 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSplit: An algorithmic framework for fast federated optimization
May 11, 2020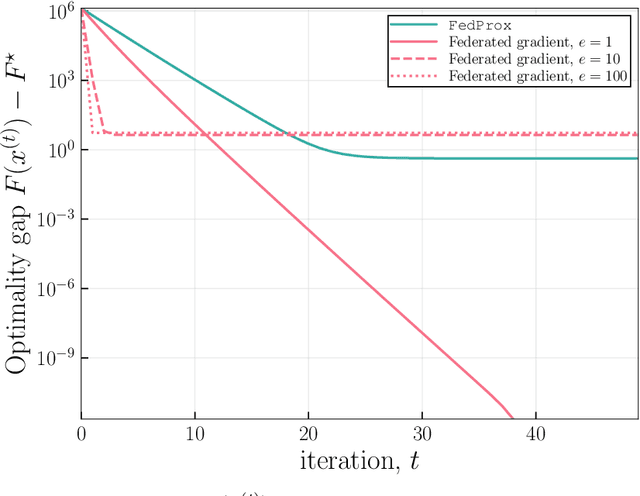
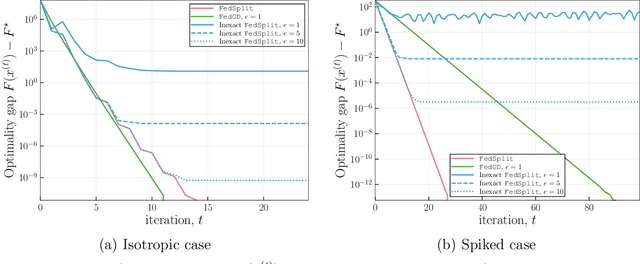
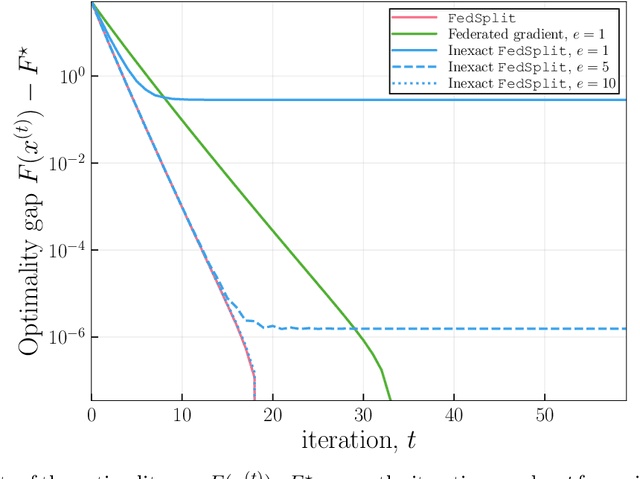
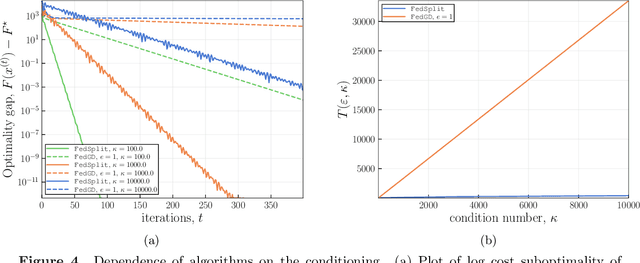
Motivated by federated learning, we consider the hub-and-spoke model of distributed optimization in which a central authority coordinates the computation of a solution among many agents while limiting communication. We first study some past procedures for federated optimization, and show that their fixed points need not correspond to stationary points of the original optimization problem, even in simple convex settings with deterministic updates. In order to remedy these issues, we introduce FedSplit, a class of algorithms based on operator splitting procedures for solving distributed convex minimization with additive structure. We prove that these procedures have the correct fixed points, corresponding to optima of the original optimization problem, and we characterize their convergence rates under different settings. Our theory shows that these methods are provably robust to inexact computation of intermediate local quantities. We complement our theory with some simple experiments that demonstrate the benefits of our methods in practice.
Lower bounds in multiple testing: A framework based on derandomized proxies
May 07, 2020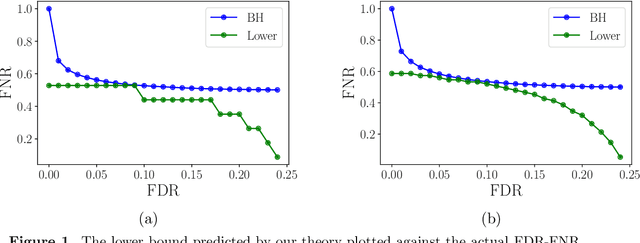
The large bulk of work in multiple testing has focused on specifying procedures that control the false discovery rate (FDR), with relatively less attention being paid to the corresponding Type II error known as the false non-discovery rate (FNR). A line of more recent work in multiple testing has begun to investigate the tradeoffs between the FDR and FNR and to provide lower bounds on the performance of procedures that depend on the model structure. Lacking thus far, however, has been a general approach to obtaining lower bounds for a broad class of models. This paper introduces an analysis strategy based on derandomization, illustrated by applications to various concrete models. Our main result is meta-theorem that gives a general recipe for obtaining lower bounds on the combination of FDR and FNR. We illustrate this meta-theorem by deriving explicit bounds for several models, including instances with dependence, scale-transformed alternatives, and non-Gaussian-like distributions. We provide numerical simulations of some of these lower bounds, and show a close relation to the actual performance of the Benjamini-Hochberg (BH) algorithm.
On Linear Stochastic Approximation: Fine-grained Polyak-Ruppert and Non-Asymptotic Concentration
Apr 09, 2020We undertake a precise study of the asymptotic and non-asymptotic properties of stochastic approximation procedures with Polyak-Ruppert averaging for solving a linear system $\bar{A} \theta = \bar{b}$. When the matrix $\bar{A}$ is Hurwitz, we prove a central limit theorem (CLT) for the averaged iterates with fixed step size and number of iterations going to infinity. The CLT characterizes the exact asymptotic covariance matrix, which is the sum of the classical Polyak-Ruppert covariance and a correction term that scales with the step size. Under assumptions on the tail of the noise distribution, we prove a non-asymptotic concentration inequality whose main term matches the covariance in CLT in any direction, up to universal constants. When the matrix $\bar{A}$ is not Hurwitz but only has non-negative real parts in its eigenvalues, we prove that the averaged LSA procedure actually achieves an $O(1/T)$ rate in mean-squared error. Our results provide a more refined understanding of linear stochastic approximation in both the asymptotic and non-asymptotic settings. We also show various applications of the main results, including the study of momentum-based stochastic gradient methods as well as temporal difference algorithms in reinforcement learning.
Is Temporal Difference Learning Optimal? An Instance-Dependent Analysis
Mar 16, 2020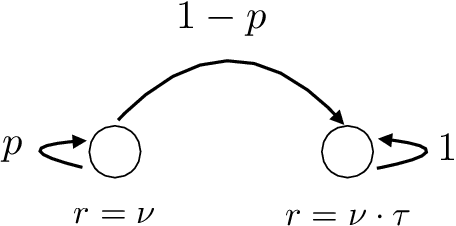
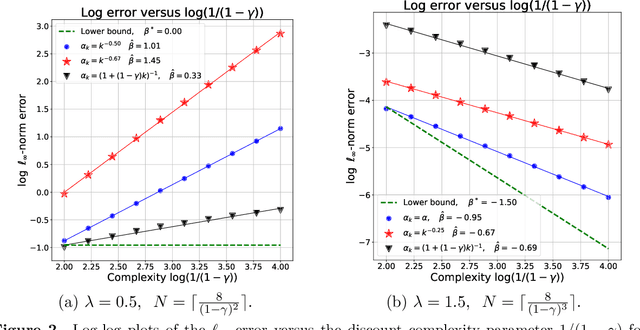
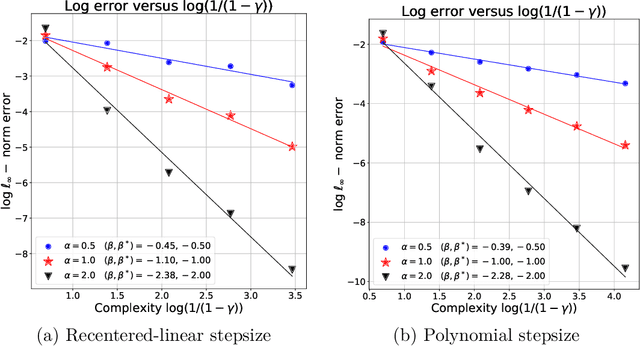
We address the problem of policy evaluation in discounted Markov decision processes, and provide instance-dependent guarantees on the $\ell_\infty$-error under a generative model. We establish both asymptotic and non-asymptotic versions of local minimax lower bounds for policy evaluation, thereby providing an instance-dependent baseline by which to compare algorithms. Theory-inspired simulations show that the widely-used temporal difference (TD) algorithm is strictly suboptimal when evaluated in a non-asymptotic setting, even when combined with Polyak-Ruppert iterate averaging. We remedy this issue by introducing and analyzing variance-reduced forms of stochastic approximation, showing that they achieve non-asymptotic, instance-dependent optimality up to logarithmic factors.
Sampling for Bayesian Mixture Models: MCMC with Polynomial-Time Mixing
Dec 11, 2019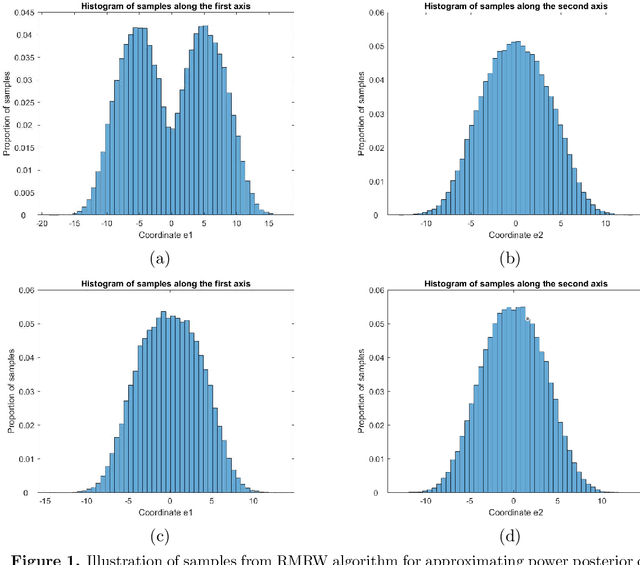
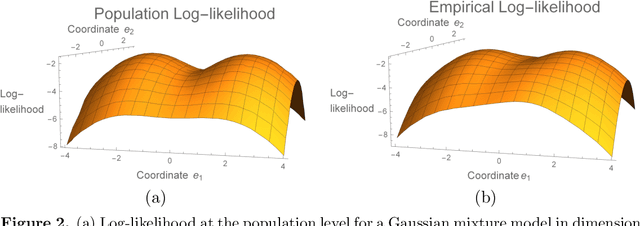
We study the problem of sampling from the power posterior distribution in Bayesian Gaussian mixture models, a robust version of the classical posterior. This power posterior is known to be non-log-concave and multi-modal, which leads to exponential mixing times for some standard MCMC algorithms. We introduce and study the Reflected Metropolis-Hastings Random Walk (RMRW) algorithm for sampling. For symmetric two-component Gaussian mixtures, we prove that its mixing time is bounded as $d^{1.5}(d + \Vert \theta_{0} \Vert^2)^{4.5}$ as long as the sample size $n$ is of the order $d (d + \Vert \theta_{0} \Vert^2)$. Notably, this result requires no conditions on the separation of the two means. En route to proving this bound, we establish some new results of possible independent interest that allow for combining Poincar\'{e} inequalities for conditional and marginal densities.
An Efficient Sampling Algorithm for Non-smooth Composite Potentials
Oct 01, 2019We consider the problem of sampling from a density of the form $p(x) \propto \exp(-f(x)- g(x))$, where $f: \mathbb{R}^d \rightarrow \mathbb{R}$ is a smooth and strongly convex function and $g: \mathbb{R}^d \rightarrow \mathbb{R}$ is a convex and Lipschitz function. We propose a new algorithm based on the Metropolis-Hastings framework, and prove that it mixes to within TV distance $\varepsilon$ of the target density in at most $O(d \log (d/\varepsilon))$ iterations. This guarantee extends previous results on sampling from distributions with smooth log densities ($g = 0$) to the more general composite non-smooth case, with the same mixing time up to a multiple of the condition number. Our method is based on a novel proximal-based proposal distribution that can be efficiently computed for a large class of non-smooth functions $g$.
Value function estimation in Markov reward processes: Instance-dependent $\ell_\infty$-bounds for policy evaluation
Sep 19, 2019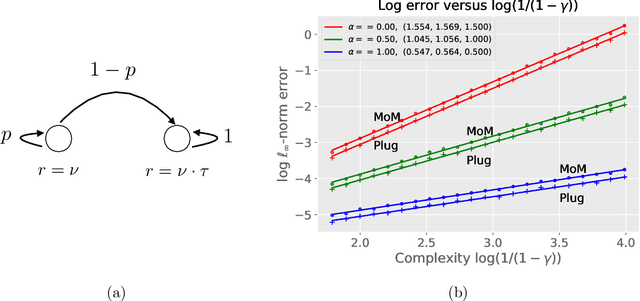
Markov reward processes (MRPs) are used to model stochastic phenomena arising in operations research, control engineering, robotics, artificial intelligence, as well as communication and transportation networks. In many of these cases, such as in the policy evaluation problem encountered in reinforcement learning, the goal is to estimate the long-term value function of such a process without access to the underlying population transition and reward functions. Working with samples generated under the synchronous model, we study the problem of estimating the value function of an infinite-horizon, discounted MRP in the $\ell_\infty$-norm. We analyze both the standard plug-in approach to this problem and a more robust variant, and establish non-asymptotic bounds that depend on the (unknown) problem instance, as well as data-dependent bounds that can be evaluated based on the observed data. We show that these approaches are minimax-optimal up to constant factors over natural sub-classes of MRPs. Our analysis makes use of a leave-one-out decoupling argument tailored to the policy evaluation problem, one which may be of independent interest.
High-Order Langevin Diffusion Yields an Accelerated MCMC Algorithm
Aug 28, 2019We propose a Markov chain Monte Carlo (MCMC) algorithm based on third-order Langevin dynamics for sampling from distributions with log-concave and smooth densities. The higher-order dynamics allow for more flexible discretization schemes, and we develop a specific method that combines splitting with more accurate integration. For a broad class of $d$-dimensional distributions arising from generalized linear models, we prove that the resulting third-order algorithm produces samples from a distribution that is at most $\varepsilon > 0$ in Wasserstein distance from the target distribution in $O\left(\frac{d^{1/3}}{ \varepsilon^{2/3}} \right)$ steps. This result requires only Lipschitz conditions on the gradient. For general strongly convex potentials with $\alpha$-th order smoothness, we prove that the mixing time scales as $O \left(\frac{d^{1/3}}{\varepsilon^{2/3}} + \frac{d^{1/2}}{\varepsilon^{1/(\alpha - 1)}} \right)$.
Improved Bounds for Discretization of Langevin Diffusions: Near-Optimal Rates without Convexity
Jul 25, 2019
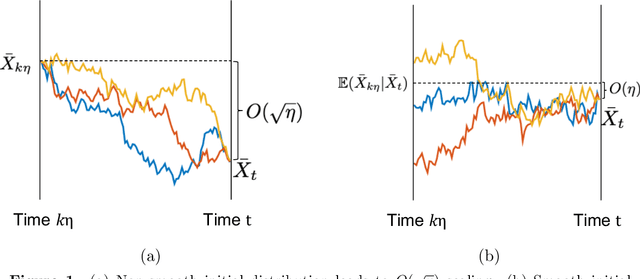
We present an improved analysis of the Euler-Maruyama discretization of the Langevin diffusion. Our analysis does not require global contractivity, and yields polynomial dependence on the time horizon. Compared to existing approaches, we make an additional smoothness assumption, and improve the existing rate from $O(\eta)$ to $O(\eta^2)$ in terms of the KL divergence. This result matches the correct order for numerical SDEs, without suffering from exponential time dependence. When applied to algorithms for sampling and learning, this result simultaneously improves all those methods based on Dalayan's approach.
Variance-reduced $Q$-learning is minimax optimal
Jun 11, 2019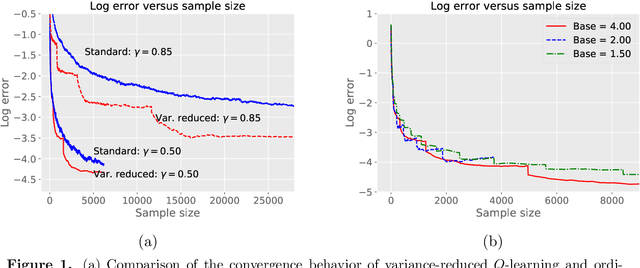
We introduce and analyze a form of variance-reduced $Q$-learning. For $\gamma$-discounted MDPs with finite state space $\mathcal{X}$ and action space $\mathcal{U}$, we prove that it yields an $\epsilon$-accurate estimate of the optimal $Q$-function in the $\ell_\infty$-norm using $\mathcal{O} \left(\left(\frac{D}{ \epsilon^2 (1-\gamma)^3} \right) \; \log \left( \frac{D}{(1-\gamma)} \right) \right)$ samples, where $D = |\mathcal{X}| \times |\mathcal{U}|$. This guarantee matches known minimax lower bounds up to a logarithmic factor in the discount complexity, and is the first form of model-free $Q$-learning proven to achieve the worst-case optimal cubic scaling in the discount complexity parameter $1/(1-\gamma)$ accompanied by optimal linear scaling in the state and action space sizes. By contrast, our past work shows that ordinary $Q$-learning has worst-case quartic scaling in the discount complexity.