 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Sketches of Convex Programs with Sharp Guarantees
Apr 29, 2014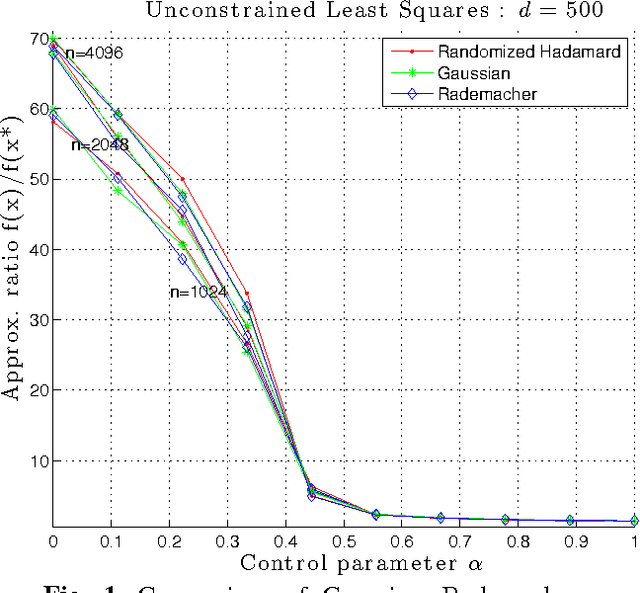
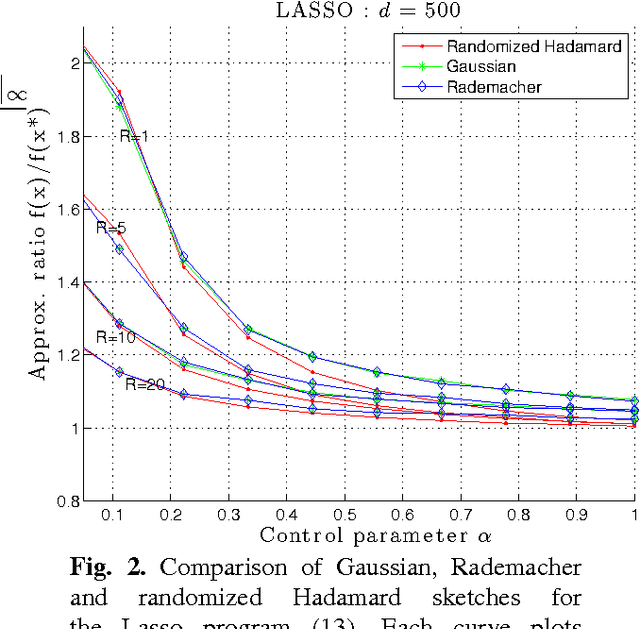
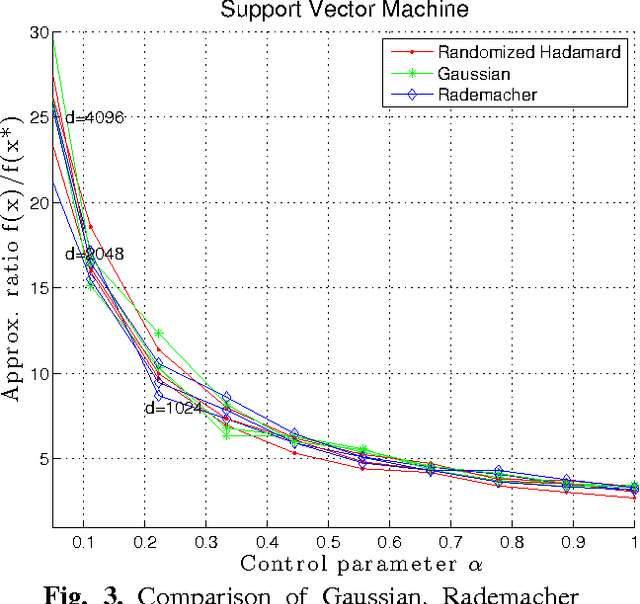
Random projection (RP) is a classical technique for reducing storage and computational costs. We analyze RP-based approximations of convex programs, in which the original optimization problem is approximated by the solution of a lower-dimensional problem. Such dimensionality reduction is essential in computation-limited settings, since the complexity of general convex programming can be quite high (e.g., cubic for quadratic programs, and substantially higher for semidefinite programs). In addition to computational savings, random projection is also useful for reducing memory usage, and has useful properties for privacy-sensitive optimization. We prove that the approximation ratio of this procedure can be bounded in terms of the geometry of constraint set. For a broad class of random projections, including those based on various sub-Gaussian distributions as well as randomized Hadamard and Fourier transforms, the data matrix defining the cost function can be projected down to the statistical dimension of the tangent cone of the constraints at the original solution, which is often substantially smaller than the original dimension. We illustrate consequences of our theory for various cases, including unconstrained and $\ell_1$-constrained least squares, support vector machines, low-rank matrix estimation, and discuss implications on privacy-sensitive optimization and some connections with de-noising and compressed sensing.
Structure estimation for discrete graphical models: Generalized covariance matrices and their inverses
Jan 06, 2014
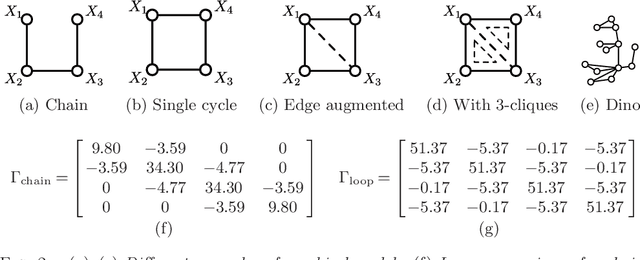
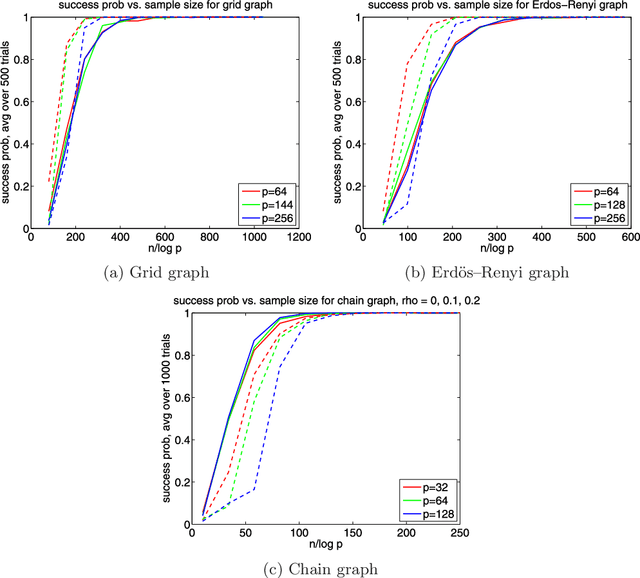
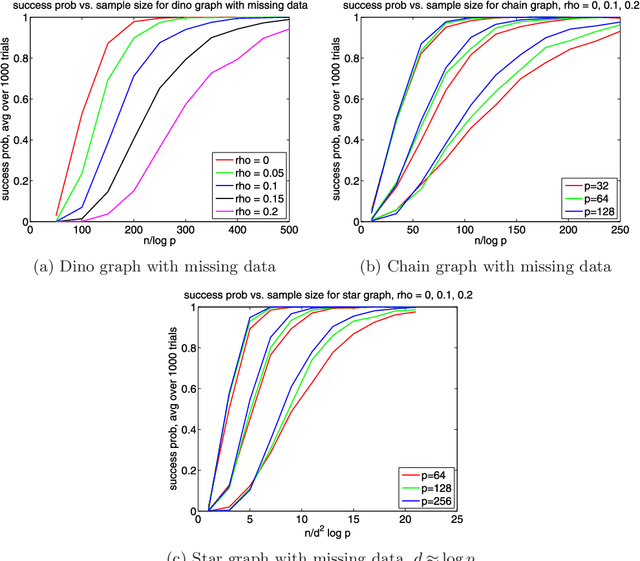
We investigate the relationship between the structure of a discrete graphical model and the support of the inverse of a generalized covariance matrix. We show that for certain graph structures, the support of the inverse covariance matrix of indicator variables on the vertices of a graph reflects the conditional independence structure of the graph. Our work extends results that have previously been established only in the context of multivariate Gaussian graphical models, thereby addressing an open question about the significance of the inverse covariance matrix of a non-Gaussian distribution. The proof exploits a combination of ideas from the geometry of exponential families, junction tree theory and convex analysis. These population-level results have various consequences for graph selection methods, both known and novel, including a novel method for structure estimation for missing or corrupted observations. We provide nonasymptotic guarantees for such methods and illustrate the sharpness of these predictions via simulations.
* Published in at http://dx.doi.org/10.1214/13-AOS1162 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)
Privacy Aware Learning
Oct 10, 2013We study statistical risk minimization problems under a privacy model in which the data is kept confidential even from the learner. In this local privacy framework, we establish sharp upper and lower bounds on the convergence rates of statistical estimation procedures. As a consequence, we exhibit a precise tradeoff between the amount of privacy the data preserves and the utility, as measured by convergence rate, of any statistical estimator or learning procedure.
Early stopping and non-parametric regression: An optimal data-dependent stopping rule
Jun 15, 2013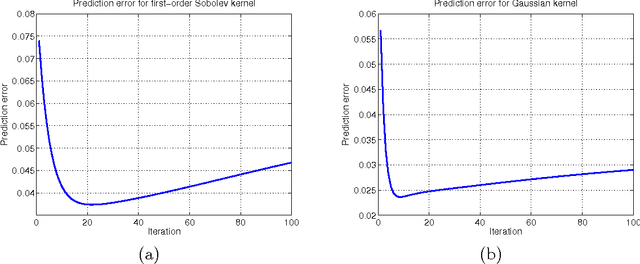
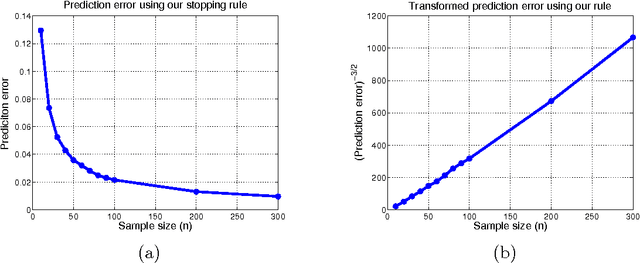
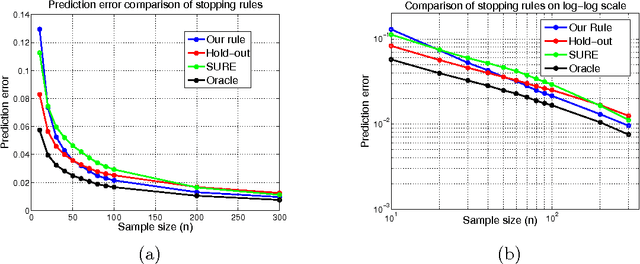
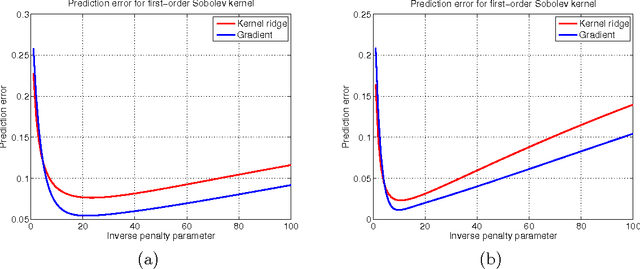
The strategy of early stopping is a regularization technique based on choosing a stopping time for an iterative algorithm. Focusing on non-parametric regression in a reproducing kernel Hilbert space, we analyze the early stopping strategy for a form of gradient-descent applied to the least-squares loss function. We propose a data-dependent stopping rule that does not involve hold-out or cross-validation data, and we prove upper bounds on the squared error of the resulting function estimate, measured in either the $L^2(P)$ and $L^2(P_n)$ norm. These upper bounds lead to minimax-optimal rates for various kernel classes, including Sobolev smoothness classes and other forms of reproducing kernel Hilbert spaces. We show through simulation that our stopping rule compares favorably to two other stopping rules, one based on hold-out data and the other based on Stein's unbiased risk estimate. We also establish a tight connection between our early stopping strategy and the solution path of a kernel ridge regression estimator.
Sampled forms of functional PCA in reproducing kernel Hilbert spaces
Feb 13, 2013
We consider the sampling problem for functional PCA (fPCA), where the simplest example is the case of taking time samples of the underlying functional components. More generally, we model the sampling operation as a continuous linear map from $\mathcal{H}$ to $\mathbb{R}^m$, where the functional components to lie in some Hilbert subspace $\mathcal{H}$ of $L^2$, such as a reproducing kernel Hilbert space of smooth functions. This model includes time and frequency sampling as special cases. In contrast to classical approach in fPCA in which access to entire functions is assumed, having a limited number m of functional samples places limitations on the performance of statistical procedures. We study these effects by analyzing the rate of convergence of an M-estimator for the subspace spanned by the leading components in a multi-spiked covariance model. The estimator takes the form of regularized PCA, and hence is computationally attractive. We analyze the behavior of this estimator within a nonasymptotic framework, and provide bounds that hold with high probability as a function of the number of statistical samples n and the number of functional samples m. We also derive lower bounds showing that the rates obtained are minimax optimal.
* Published in at http://dx.doi.org/10.1214/12-AOS1033 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)
Belief Propagation for Continuous State Spaces: Stochastic Message-Passing with Quantitative Guarantees
Dec 16, 2012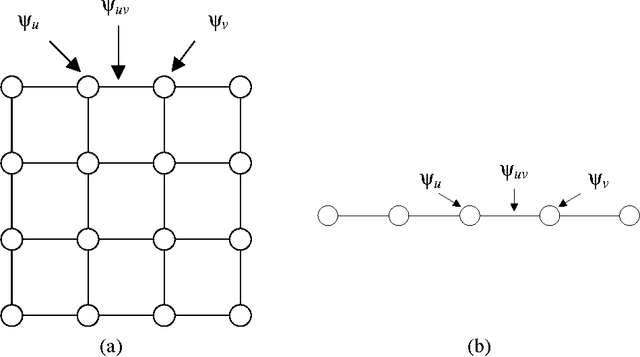
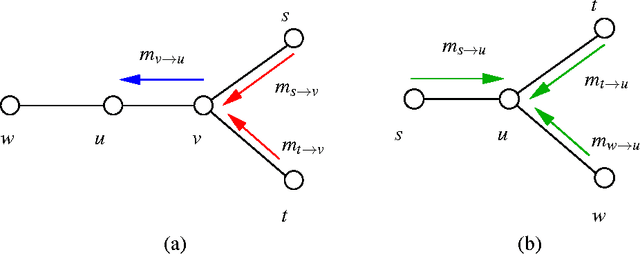

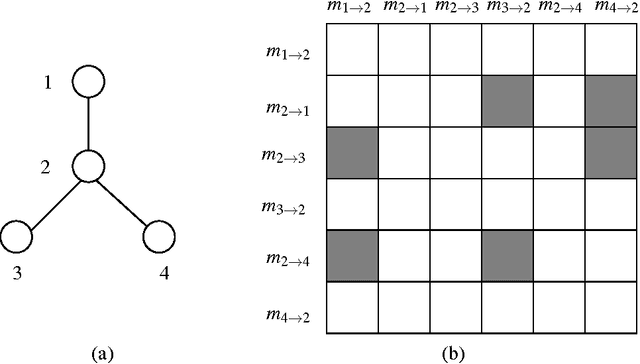
The sum-product or belief propagation (BP) algorithm is a widely used message-passing technique for computing approximate marginals in graphical models. We introduce a new technique, called stochastic orthogonal series message-passing (SOSMP), for computing the BP fixed point in models with continuous random variables. It is based on a deterministic approximation of the messages via orthogonal series expansion, and a stochastic approximation via Monte Carlo estimates of the integral updates of the basis coefficients. We prove that the SOSMP iterates converge to a \delta-neighborhood of the unique BP fixed point for any tree-structured graph, and for any graphs with cycles in which the BP updates satisfy a contractivity condition. In addition, we demonstrate how to choose the number of basis coefficients as a function of the desired approximation accuracy \delta and smoothness of the compatibility functions. We illustrate our theory with both simulated examples and in application to optical flow estimation.
Discussion: Latent variable graphical model selection via convex optimization
Nov 05, 2012Discussion of "Latent variable graphical model selection via convex optimization" by Venkat Chandrasekaran, Pablo A. Parrilo and Alan S. Willsky [arXiv:1008.1290].
* Published in at http://dx.doi.org/10.1214/12-AOS981 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)
High-dimensional regression with noisy and missing data: Provable guarantees with nonconvexity
Sep 25, 2012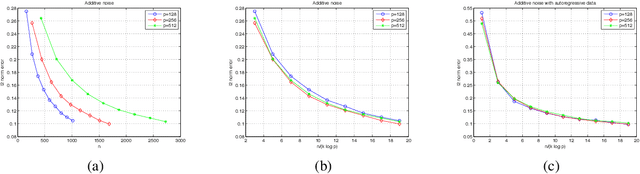
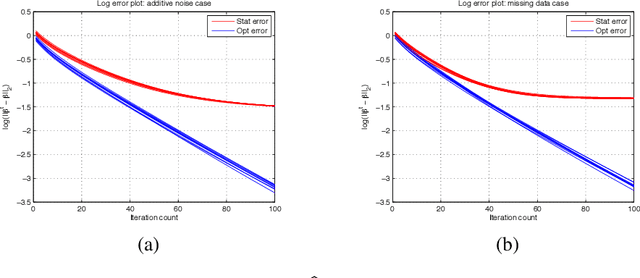
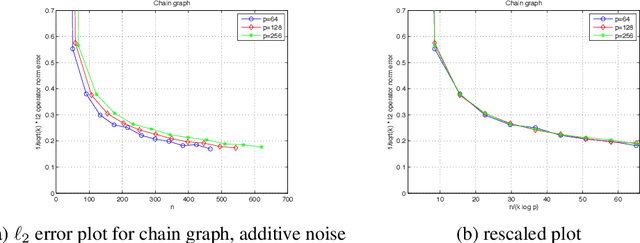
Although the standard formulations of prediction problems involve fully-observed and noiseless data drawn in an i.i.d. manner, many applications involve noisy and/or missing data, possibly involving dependence, as well. We study these issues in the context of high-dimensional sparse linear regression, and propose novel estimators for the cases of noisy, missing and/or dependent data. Many standard approaches to noisy or missing data, such as those using the EM algorithm, lead to optimization problems that are inherently nonconvex, and it is difficult to establish theoretical guarantees on practical algorithms. While our approach also involves optimizing nonconvex programs, we are able to both analyze the statistical error associated with any global optimum, and more surprisingly, to prove that a simple algorithm based on projected gradient descent will converge in polynomial time to a small neighborhood of the set of all global minimizers. On the statistical side, we provide nonasymptotic bounds that hold with high probability for the cases of noisy, missing and/or dependent data. On the computational side, we prove that under the same types of conditions required for statistical consistency, the projected gradient descent algorithm is guaranteed to converge at a geometric rate to a near-global minimizer. We illustrate these theoretical predictions with simulations, showing close agreement with the predicted scalings.
* Published in at http://dx.doi.org/10.1214/12-AOS1018 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)
Fast global convergence of gradient methods for high-dimensional statistical recovery
Jul 25, 2012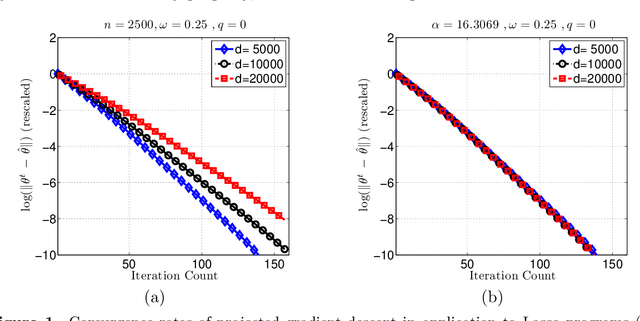
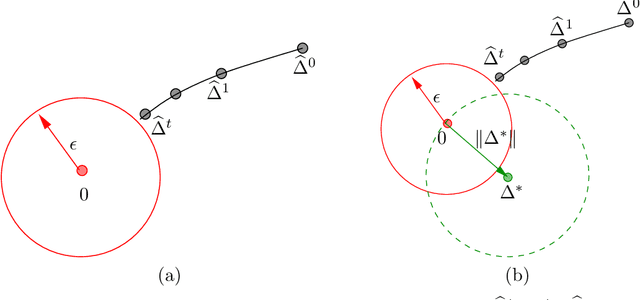
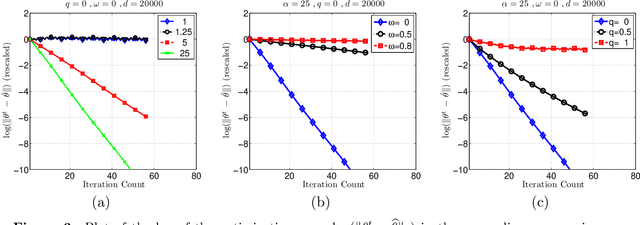
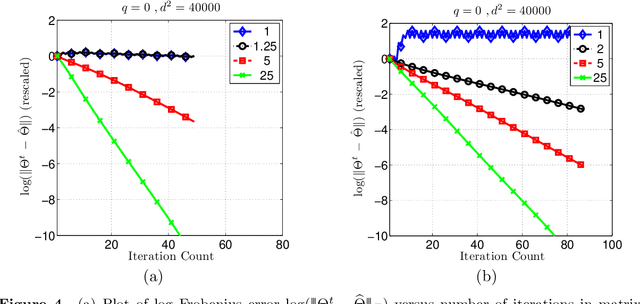
Many statistical $M$-estimators are based on convex optimization problems formed by the combination of a data-dependent loss function with a norm-based regularizer. We analyze the convergence rates of projected gradient and composite gradient methods for solving such problems, working within a high-dimensional framework that allows the data dimension $\pdim$ to grow with (and possibly exceed) the sample size $\numobs$. This high-dimensional structure precludes the usual global assumptions---namely, strong convexity and smoothness conditions---that underlie much of classical optimization analysis. We define appropriately restricted versions of these conditions, and show that they are satisfied with high probability for various statistical models. Under these conditions, our theory guarantees that projected gradient descent has a globally geometric rate of convergence up to the \emph{statistical precision} of the model, meaning the typical distance between the true unknown parameter $\theta^*$ and an optimal solution $\hat{\theta}$. This result is substantially sharper than previous convergence results, which yielded sublinear convergence, or linear convergence only up to the noise level. Our analysis applies to a wide range of $M$-estimators and statistical models, including sparse linear regression using Lasso ($\ell_1$-regularized regression); group Lasso for block sparsity; log-linear models with regularization; low-rank matrix recovery using nuclear norm regularization; and matrix decomposition. Overall, our analysis reveals interesting connections between statistical precision and computational efficiency in high-dimensional estimation.
Stochastic optimization and sparse statistical recovery: An optimal algorithm for high dimensions
Jul 18, 2012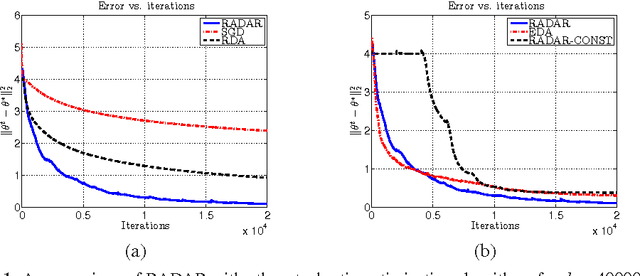
We develop and analyze stochastic optimization algorithms for problems in which the expected loss is strongly convex, and the optimum is (approximately) sparse. Previous approaches are able to exploit only one of these two structures, yielding an $\order(\pdim/T)$ convergence rate for strongly convex objectives in $\pdim$ dimensions, and an $\order(\sqrt{(\spindex \log \pdim)/T})$ convergence rate when the optimum is $\spindex$-sparse. Our algorithm is based on successively solving a series of $\ell_1$-regularized optimization problems using Nesterov's dual averaging algorithm. We establish that the error of our solution after $T$ iterations is at most $\order((\spindex \log\pdim)/T)$, with natural extensions to approximate sparsity. Our results apply to locally Lipschitz losses including the logistic, exponential, hinge and least-squares losses. By recourse to statistical minimax results, we show that our convergence rates are optimal up to multiplicative constant factors. The effectiveness of our approach is also confirmed in numerical simulations, in which we compare to several baselines on a least-squares regression problem.