 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing & Finding Good Data Orderings for Fast Convergence of Sequential Gradient Methods
Feb 03, 2022
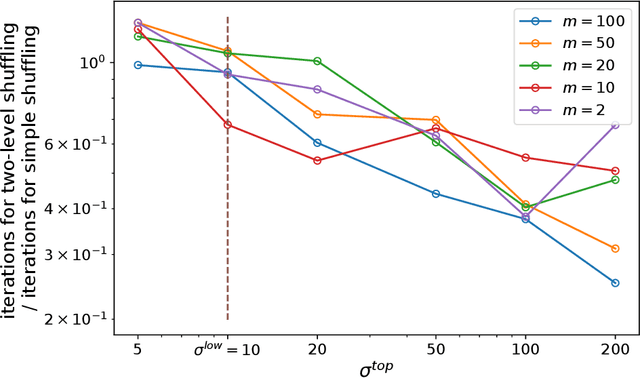
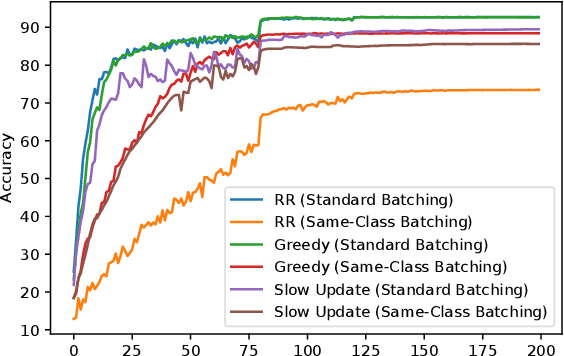
While SGD, which samples from the data with replacement is widely studied in theory, a variant called Random Reshuffling (RR) is more common in practice. RR iterates through random permutations of the dataset and has been shown to converge faster than SGD. When the order is chosen deterministically, a variant called incremental gradient descent (IG), the existing convergence bounds show improvement over SGD but are worse than RR. However, these bounds do not differentiate between a good and a bad ordering and hold for the worst choice of order. Meanwhile, in some cases, choosing the right order when using IG can lead to convergence faster than RR. In this work, we quantify the effect of order on convergence speed, obtaining convergence bounds based on the chosen sequence of permutations while also recovering previous results for RR. In addition, we show benefits of using structured shuffling when various levels of abstractions (e.g. tasks, classes, augmentations, etc.) exists in the dataset in theory and in practice. Finally, relying on our measure, we develop a greedy algorithm for choosing good orders during training, achieving superior performance (by more than 14 percent in accuracy) over RR.
Byzantine-Robust Decentralized Learning via Self-Centered Clipping
Feb 03, 2022



In this paper, we study the challenging task of Byzantine-robust decentralized training on arbitrary communication graphs. Unlike federated learning where workers communicate through a server, workers in the decentralized environment can only talk to their neighbors, making it harder to reach consensus. We identify a novel dissensus attack in which few malicious nodes can take advantage of information bottlenecks in the topology to poison the collaboration. To address these issues, we propose a Self-Centered Clipping (SCClip) algorithm for Byzantine-robust consensus and optimization, which is the first to provably converge to a $O(\delta_{\max}\zeta^2/\gamma^2)$ neighborhood of the stationary point for non-convex objectives under standard assumptions. Finally, we demonstrate the encouraging empirical performance of SCClip under a large number of attacks.
Understanding Memorization from the Perspective of Optimization via Efficient Influence Estimation
Dec 16, 2021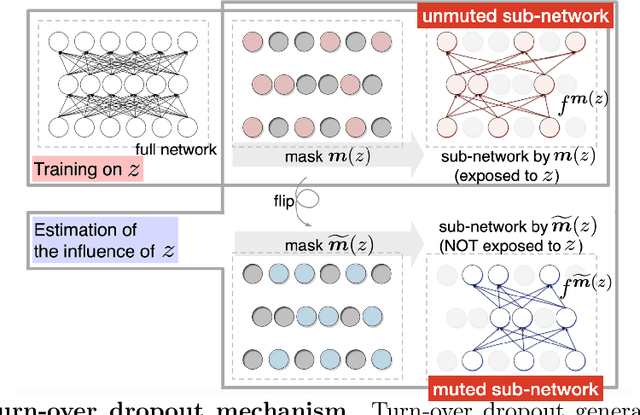
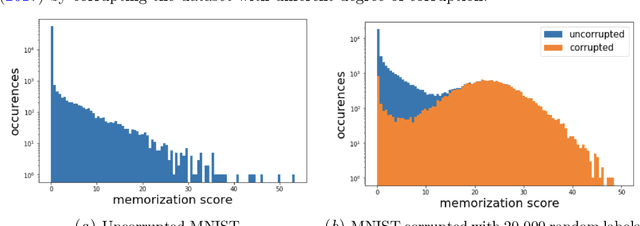
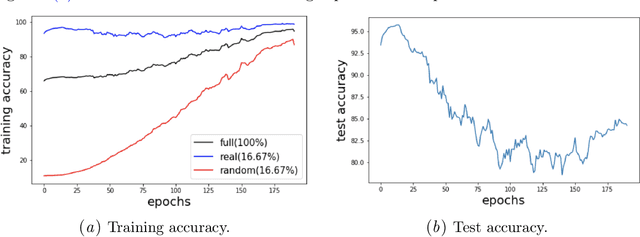
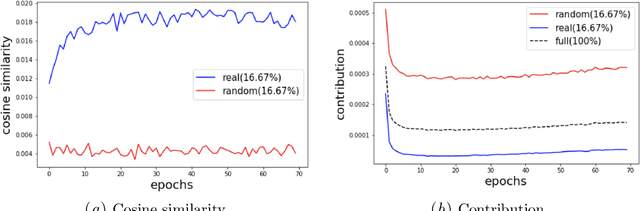
Over-parameterized deep neural networks are able to achieve excellent training accuracy while maintaining a small generalization error. It has also been found that they are able to fit arbitrary labels, and this behaviour is referred to as the phenomenon of memorization. In this work, we study the phenomenon of memorization with turn-over dropout, an efficient method to estimate influence and memorization, for data with true labels (real data) and data with random labels (random data). Our main findings are: (i) For both real data and random data, the optimization of easy examples (e.g., real data) and difficult examples (e.g., random data) are conducted by the network simultaneously, with easy ones at a higher speed; (ii) For real data, a correct difficult example in the training dataset is more informative than an easy one. By showing the existence of memorization on random data and real data, we highlight the consistency between them regarding optimization and we emphasize the implication of memorization during optimization.
Interpreting Language Models Through Knowledge Graph Extraction
Nov 16, 2021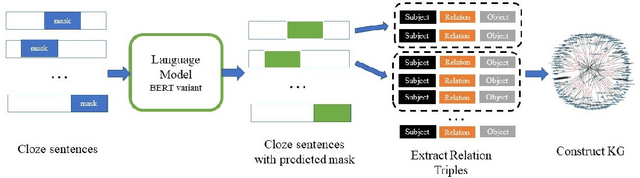
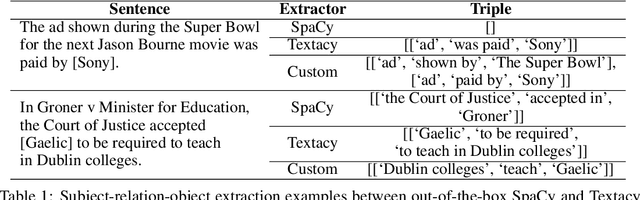

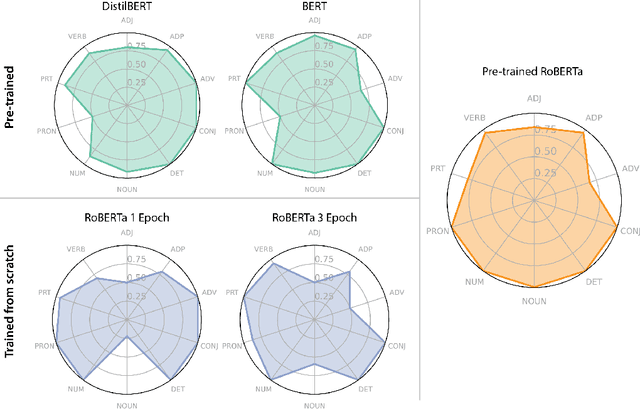
Transformer-based language models trained on large text corpora have enjoyed immense popularity in the natural language processing community and are commonly used as a starting point for downstream tasks. While these models are undeniably useful, it is a challenge to quantify their performance beyond traditional accuracy metrics. In this paper, we compare BERT-based language models through snapshots of acquired knowledge at sequential stages of the training process. Structured relationships from training corpora may be uncovered through querying a masked language model with probing tasks. We present a methodology to unveil a knowledge acquisition timeline by generating knowledge graph extracts from cloze "fill-in-the-blank" statements at various stages of RoBERTa's early training. We extend this analysis to a comparison of pretrained variations of BERT models (DistilBERT, BERT-base, RoBERTa). This work proposes a quantitative framework to compare language models through knowledge graph extraction (GED, Graph2Vec) and showcases a part-of-speech analysis (POSOR) to identify the linguistic strengths of each model variant. Using these metrics, machine learning practitioners can compare models, diagnose their models' behavioral strengths and weaknesses, and identify new targeted datasets to improve model performance.
Linear Speedup in Personalized Collaborative Learning
Nov 10, 2021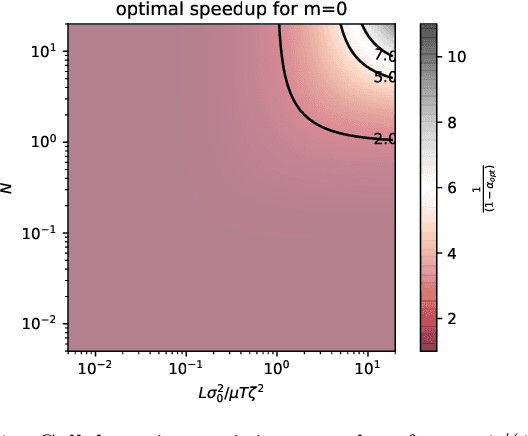
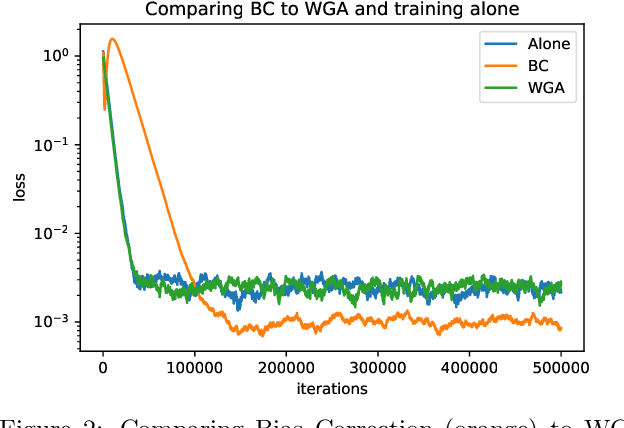
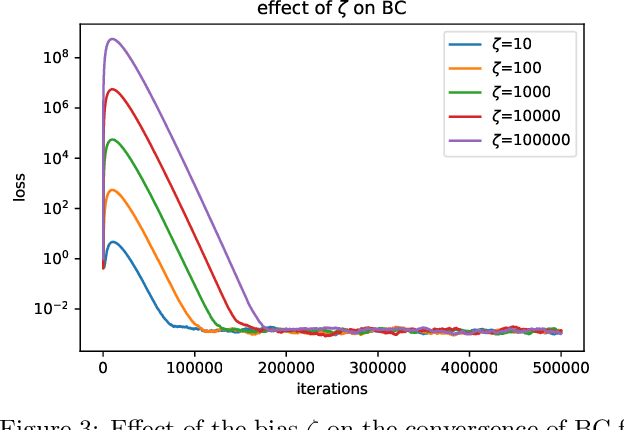
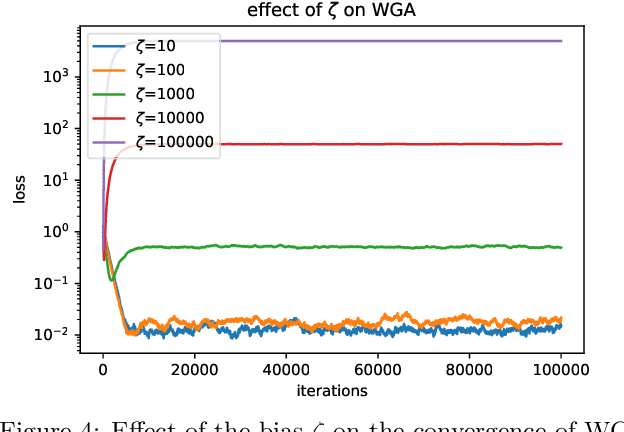
Personalization in federated learning can improve the accuracy of a model for a user by trading off the model's bias (introduced by using data from other users who are potentially different) against its variance (due to the limited amount of data on any single user). In order to develop training algorithms that optimally balance this trade-off, it is necessary to extend our theoretical foundations. In this work, we formalize the personalized collaborative learning problem as stochastic optimization of a user's objective $f_0(x)$ while given access to $N$ related but different objectives of other users $\{f_1(x), \dots, f_N(x)\}$. We give convergence guarantees for two algorithms in this setting -- a popular personalization method known as \emph{weighted gradient averaging}, and a novel \emph{bias correction} method -- and explore conditions under which we can optimally trade-off their bias for a reduction in variance and achieve linear speedup w.r.t.\ the number of users $N$. Further, we also empirically study their performance confirming our theoretical insights.
Optimal Model Averaging: Towards Personalized Collaborative Learning
Oct 25, 2021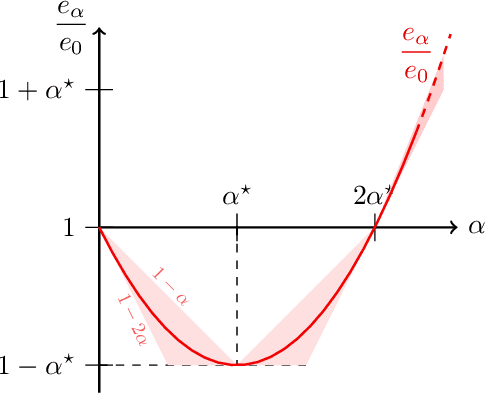
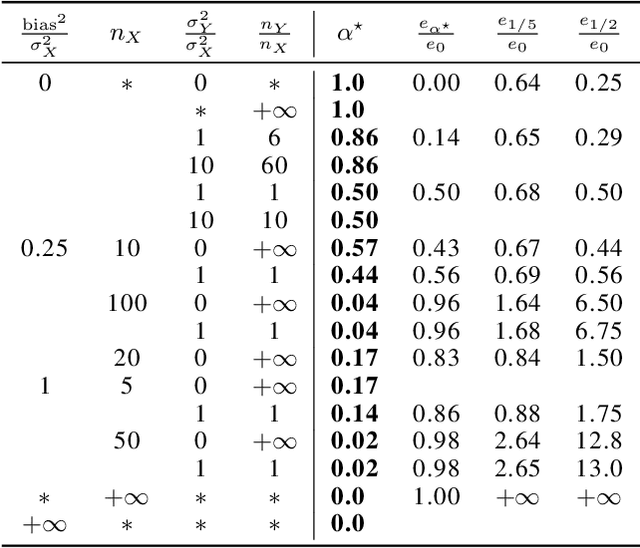
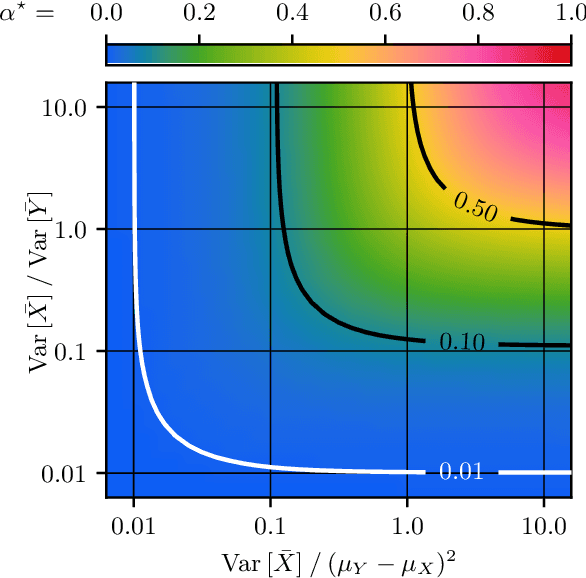
In federated learning, differences in the data or objectives between the participating nodes motivate approaches to train a personalized machine learning model for each node. One such approach is weighted averaging between a locally trained model and the global model. In this theoretical work, we study weighted model averaging for arbitrary scalar mean estimation problems under minimal assumptions on the distributions. In a variant of the bias-variance trade-off, we find that there is always some positive amount of model averaging that reduces the expected squared error compared to the local model, provided only that the local model has a non-zero variance. Further, we quantify the (possibly negative) benefit of weighted model averaging as a function of the weight used and the optimal weight. Taken together, this work formalizes an approach to quantify the value of personalization in collaborative learning and provides a framework for future research to test the findings in multivariate parameter estimation and under a range of assumptions.
WAFFLE: Weighted Averaging for Personalized Federated Learning
Oct 13, 2021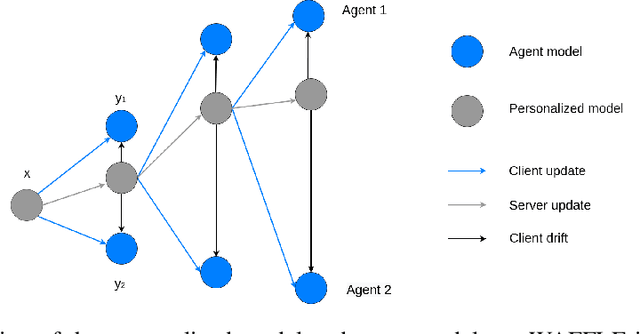

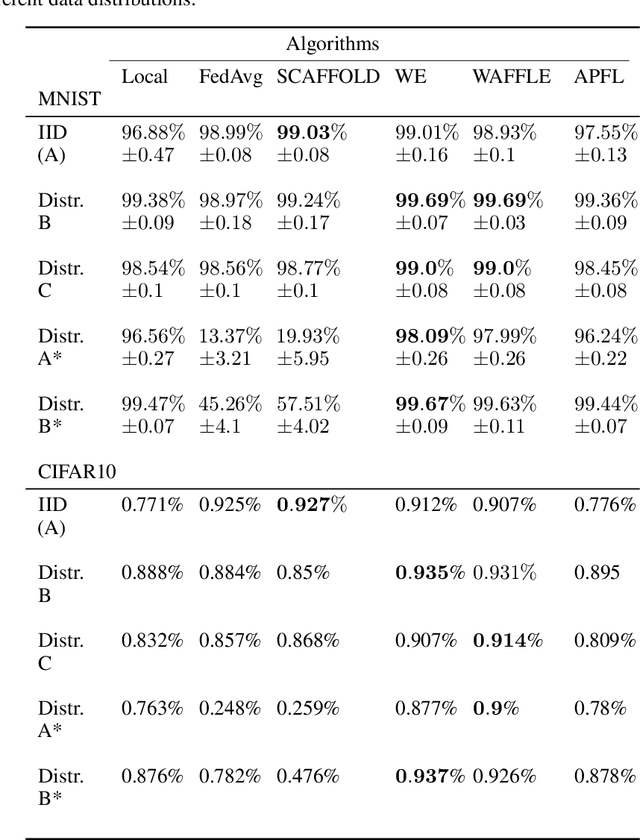
In collaborative or federated learning, model personalization can be a very effective strategy to deal with heterogeneous training data across clients. We introduce WAFFLE (Weighted Averaging For Federated LEarning), a personalized collaborative machine learning algorithm based on SCAFFOLD. SCAFFOLD uses stochastic control variates to converge towards a model close to the globally optimal model even in tasks where the distribution of data and labels across clients is highly skewed. In contrast, WAFFLE uses the Euclidean distance between clients' updates to weigh their individual contributions and thus minimize the trained personalized model loss on the specific agent of interest. Through a series of experiments, we compare our proposed new method to two recent personalized federated learning methods, Weight Erosion and APFL, as well as two global learning methods, federated averaging and SCAFFOLD. We evaluate our method using two categories of non-identical client data distributions (concept shift and label skew) on two benchmark image data sets, MNIST and CIFAR10. Our experiments demonstrate the effectiveness of WAFFLE compared with other methods, as it achieves or improves accuracy with faster convergence.
RelaySum for Decentralized Deep Learning on Heterogeneous Data
Oct 08, 2021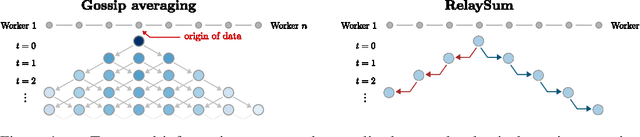
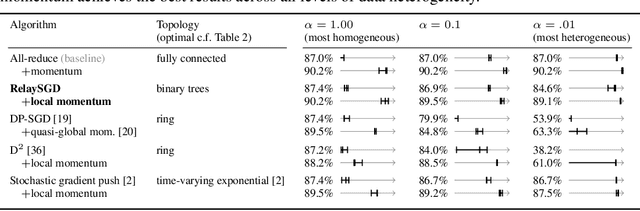
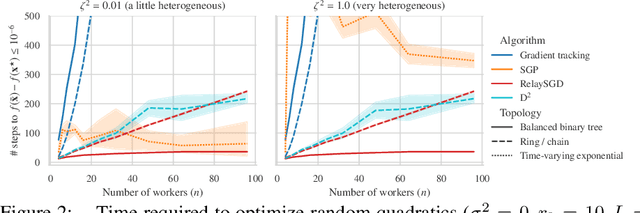

In decentralized machine learning, workers compute model updates on their local data. Because the workers only communicate with few neighbors without central coordination, these updates propagate progressively over the network. This paradigm enables distributed training on networks without all-to-all connectivity, helping to protect data privacy as well as to reduce the communication cost of distributed training in data centers. A key challenge, primarily in decentralized deep learning, remains the handling of differences between the workers' local data distributions. To tackle this challenge, we introduce the RelaySum mechanism for information propagation in decentralized learning. RelaySum uses spanning trees to distribute information exactly uniformly across all workers with finite delays depending on the distance between nodes. In contrast, the typical gossip averaging mechanism only distributes data uniformly asymptotically while using the same communication volume per step as RelaySum. We prove that RelaySGD, based on this mechanism, is independent of data heterogeneity and scales to many workers, enabling highly accurate decentralized deep learning on heterogeneous data. Our code is available at http://github.com/epfml/relaysgd.
On Second-order Optimization Methods for Federated Learning
Sep 06, 2021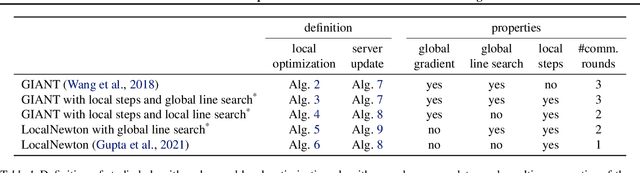
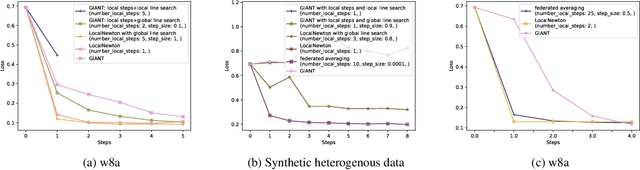
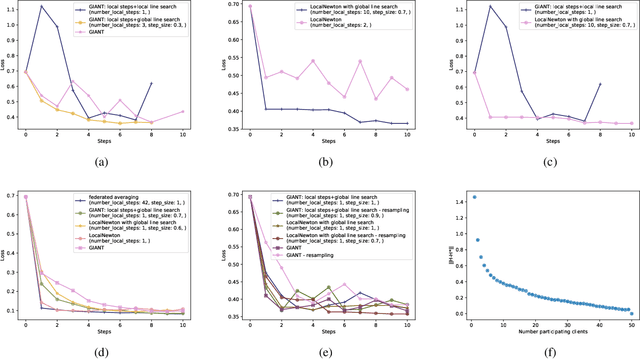
We consider federated learning (FL), where the training data is distributed across a large number of clients. The standard optimization method in this setting is Federated Averaging (FedAvg), which performs multiple local first-order optimization steps between communication rounds. In this work, we evaluate the performance of several second-order distributed methods with local steps in the FL setting which promise to have favorable convergence properties. We (i) show that FedAvg performs surprisingly well against its second-order competitors when evaluated under fair metrics (equal amount of local computations)-in contrast to the results of previous work. Based on our numerical study, we propose (ii) a novel variant that uses second-order local information for updates and a global line search to counteract the resulting local specificity.
Semantic Perturbations with Normalizing Flows for Improved Generalization
Aug 18, 2021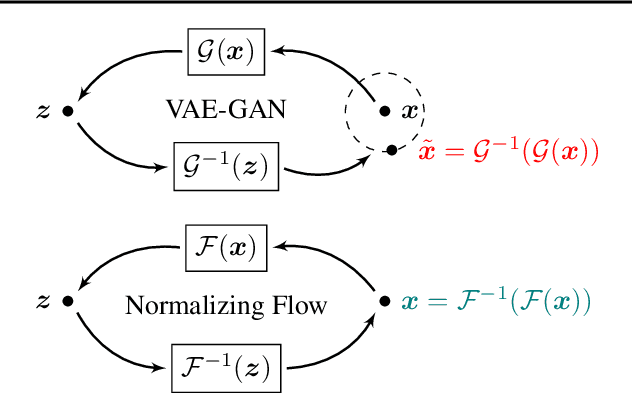
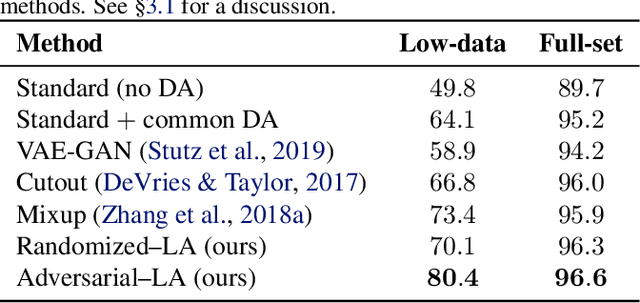

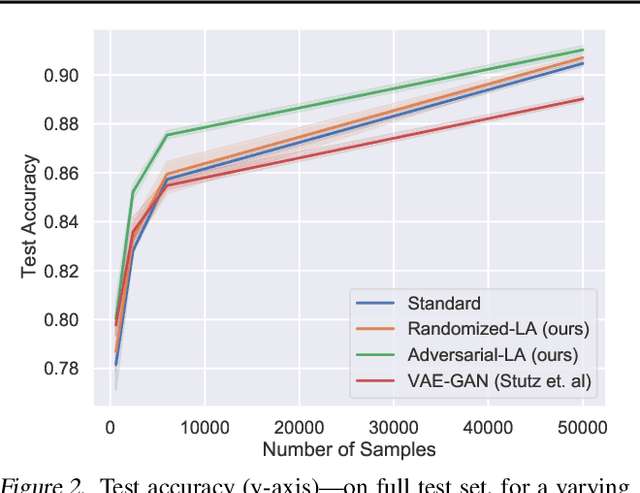
Data augmentation is a widely adopted technique for avoiding overfitting when training deep neural networks. However, this approach requires domain-specific knowledge and is often limited to a fixed set of hard-coded transformations. Recently, several works proposed to use generative models for generating semantically meaningful perturbations to train a classifier. However, because accurate encoding and decoding are critical, these methods, which use architectures that approximate the latent-variable inference, remained limited to pilot studies on small datasets. Exploiting the exactly reversible encoder-decoder structure of normalizing flows, we perform on-manifold perturbations in the latent space to define fully unsupervised data augmentations. We demonstrate that such perturbations match the performance of advanced data augmentation techniques -- reaching 96.6% test accuracy for CIFAR-10 using ResNet-18 and outperform existing methods, particularly in low data regimes -- yielding 10--25% relative improvement of test accuracy from classical training. We find that our latent adversarial perturbations adaptive to the classifier throughout its training are most effective, yielding the first test accuracy improvement results on real-world datasets -- CIFAR-10/100 -- via latent-space perturbations.