 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving ML Attacks on LWE with Data Repetition and Stepwise Regression
Apr 05, 2026The Learning with Errors (LWE) problem is a hard math problem in lattice-based cryptography. In the simplest case of binary secrets, it is the subset sum problem, with error. Effective ML attacks on LWE were demonstrated in the case of binary, ternary, and small secrets, succeeding on fairly sparse secrets. The ML attacks recover secrets with up to 3 active bits in the "cruel region" (Nolte et al., 2024) on samples pre-processed with BKZ. We show that using larger training sets and repeated examples enables recovery of denser secrets. Empirically, we observe a power-law relationship between model-based attempts to recover the secrets, dataset size, and repeated examples. We introduce a stepwise regression technique to recover the "cool bits" of the secret.
Calibrating LLM Judges: Linear Probes for Fast and Reliable Uncertainty Estimation
Dec 23, 2025As LLM-based judges become integral to industry applications, obtaining well-calibrated uncertainty estimates efficiently has become critical for production deployment. However, existing techniques, such as verbalized confidence and multi-generation methods, are often either poorly calibrated or computationally expensive. We introduce linear probes trained with a Brier score-based loss to provide calibrated uncertainty estimates from reasoning judges' hidden states, requiring no additional model training. We evaluate our approach on both objective tasks (reasoning, mathematics, factuality, coding) and subjective human preference judgments. Our results demonstrate that probes achieve superior calibration compared to existing methods with $\approx10$x computational savings, generalize robustly to unseen evaluation domains, and deliver higher accuracy on high-confidence predictions. However, probes produce conservative estimates that underperform on easier datasets but may benefit safety-critical deployments prioritizing low false-positive rates. Overall, our work demonstrates that interpretability-based uncertainty estimation provides a practical and scalable plug-and-play solution for LLM judges in production.
Teaching Transformers Modular Arithmetic at Scale
Oct 04, 2024



Modular addition is, on its face, a simple operation: given $N$ elements in $\mathbb{Z}_q$, compute their sum modulo $q$. Yet, scalable machine learning solutions to this problem remain elusive: prior work trains ML models that sum $N \le 6$ elements mod $q \le 1000$. Promising applications of ML models for cryptanalysis-which often involve modular arithmetic with large $N$ and $q$-motivate reconsideration of this problem. This work proposes three changes to the modular addition model training pipeline: more diverse training data, an angular embedding, and a custom loss function. With these changes, we demonstrate success with our approach for $N = 256, q = 3329$, a case which is interesting for cryptographic applications, and a significant increase in $N$ and $q$ over prior work. These techniques also generalize to other modular arithmetic problems, motivating future work.
Salsa Fresca: Angular Embeddings and Pre-Training for ML Attacks on Learning With Errors
Feb 02, 2024



Learning with Errors (LWE) is a hard math problem underlying recently standardized post-quantum cryptography (PQC) systems for key exchange and digital signatures. Prior work proposed new machine learning (ML)-based attacks on LWE problems with small, sparse secrets, but these attacks require millions of LWE samples to train on and take days to recover secrets. We propose three key methods -- better preprocessing, angular embeddings and model pre-training -- to improve these attacks, speeding up preprocessing by $25\times$ and improving model sample efficiency by $10\times$. We demonstrate for the first time that pre-training improves and reduces the cost of ML attacks on LWE. Our architecture improvements enable scaling to larger-dimension LWE problems: this work is the first instance of ML attacks recovering sparse binary secrets in dimension $n=1024$, the smallest dimension used in practice for homomorphic encryption applications of LWE where sparse binary secrets are proposed.
OpenXAI: Towards a Transparent Evaluation of Model Explanations
Jun 22, 2022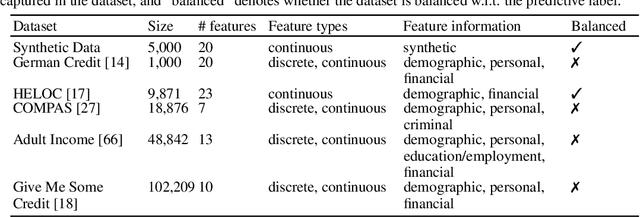
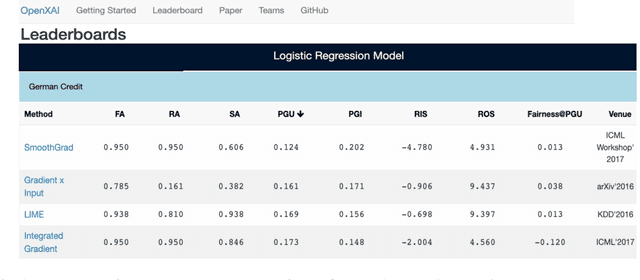
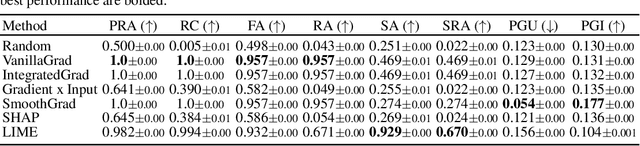
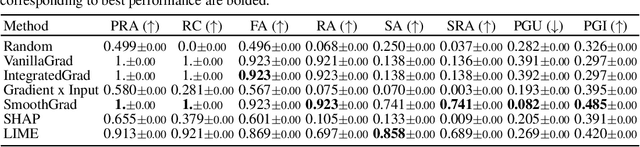
While several types of post hoc explanation methods (e.g., feature attribution methods) have been proposed in recent literature, there is little to no work on systematically benchmarking these methods in an efficient and transparent manner. Here, we introduce OpenXAI, a comprehensive and extensible open source framework for evaluating and benchmarking post hoc explanation methods. OpenXAI comprises of the following key components: (i) a flexible synthetic data generator and a collection of diverse real-world datasets, pre-trained models, and state-of-the-art feature attribution methods, (ii) open-source implementations of twenty-two quantitative metrics for evaluating faithfulness, stability (robustness), and fairness of explanation methods, and (iii) the first ever public XAI leaderboards to benchmark explanations. OpenXAI is easily extensible, as users can readily evaluate custom explanation methods and incorporate them into our leaderboards. Overall, OpenXAI provides an automated end-to-end pipeline that not only simplifies and standardizes the evaluation of post hoc explanation methods, but also promotes transparency and reproducibility in benchmarking these methods. OpenXAI datasets and data loaders, implementations of state-of-the-art explanation methods and evaluation metrics, as well as leaderboards are publicly available at https://open-xai.github.io/.
Rethinking Stability for Attribution-based Explanations
Mar 14, 2022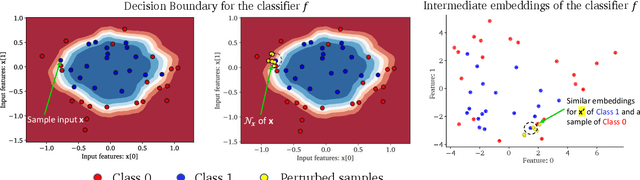


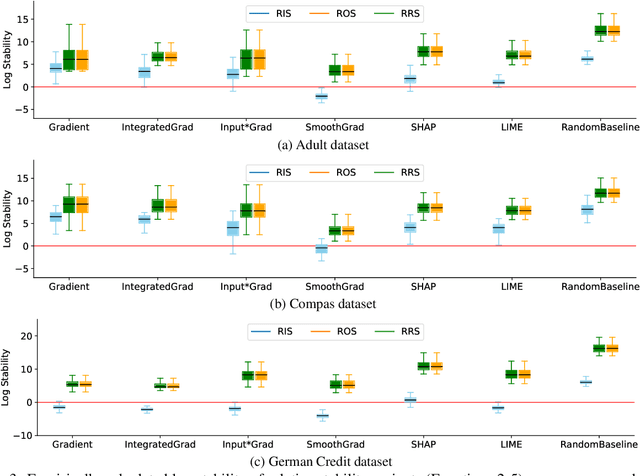
As attribution-based explanation methods are increasingly used to establish model trustworthiness in high-stakes situations, it is critical to ensure that these explanations are stable, e.g., robust to infinitesimal perturbations to an input. However, previous works have shown that state-of-the-art explanation methods generate unstable explanations. Here, we introduce metrics to quantify the stability of an explanation and show that several popular explanation methods are unstable. In particular, we propose new Relative Stability metrics that measure the change in output explanation with respect to change in input, model representation, or output of the underlying predictor. Finally, our experimental evaluation with three real-world datasets demonstrates interesting insights for seven explanation methods and different stability metrics.