 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe geometry of kernelized spectral clustering
Apr 07, 2015
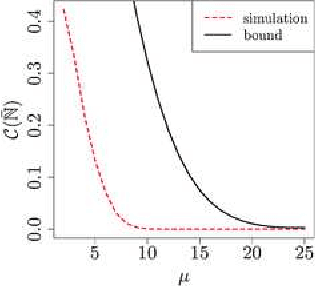
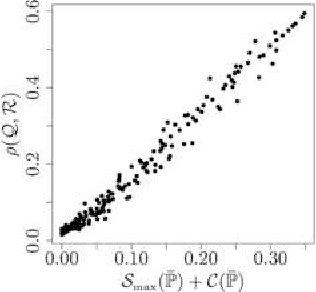
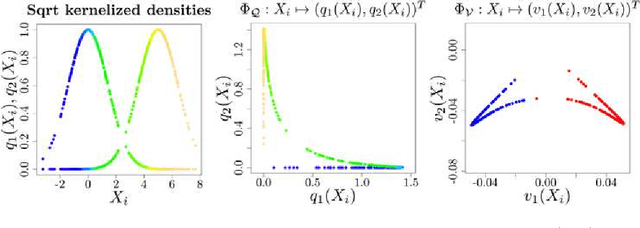
Clustering of data sets is a standard problem in many areas of science and engineering. The method of spectral clustering is based on embedding the data set using a kernel function, and using the top eigenvectors of the normalized Laplacian to recover the connected components. We study the performance of spectral clustering in recovering the latent labels of i.i.d. samples from a finite mixture of nonparametric distributions. The difficulty of this label recovery problem depends on the overlap between mixture components and how easily a mixture component is divided into two nonoverlapping components. When the overlap is small compared to the indivisibility of the mixture components, the principal eigenspace of the population-level normalized Laplacian operator is approximately spanned by the square-root kernelized component densities. In the finite sample setting, and under the same assumption, embedded samples from different components are approximately orthogonal with high probability when the sample size is large. As a corollary we control the fraction of samples mislabeled by spectral clustering under finite mixtures with nonparametric components.
* Published at http://dx.doi.org/10.1214/14-AOS1283 in the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)
Distributed Estimation of Generalized Matrix Rank: Efficient Algorithms and Lower Bounds
Feb 06, 2015
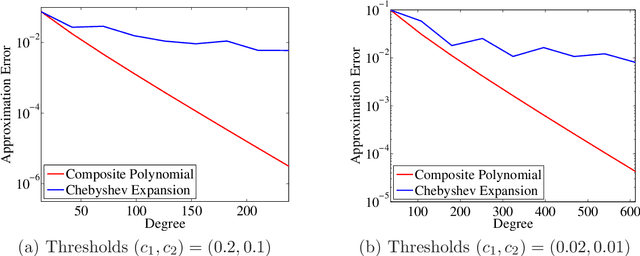
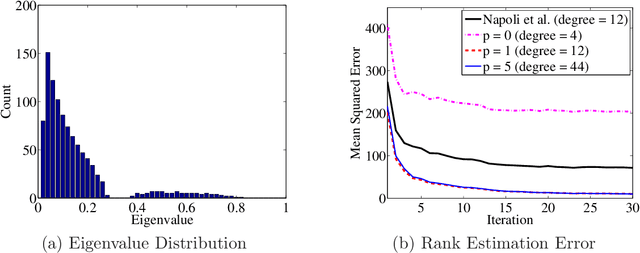
We study the following generalized matrix rank estimation problem: given an $n \times n$ matrix and a constant $c \geq 0$, estimate the number of eigenvalues that are greater than $c$. In the distributed setting, the matrix of interest is the sum of $m$ matrices held by separate machines. We show that any deterministic algorithm solving this problem must communicate $\Omega(n^2)$ bits, which is order-equivalent to transmitting the whole matrix. In contrast, we propose a randomized algorithm that communicates only $\widetilde O(n)$ bits. The upper bound is matched by an $\Omega(n)$ lower bound on the randomized communication complexity. We demonstrate the practical effectiveness of the proposed algorithm with some numerical experiments.
Randomized sketches for kernels: Fast and optimal non-parametric regression
Jan 25, 2015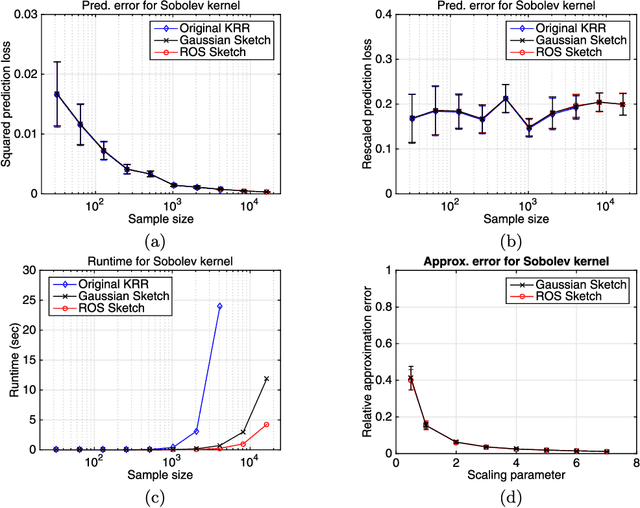
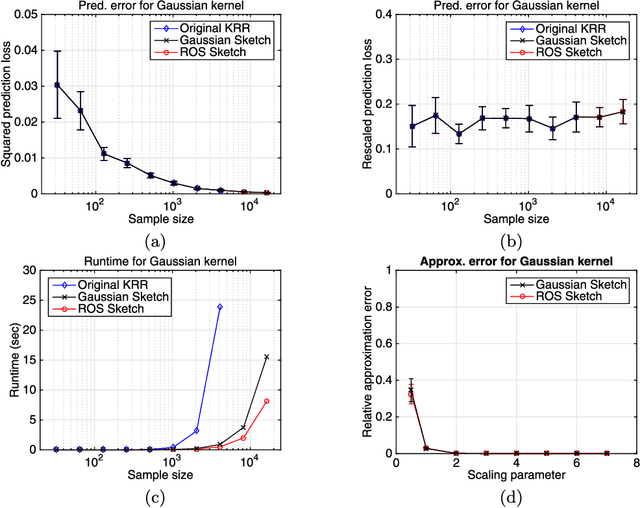
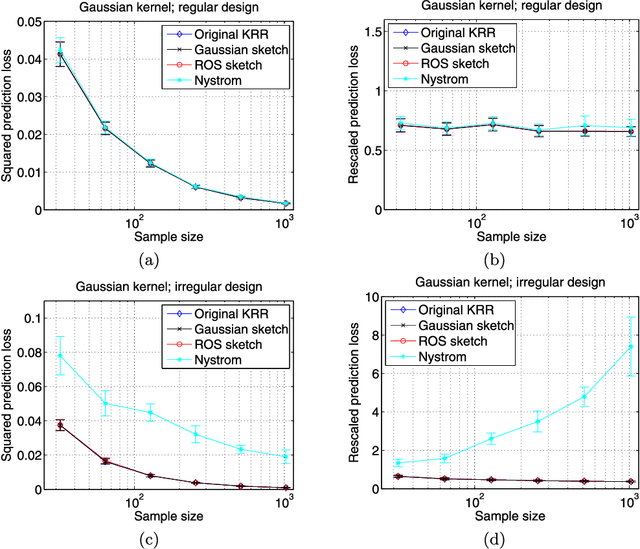
Kernel ridge regression (KRR) is a standard method for performing non-parametric regression over reproducing kernel Hilbert spaces. Given $n$ samples, the time and space complexity of computing the KRR estimate scale as $\mathcal{O}(n^3)$ and $\mathcal{O}(n^2)$ respectively, and so is prohibitive in many cases. We propose approximations of KRR based on $m$-dimensional randomized sketches of the kernel matrix, and study how small the projection dimension $m$ can be chosen while still preserving minimax optimality of the approximate KRR estimate. For various classes of randomized sketches, including those based on Gaussian and randomized Hadamard matrices, we prove that it suffices to choose the sketch dimension $m$ proportional to the statistical dimension (modulo logarithmic factors). Thus, we obtain fast and minimax optimal approximations to the KRR estimate for non-parametric regression.
Regularized M-estimators with nonconvexity: Statistical and algorithmic theory for local optima
Jan 01, 2015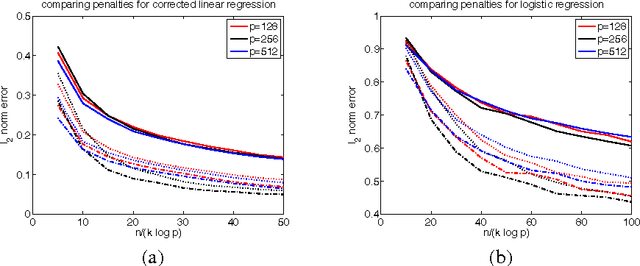
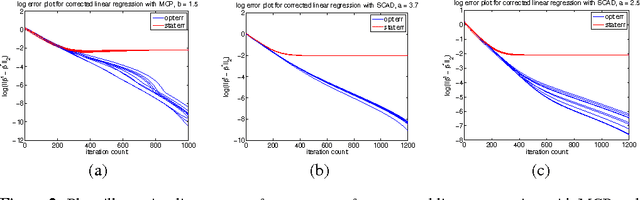
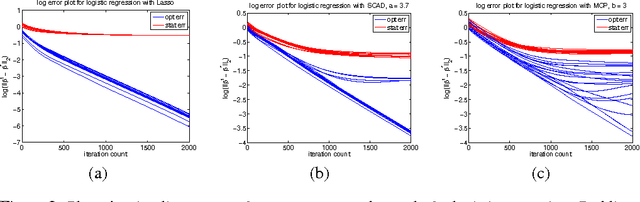
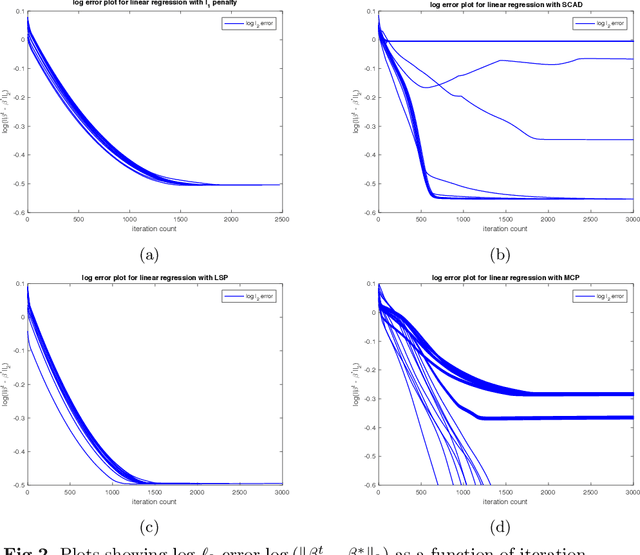
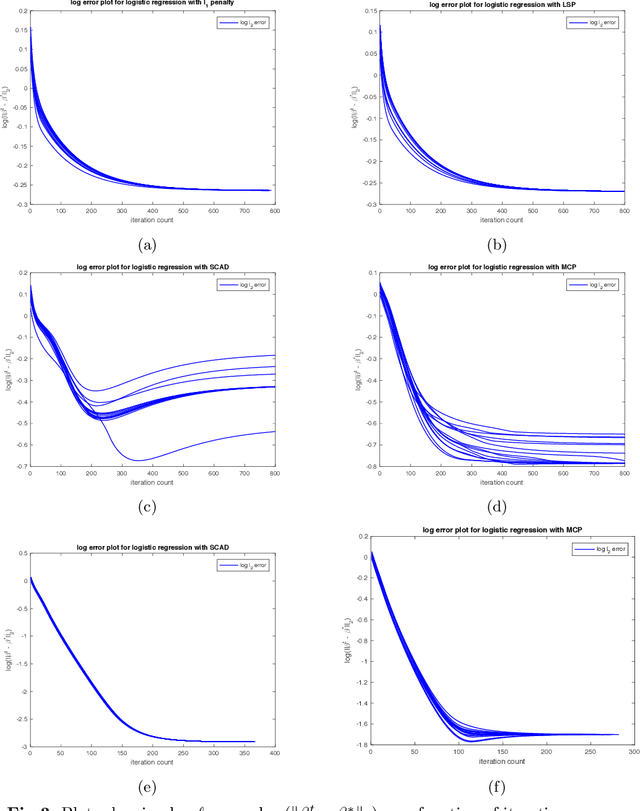
We provide novel theoretical results regarding local optima of regularized $M$-estimators, allowing for nonconvexity in both loss and penalty functions. Under restricted strong convexity on the loss and suitable regularity conditions on the penalty, we prove that \emph{any stationary point} of the composite objective function will lie within statistical precision of the underlying parameter vector. Our theory covers many nonconvex objective functions of interest, including the corrected Lasso for errors-in-variables linear models; regression for generalized linear models with nonconvex penalties such as SCAD, MCP, and capped-$\ell_1$; and high-dimensional graphical model estimation. We quantify statistical accuracy by providing bounds on the $\ell_1$-, $\ell_2$-, and prediction error between stationary points and the population-level optimum. We also propose a simple modification of composite gradient descent that may be used to obtain a near-global optimum within statistical precision $\epsilon$ in $\log(1/\epsilon)$ steps, which is the fastest possible rate of any first-order method. We provide simulation studies illustrating the sharpness of our theoretical results.
Support recovery without incoherence: A case for nonconvex regularization
Dec 17, 2014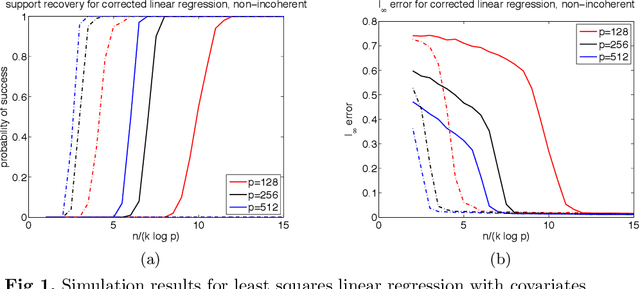
We demonstrate that the primal-dual witness proof method may be used to establish variable selection consistency and $\ell_\infty$-bounds for sparse regression problems, even when the loss function and/or regularizer are nonconvex. Using this method, we derive two theorems concerning support recovery and $\ell_\infty$-guarantees for the regression estimator in a general setting. Our results provide rigorous theoretical justification for the use of nonconvex regularization: For certain nonconvex regularizers with vanishing derivative away from the origin, support recovery consistency may be guaranteed without requiring the typical incoherence conditions present in $\ell_1$-based methods. We then derive several corollaries that illustrate the wide applicability of our method to analyzing composite objective functions involving losses such as least squares, nonconvex modified least squares for errors-in variables linear regression, the negative log likelihood for generalized linear models, and the graphical Lasso. We conclude with empirical studies to corroborate our theoretical predictions.
Iterative Hessian sketch: Fast and accurate solution approximation for constrained least-squares
Nov 03, 2014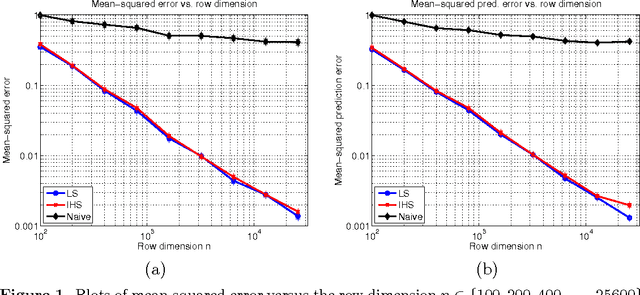
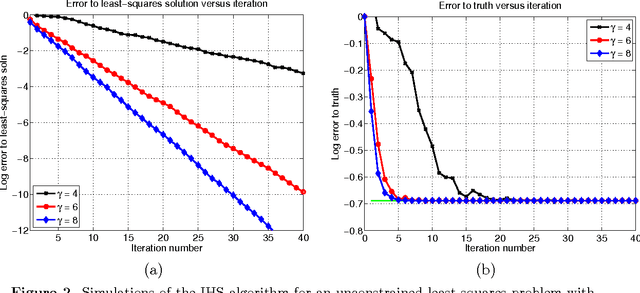
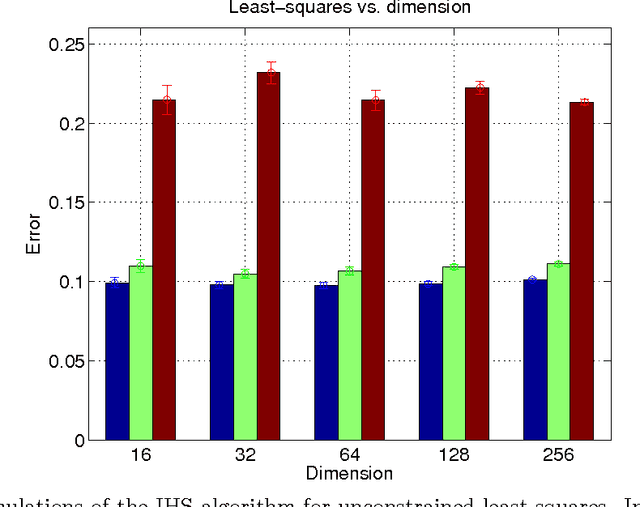
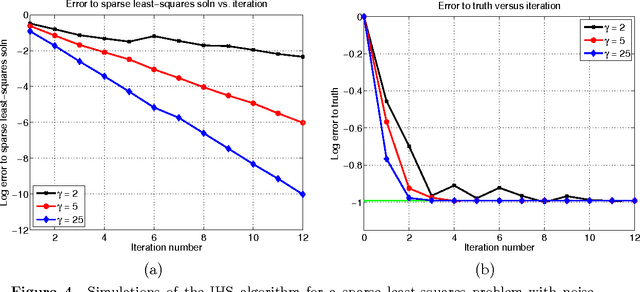
We study randomized sketching methods for approximately solving least-squares problem with a general convex constraint. The quality of a least-squares approximation can be assessed in different ways: either in terms of the value of the quadratic objective function (cost approximation), or in terms of some distance measure between the approximate minimizer and the true minimizer (solution approximation). Focusing on the latter criterion, our first main result provides a general lower bound on any randomized method that sketches both the data matrix and vector in a least-squares problem; as a surprising consequence, the most widely used least-squares sketch is sub-optimal for solution approximation. We then present a new method known as the iterative Hessian sketch, and show that it can be used to obtain approximations to the original least-squares problem using a projection dimension proportional to the statistical complexity of the least-squares minimizer, and a logarithmic number of iterations. We illustrate our general theory with simulations for both unconstrained and constrained versions of least-squares, including $\ell_1$-regularization and nuclear norm constraints. We also numerically demonstrate the practicality of our approach in a real face expression classification experiment.
Optimal rates for zero-order convex optimization: the power of two function evaluations
Aug 20, 2014We consider derivative-free algorithms for stochastic and non-stochastic convex optimization problems that use only function values rather than gradients. Focusing on non-asymptotic bounds on convergence rates, we show that if pairs of function values are available, algorithms for $d$-dimensional optimization that use gradient estimates based on random perturbations suffer a factor of at most $\sqrt{d}$ in convergence rate over traditional stochastic gradient methods. We establish such results for both smooth and non-smooth cases, sharpening previous analyses that suggested a worse dimension dependence, and extend our results to the case of multiple ($m \ge 2$) evaluations. We complement our algorithmic development with information-theoretic lower bounds on the minimax convergence rate of such problems, establishing the sharpness of our achievable results up to constant (sometimes logarithmic) factors.
Statistical guarantees for the EM algorithm: From population to sample-based analysis
Aug 09, 2014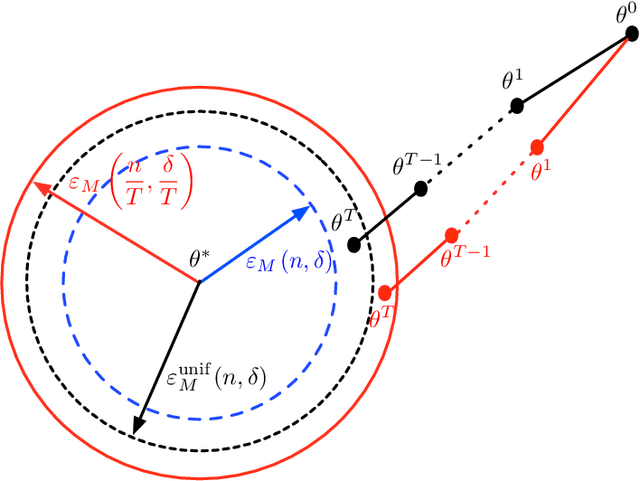
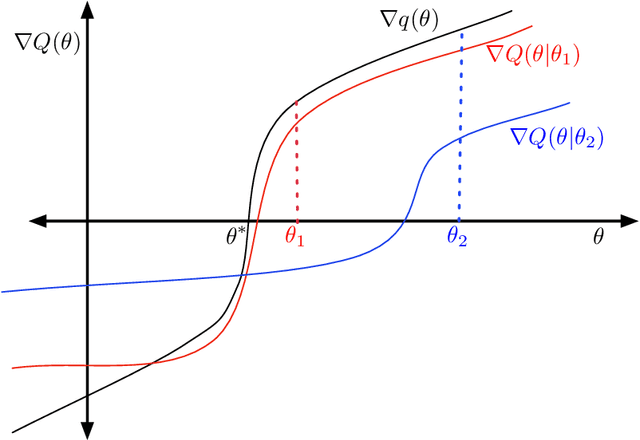
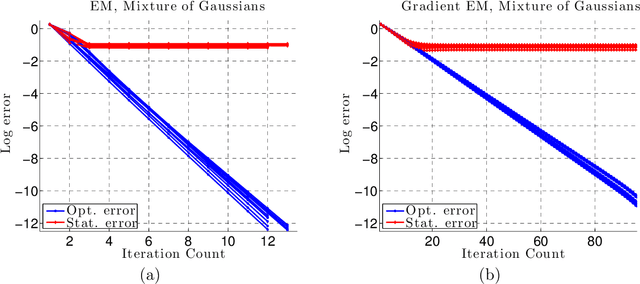
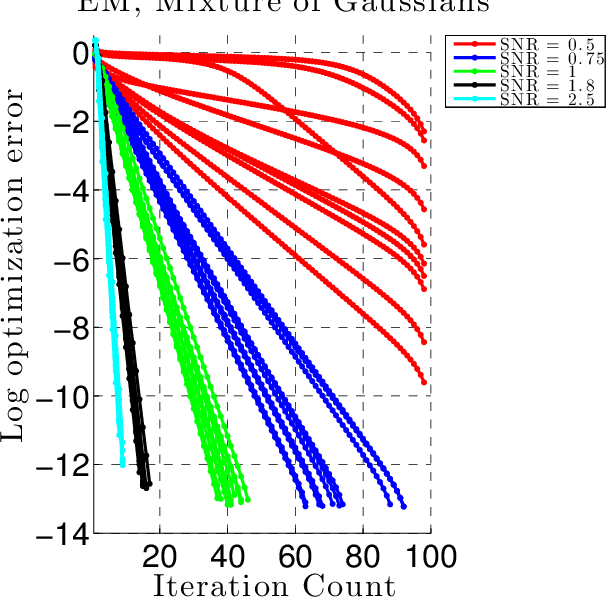
We develop a general framework for proving rigorous guarantees on the performance of the EM algorithm and a variant known as gradient EM. Our analysis is divided into two parts: a treatment of these algorithms at the population level (in the limit of infinite data), followed by results that apply to updates based on a finite set of samples. First, we characterize the domain of attraction of any global maximizer of the population likelihood. This characterization is based on a novel view of the EM updates as a perturbed form of likelihood ascent, or in parallel, of the gradient EM updates as a perturbed form of standard gradient ascent. Leveraging this characterization, we then provide non-asymptotic guarantees on the EM and gradient EM algorithms when applied to a finite set of samples. We develop consequences of our general theory for three canonical examples of incomplete-data problems: mixture of Gaussians, mixture of regressions, and linear regression with covariates missing completely at random. In each case, our theory guarantees that with a suitable initialization, a relatively small number of EM (or gradient EM) steps will yield (with high probability) an estimate that is within statistical error of the MLE. We provide simulations to confirm this theoretically predicted behavior.
Optimality guarantees for distributed statistical estimation
Jun 21, 2014
Large data sets often require performing distributed statistical estimation, with a full data set split across multiple machines and limited communication between machines. To study such scenarios, we define and study some refinements of the classical minimax risk that apply to distributed settings, comparing to the performance of estimators with access to the entire data. Lower bounds on these quantities provide a precise characterization of the minimum amount of communication required to achieve the centralized minimax risk. We study two classes of distributed protocols: one in which machines send messages independently over channels without feedback, and a second allowing for interactive communication, in which a central server broadcasts the messages from a given machine to all other machines. We establish lower bounds for a variety of problems, including location estimation in several families and parameter estimation in different types of regression models. Our results include a novel class of quantitative data-processing inequalities used to characterize the effects of limited communication.
Divide and Conquer Kernel Ridge Regression: A Distributed Algorithm with Minimax Optimal Rates
Apr 29, 2014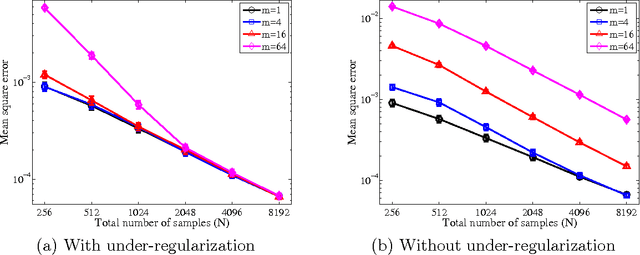
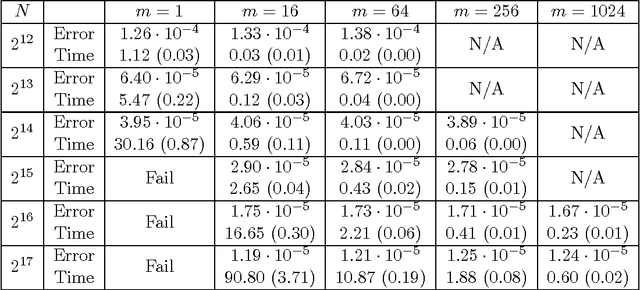
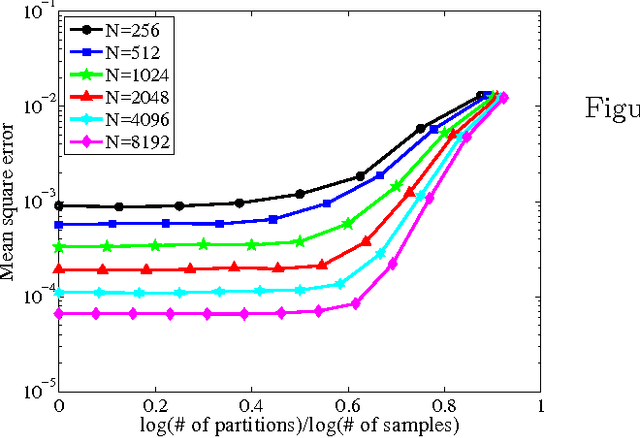

We establish optimal convergence rates for a decomposition-based scalable approach to kernel ridge regression. The method is simple to describe: it randomly partitions a dataset of size N into m subsets of equal size, computes an independent kernel ridge regression estimator for each subset, then averages the local solutions into a global predictor. This partitioning leads to a substantial reduction in computation time versus the standard approach of performing kernel ridge regression on all N samples. Our two main theorems establish that despite the computational speed-up, statistical optimality is retained: as long as m is not too large, the partition-based estimator achieves the statistical minimax rate over all estimators using the set of N samples. As concrete examples, our theory guarantees that the number of processors m may grow nearly linearly for finite-rank kernels and Gaussian kernels and polynomially in N for Sobolev spaces, which in turn allows for substantial reductions in computational cost. We conclude with experiments on both simulated data and a music-prediction task that complement our theoretical results, exhibiting the computational and statistical benefits of our approach.