into our leaderboards. Overall, OpenXAI provides an automated end-to-end pipeline that not only simplifies and standardizes the evaluation of post hoc explanation methods, but also promotes transparency and reproducibility in benchmarking these methods. OpenXAI datasets and data loaders, implementations of state-of-the-art explanation methods and evaluation metrics, as well as leaderboards are publicly available at https://open-xai.github.io/.
Rethinking Stability for Attribution-based Explanations
Mar 14, 2022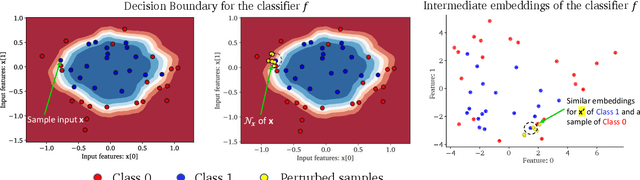


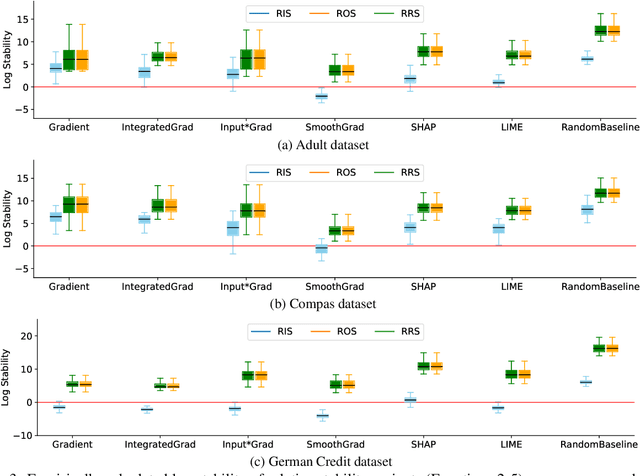
As attribution-based explanation methods are increasingly used to establish model trustworthiness in high-stakes situations, it is critical to ensure that these explanations are stable, e.g., robust to infinitesimal perturbations to an input. However, previous works have shown that state-of-the-art explanation methods generate unstable explanations. Here, we introduce metrics to quantify the stability of an explanation and show that several popular explanation methods are unstable. In particular, we propose new Relative Stability metrics that measure the change in output explanation with respect to change in input, model representation, or output of the underlying predictor. Finally, our experimental evaluation with three real-world datasets demonstrates interesting insights for seven explanation methods and different stability metrics.
Algorithmic Recourse in the Face of Noisy Human Responses
Mar 13, 2022

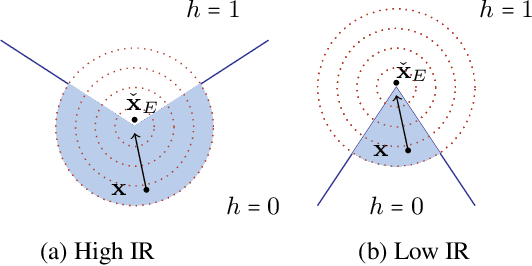

As machine learning (ML) models are increasingly being deployed in high-stakes applications, there has been growing interest in providing recourse to individuals adversely impacted by model predictions (e.g., an applicant whose loan has been denied). To this end, several post hoc techniques have been proposed in recent literature. These techniques generate recourses under the assumption that the affected individuals will implement the prescribed recourses exactly. However, recent studies suggest that individuals often implement recourses in a noisy and inconsistent manner - e.g., raising their salary by \$505 if the prescribed recourse suggested an increase of \$500. Motivated by this, we introduce and study the problem of recourse invalidation in the face of noisy human responses. More specifically, we theoretically and empirically analyze the behavior of state-of-the-art algorithms, and demonstrate that the recourses generated by these algorithms are very likely to be invalidated if small changes are made to them. We further propose a novel framework, EXPECTing noisy responses (EXPECT), which addresses the aforementioned problem by explicitly minimizing the probability of recourse invalidation in the face of noisy responses. Experimental evaluation with multiple real world datasets demonstrates the efficacy of the proposed framework, and supports our theoretical findings
Deep Neural Networks and Tabular Data: A Survey
Oct 05, 2021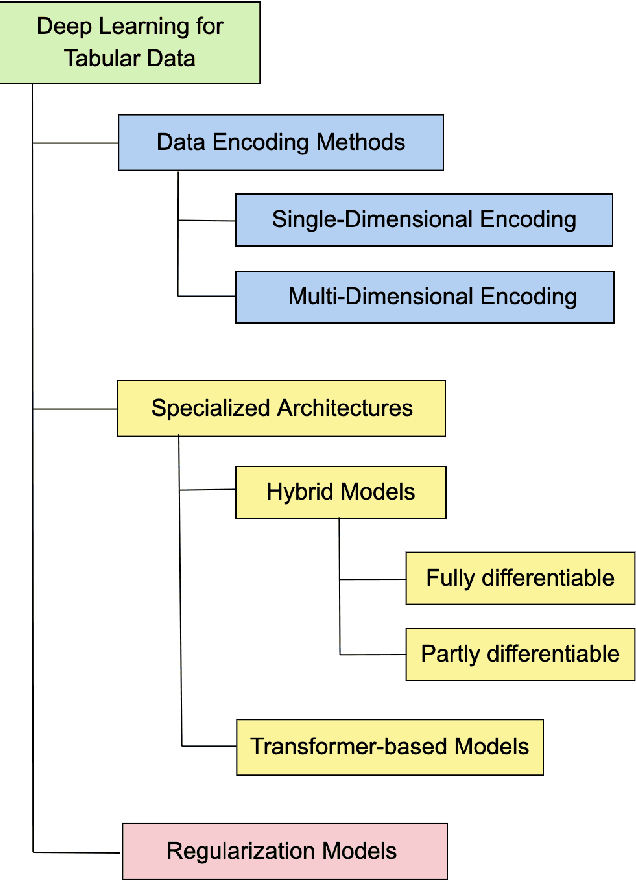
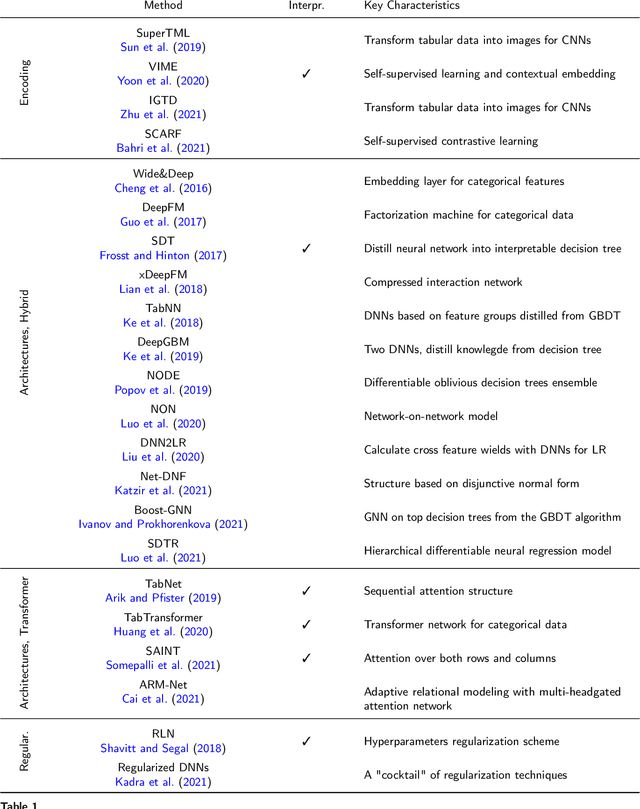
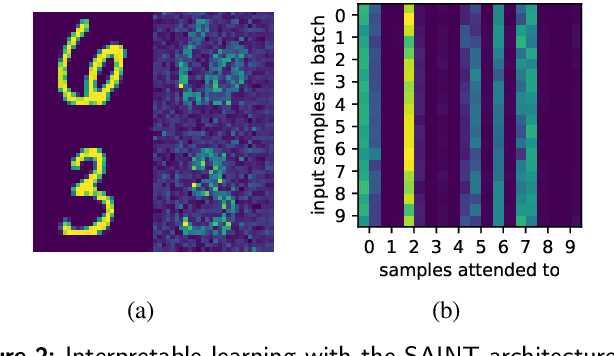
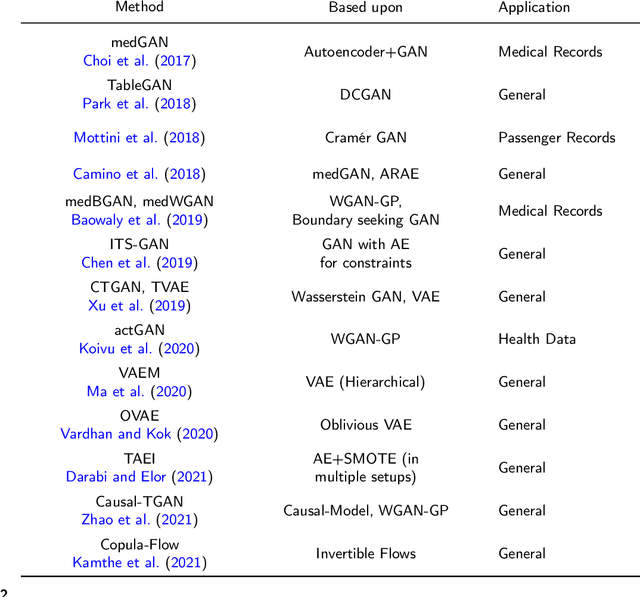
Heterogeneous tabular data are the most commonly used form of data and are essential for numerous critical and computationally demanding applications. On homogeneous data sets, deep neural networks have repeatedly shown excellent performance and have therefore been widely adopted. However, their application to modeling tabular data (inference or generation) remains highly challenging. This work provides an overview of state-of-the-art deep learning methods for tabular data. We start by categorizing them into three groups: data transformations, specialized architectures, and regularization models. We then provide a comprehensive overview of the main approaches in each group. A discussion of deep learning approaches for generating tabular data is complemented by strategies for explaining deep models on tabular data. Our primary contribution is to address the main research streams and existing methodologies in this area, while highlighting relevant challenges and open research questions. To the best of our knowledge, this is the first in-depth look at deep learning approaches for tabular data. This work can serve as a valuable starting point and guide for researchers and practitioners interested in deep learning with tabular data.
CARLA: A Python Library to Benchmark Algorithmic Recourse and Counterfactual Explanation Algorithms
Aug 02, 2021
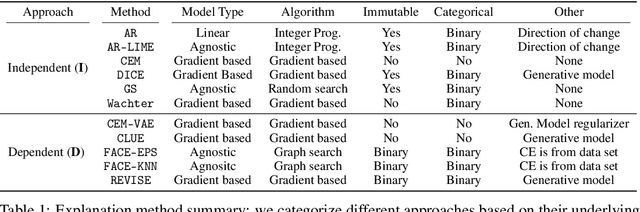
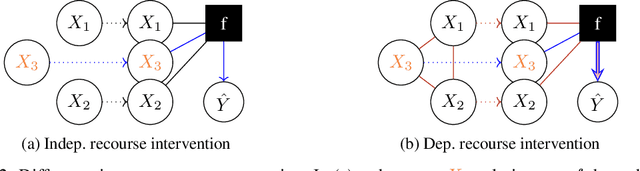
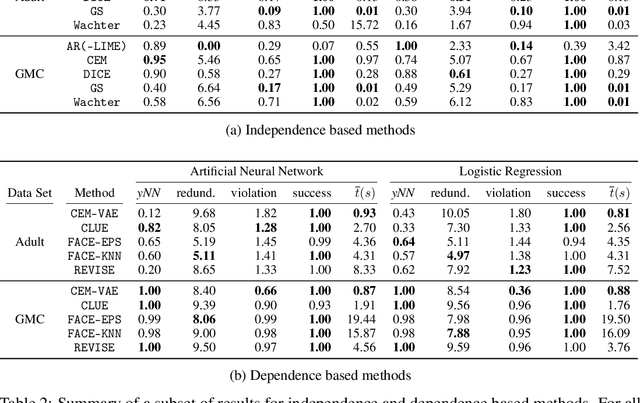
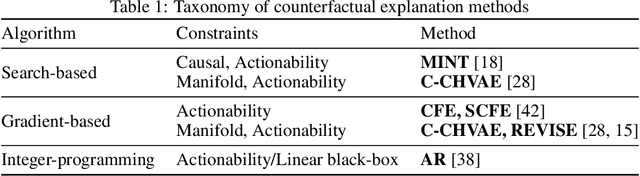
Counterfactual explanations provide means for prescriptive model explanations by suggesting actionable feature changes (e.g., increase income) that allow individuals to achieve favorable outcomes in the future (e.g., insurance approval). Choosing an appropriate method is a crucial aspect for meaningful counterfactual explanations. As documented in recent reviews, there exists a quickly growing literature with available methods. Yet, in the absence of widely available opensource implementations, the decision in favor of certain models is primarily based on what is readily available. Going forward - to guarantee meaningful comparisons across explanation methods - we present CARLA (Counterfactual And Recourse LibrAry), a python library for benchmarking counterfactual explanation methods across both different data sets and different machine learning models. In summary, our work provides the following contributions: (i) an extensive benchmark of 11 popular counterfactual explanation methods, (ii) a benchmarking framework for research on future counterfactual explanation methods, and (iii) a standardized set of integrated evaluation measures and data sets for transparent and extensive comparisons of these methods. We have open-sourced CARLA and our experimental results on Github, making them available as competitive baselines. We welcome contributions from other research groups and practitioners.
On the Connections between Counterfactual Explanations and Adversarial Examples
Jun 18, 2021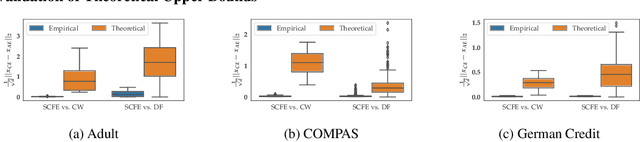
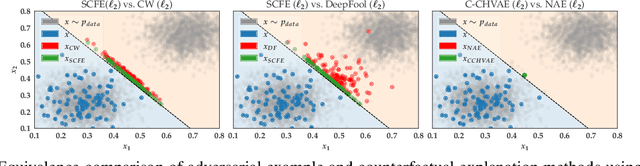

Counterfactual explanations and adversarial examples have emerged as critical research areas for addressing the explainability and robustness goals of machine learning (ML). While counterfactual explanations were developed with the goal of providing recourse to individuals adversely impacted by algorithmic decisions, adversarial examples were designed to expose the vulnerabilities of ML models. While prior research has hinted at the commonalities between these frameworks, there has been little to no work on systematically exploring the connections between the literature on counterfactual explanations and adversarial examples. In this work, we make one of the first attempts at formalizing the connections between counterfactual explanations and adversarial examples. More specifically, we theoretically analyze salient counterfactual explanation and adversarial example generation methods, and highlight the conditions under which they behave similarly. Our analysis demonstrates that several popular counterfactual explanation and adversarial example generation methods such as the ones proposed by Wachter et. al. and Carlini and Wagner (with mean squared error loss), and C-CHVAE and natural adversarial examples by Zhao et. al. are equivalent. We also bound the distance between counterfactual explanations and adversarial examples generated by Wachter et. al. and DeepFool methods for linear models. Finally, we empirically validate our theoretical findings using extensive experimentation with synthetic and real world datasets.
Gaussian Experts Selection using Graphical Models
Feb 04, 2021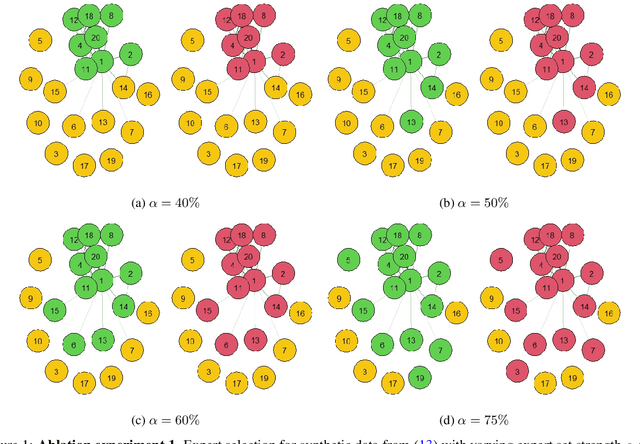
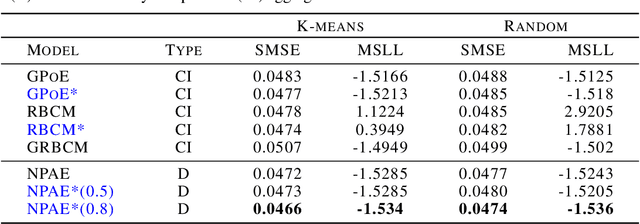
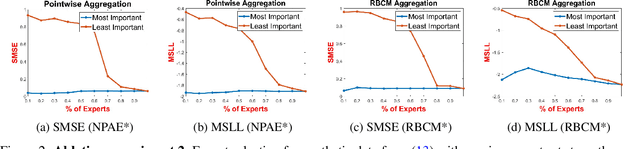
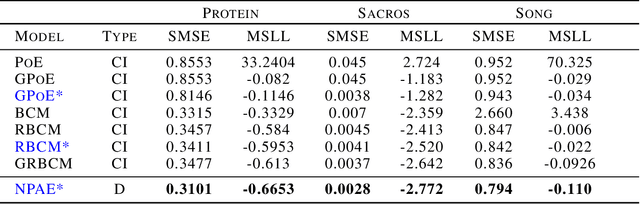
Local approximations are popular methods to scale Gaussian processes (GPs) to big data. Local approximations reduce time complexity by dividing the original dataset into subsets and training a local expert on each subset. Aggregating the experts' prediction is done assuming either conditional dependence or independence between the experts. Imposing the \emph{conditional independence assumption} (CI) between the experts renders the aggregation of different expert predictions time efficient at the cost of poor uncertainty quantification. On the other hand, modeling dependent experts can provide precise predictions and uncertainty quantification at the expense of impractically high computational costs. By eliminating weak experts via a theory-guided expert selection step, we substantially reduce the computational cost of aggregating dependent experts while ensuring calibrated uncertainty quantification. We leverage techniques from the literature on undirected graphical models, using sparse precision matrices that encode conditional dependencies between experts to select the most important experts. Moreov
On Counterfactual Explanations under Predictive Multiplicity
Jun 23, 2020
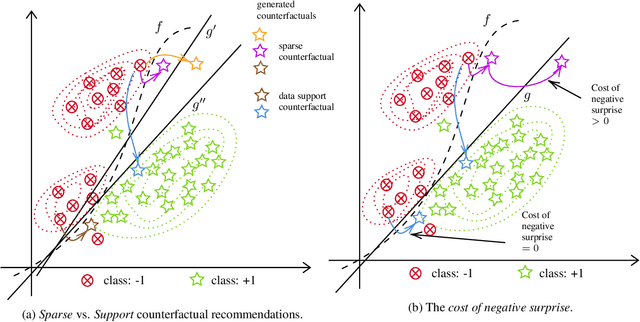
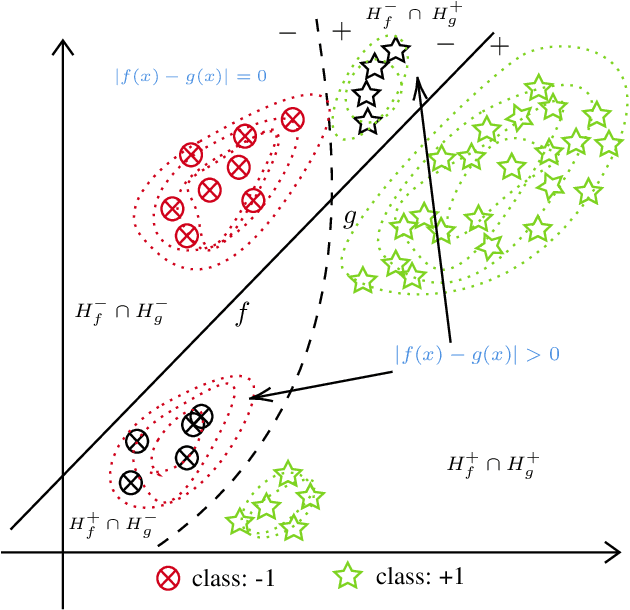
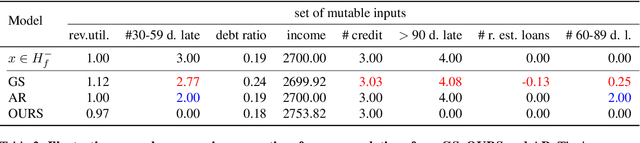
Counterfactual explanations are usually obtained by identifying the smallest change made to an input to change a prediction made by a fixed model (hereafter called sparse methods). Recent work, however, has revitalized an old insight: there often does not exist one superior solution to a prediction problem with respect to commonly used measures of interest (e.g. error rate). In fact, often multiple different classifiers give almost equal solutions. This phenomenon is known as predictive multiplicity (Breiman, 2001; Marx et al., 2019). In this work, we derive a general upper bound for the costs of counterfactual explanations under predictive multiplicity. Most notably, it depends on a discrepancy notion between two classifiers, which describes how differently they treat negatively predicted individuals. We then compare sparse and data support approaches empirically on real-world data. The results show that data support methods are more robust to multiplicity of different models. At the same time, we show that those methods have provably higher cost of generating counterfactual explanations under one fixed model. In summary, our theoretical and empiricaln results challenge the commonly held view that counterfactual recommendations should be sparse in general.