 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing Information Gain in Partially Observable Environments via Prediction Reward
May 11, 2020
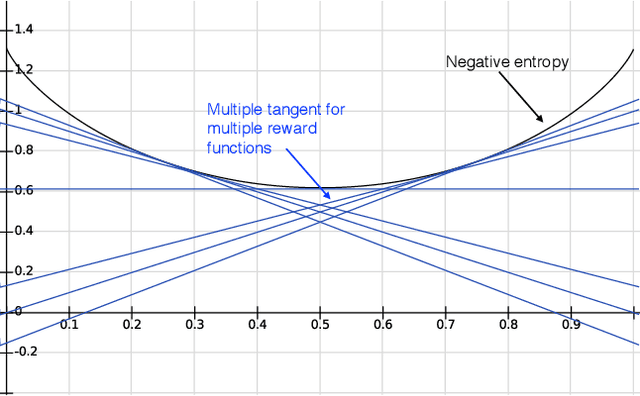
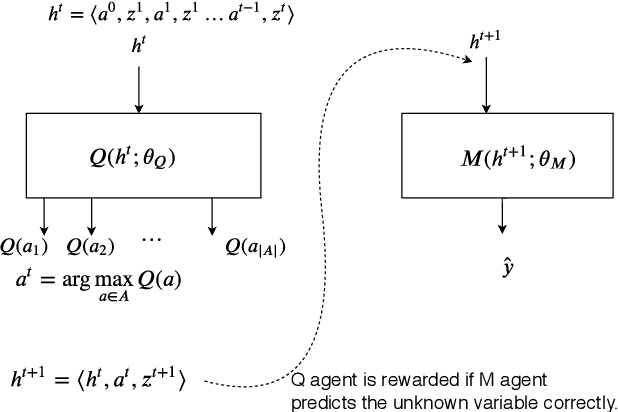
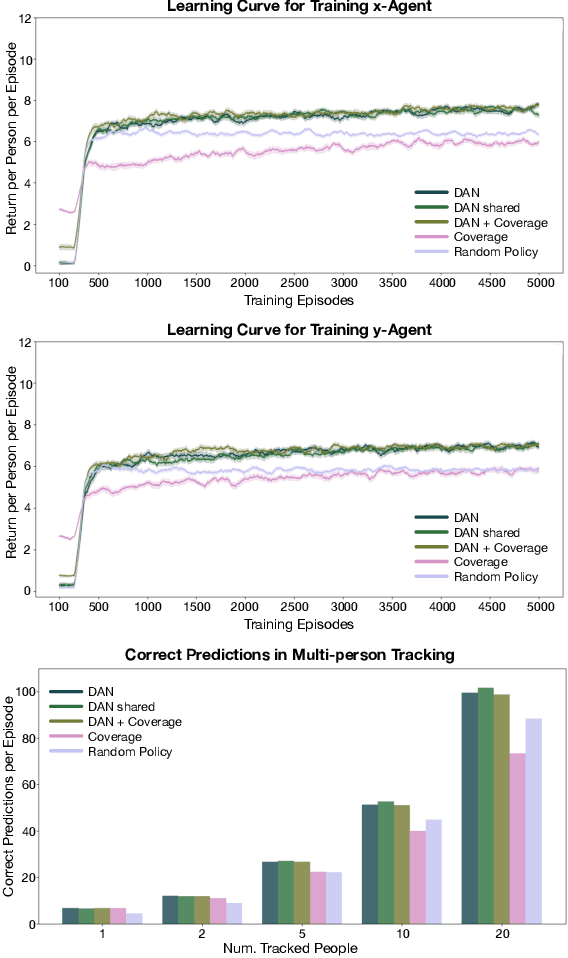
Information gathering in a partially observable environment can be formulated as a reinforcement learning (RL), problem where the reward depends on the agent's uncertainty. For example, the reward can be the negative entropy of the agent's belief over an unknown (or hidden) variable. Typically, the rewards of an RL agent are defined as a function of the state-action pairs and not as a function of the belief of the agent; this hinders the direct application of deep RL methods for such tasks. This paper tackles the challenge of using belief-based rewards for a deep RL agent, by offering a simple insight that maximizing any convex function of the belief of the agent can be approximated by instead maximizing a prediction reward: a reward based on prediction accuracy. In particular, we derive the exact error between negative entropy and the expected prediction reward. This insight provides theoretical motivation for several fields using prediction rewards---namely visual attention, question answering systems, and intrinsic motivation---and highlights their connection to the usually distinct fields of active perception, active sensing, and sensor placement. Based on this insight we present deep anticipatory networks (DANs), which enables an agent to take actions to reduce its uncertainty without performing explicit belief inference. We present two applications of DANs: building a sensor selection system for tracking people in a shopping mall and learning discrete models of attention on fashion MNIST and MNIST digit classification.
Maxmin Q-learning: Controlling the Estimation Bias of Q-learning
Feb 16, 2020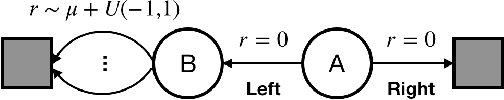
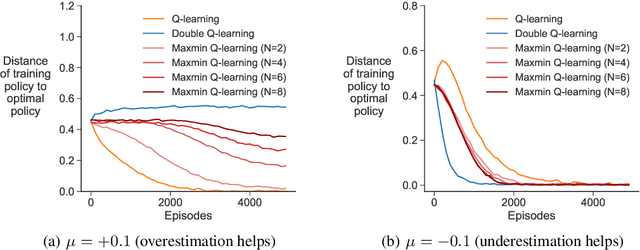
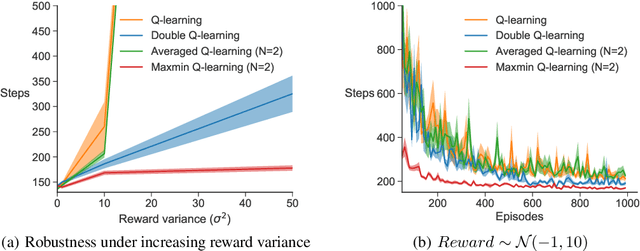
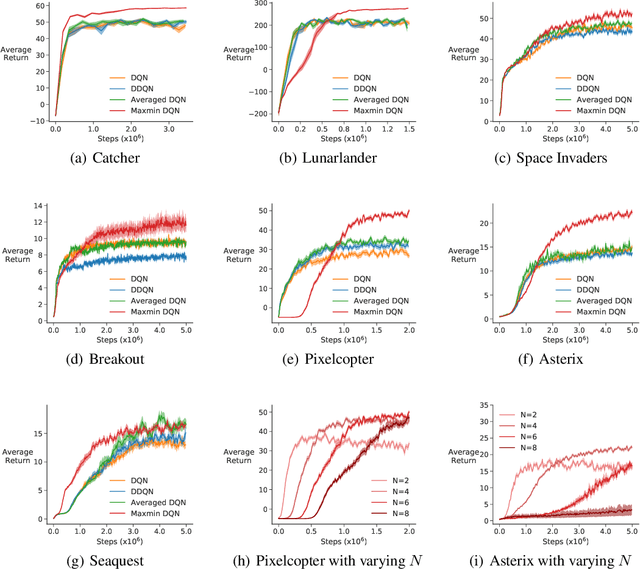
Q-learning suffers from overestimation bias, because it approximates the maximum action value using the maximum estimated action value. Algorithms have been proposed to reduce overestimation bias, but we lack an understanding of how bias interacts with performance, and the extent to which existing algorithms mitigate bias. In this paper, we 1) highlight that the effect of overestimation bias on learning efficiency is environment-dependent; 2) propose a generalization of Q-learning, called \emph{Maxmin Q-learning}, which provides a parameter to flexibly control bias; 3) show theoretically that there exists a parameter choice for Maxmin Q-learning that leads to unbiased estimation with a lower approximation variance than Q-learning; and 4) prove the convergence of our algorithm in the tabular case, as well as convergence of several previous Q-learning variants, using a novel Generalized Q-learning framework. We empirically verify that our algorithm better controls estimation bias in toy environments, and that it achieves superior performance on several benchmark problems.
An implicit function learning approach for parametric modal regression
Feb 14, 2020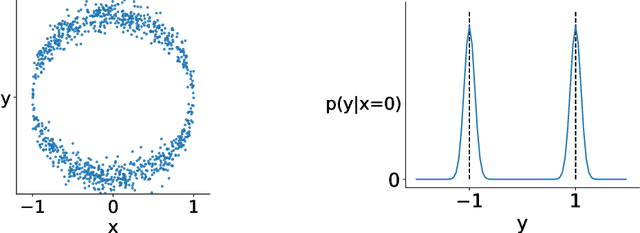
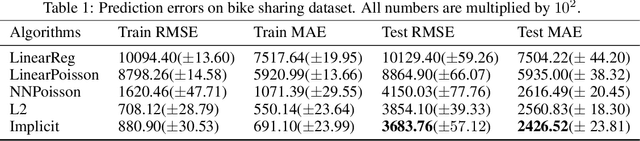
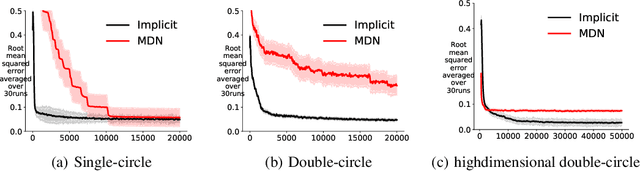

For multi-valued functions---such as when the conditional distribution on targets given the inputs is multi-modal---standard regression approaches are not always desirable because they provide the conditional mean. Modal regression aims to instead find the conditional mode, but is restricted to nonparametric approaches. Such methods can be difficult to scale, and cannot benefit from parametric function approximation, like neural networks, which can learn complex relationships between inputs and targets. In this work, we propose a parametric modal regression algorithm, by using the implicit function theorem to develop an objective for learning a joint parameterized function over inputs and targets. We empirically demonstrate on several synthetic problems that our method (i) can learn multi-valued functions and produce the conditional modes, (ii) scales well to high-dimensional inputs and (iii) is even more effective for certain uni-modal problems, particularly for high frequency data where the joint function over inputs and targets can better capture the complex relationship between them. We then demonstrate that our method is practically useful in a real-world modal regression problem. We conclude by showing that our method provides small improvements on two regression datasets that have asymmetric distributions over the targets.
Is Fast Adaptation All You Need?
Oct 03, 2019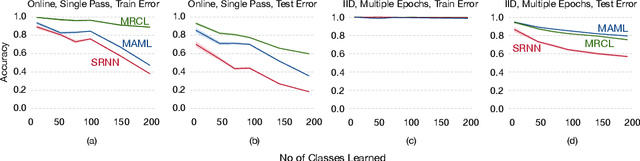

Gradient-based meta-learning has proven to be highly effective at learning model initializations, representations, and update rules that allow fast adaptation from a few samples. The core idea behind these approaches is to use fast adaptation and generalization -- two second-order metrics -- as training signals on a meta-training dataset. However, little attention has been given to other possible second-order metrics. In this paper, we investigate a different training signal -- robustness to catastrophic interference -- and demonstrate that representations learned by directing minimizing interference are more conducive to incremental learning than those learned by just maximizing fast adaptation.
Meta-descent for Online, Continual Prediction
Jul 17, 2019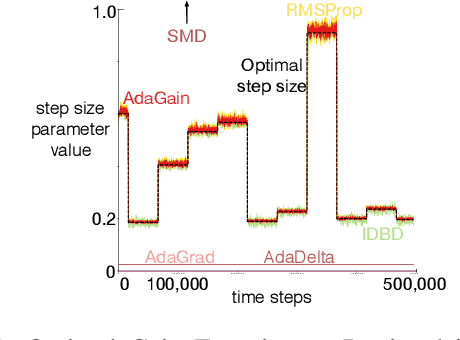
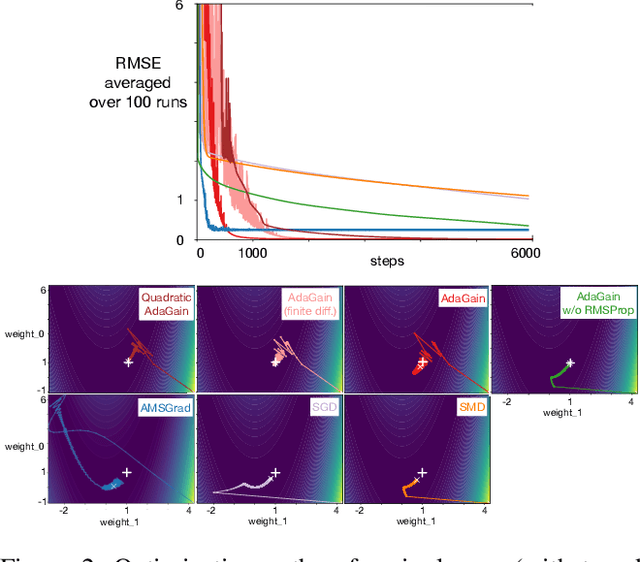
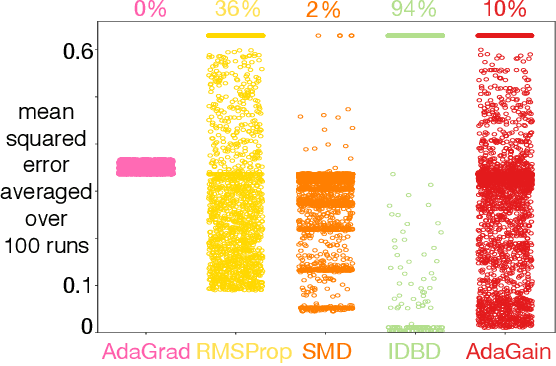
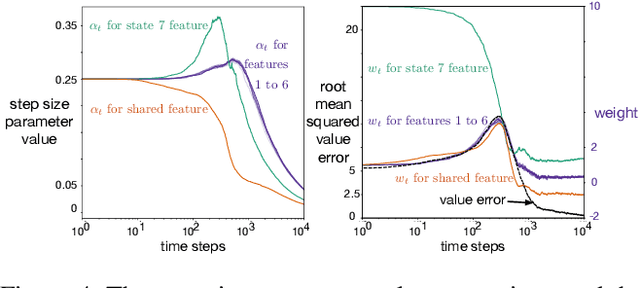
This paper investigates different vector step-size adaptation approaches for non-stationary online, continual prediction problems. Vanilla stochastic gradient descent can be considerably improved by scaling the update with a vector of appropriately chosen step-sizes. Many methods, including AdaGrad, RMSProp, and AMSGrad, keep statistics about the learning process to approximate a second order update---a vector approximation of the inverse Hessian. Another family of approaches use meta-gradient descent to adapt the step-size parameters to minimize prediction error. These meta-descent strategies are promising for non-stationary problems, but have not been as extensively explored as quasi-second order methods. We first derive a general, incremental meta-descent algorithm, called AdaGain, designed to be applicable to a much broader range of algorithms, including those with semi-gradient updates or even those with accelerations, such as RMSProp. We provide an empirical comparison of methods from both families. We conclude that methods from both families can perform well, but in non-stationary prediction problems the meta-descent methods exhibit advantages. Our method is particularly robust across several prediction problems, and is competitive with the state-of-the-art method on a large-scale, time-series prediction problem on real data from a mobile robot.
Hill Climbing on Value Estimates for Search-control in Dyna
Jul 04, 2019
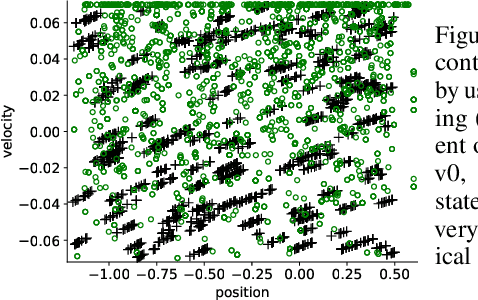
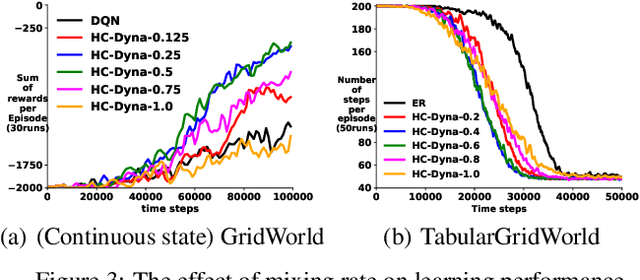
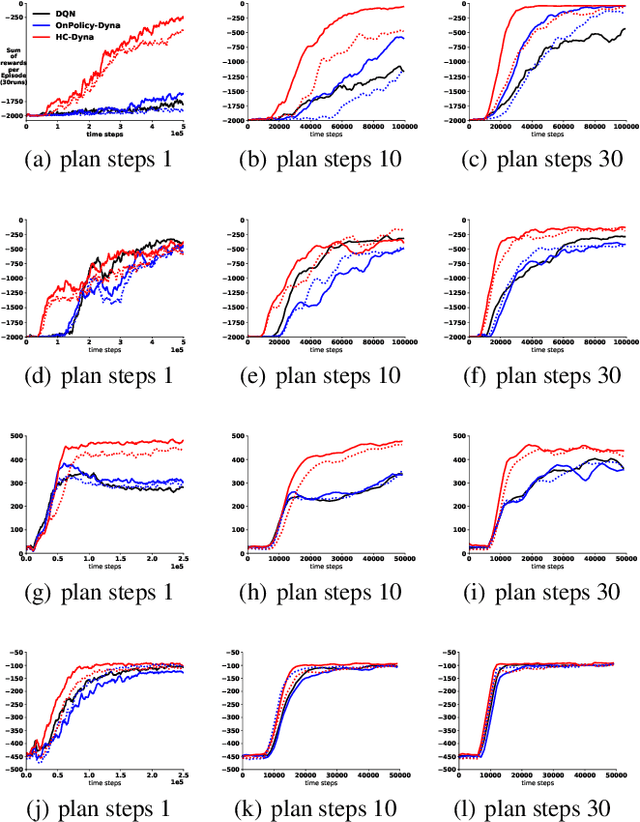
Dyna is an architecture for model-based reinforcement learning (RL), where simulated experience from a model is used to update policies or value functions. A key component of Dyna is search-control, the mechanism to generate the state and action from which the agent queries the model, which remains largely unexplored. In this work, we propose to generate such states by using the trajectory obtained from Hill Climbing (HC) the current estimate of the value function. This has the effect of propagating value from high-value regions and of preemptively updating value estimates of the regions that the agent is likely to visit next. We derive a noisy projected natural gradient algorithm for hill climbing, and highlight a connection to Langevin dynamics. We provide an empirical demonstration on four classical domains that our algorithm, HC-Dyna, can obtain significant sample efficiency improvements. We study the properties of different sampling distributions for search-control, and find that there appears to be a benefit specifically from using the samples generated by climbing on current value estimates from low-value to high-value region.
Adapting Behaviour via Intrinsic Reward: A Survey and Empirical Study
Jun 19, 2019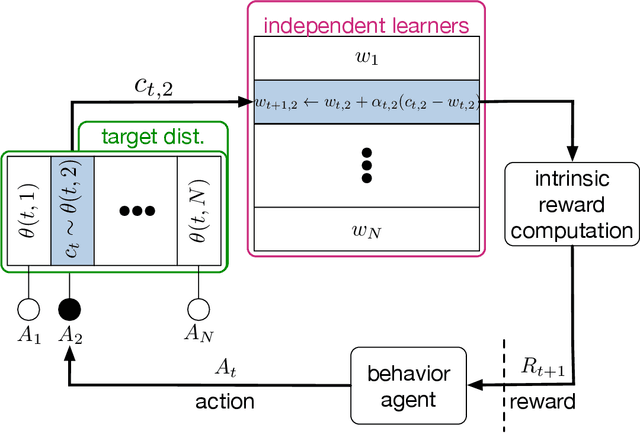


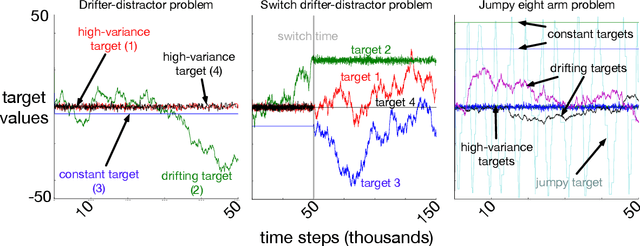
Learning about many things can provide numerous benefits to a reinforcement learning system. For example, learning many auxiliary value functions, in addition to optimizing the environmental reward, appears to improve both exploration and representation learning. The question we tackle in this paper is how to sculpt the stream of experience---how to adapt the system's behaviour---to optimize the learning of a collection of value functions. A simple answer is to compute an intrinsic reward based on the statistics of each auxiliary learner, and use reinforcement learning to maximize that intrinsic reward. Unfortunately, implementing this simple idea has proven difficult, and thus has been the focus of decades of study. It remains unclear which of the many possible measures of learning would work well in a parallel learning setting where environmental reward is extremely sparse or absent. In this paper, we investigate and compare different intrinsic reward mechanisms in a new bandit-like parallel-learning testbed. We discuss the interaction between reward and prediction learners and highlight the importance of introspective prediction learners: those that increase their rate of learning when progress is possible, and decrease when it is not. We provide a comprehensive empirical comparison of 15 different rewards, including well-known ideas from reinforcement learning and active learning. Our results highlight a simple but seemingly powerful principle: intrinsic rewards based on the amount of learning can generate useful behaviour, if each individual learner is introspective.
Importance Resampling for Off-policy Prediction
Jun 11, 2019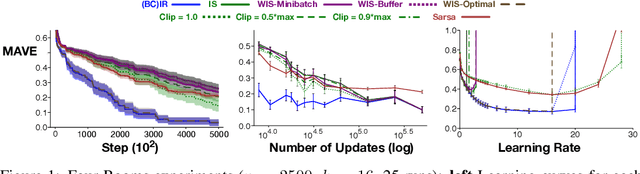
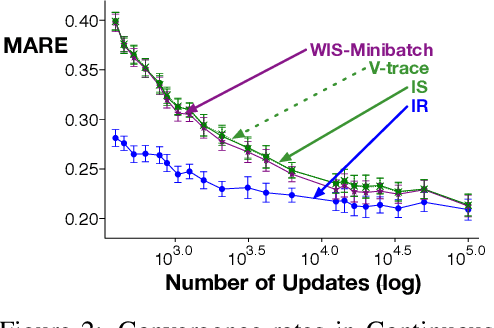
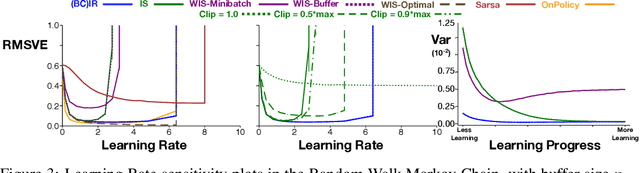
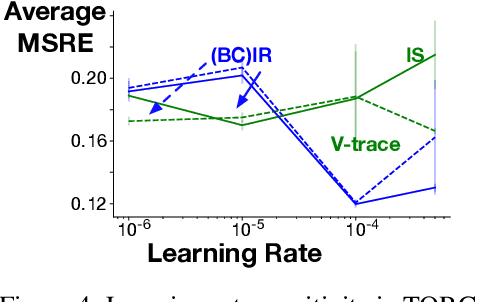
Importance sampling (IS) is a common reweighting strategy for off-policy prediction in reinforcement learning. While it is consistent and unbiased, it can result in high variance updates to the weights for the value function. In this work, we explore a resampling strategy as an alternative to reweighting. We propose Importance Resampling (IR) for off-policy prediction, which resamples experience from a replay buffer and applies standard on-policy updates. The approach avoids using importance sampling ratios in the update, instead correcting the distribution before the update. We characterize the bias and consistency of IR, particularly compared to Weighted IS (WIS). We demonstrate in several microworlds that IR has improved sample efficiency and lower variance updates, as compared to IS and several variance-reduced IS strategies, including variants of WIS and V-trace which clips IS ratios. We also provide a demonstration showing IR improves over IS for learning a value function from images in a racing car simulator.
Meta-Learning Representations for Continual Learning
May 29, 2019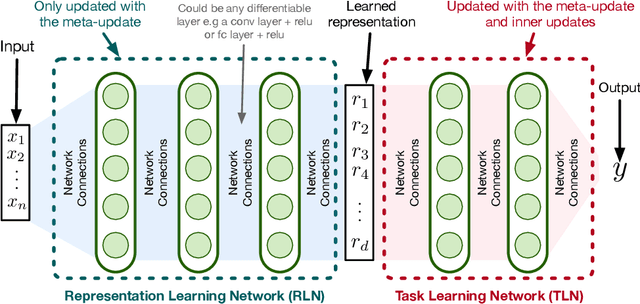
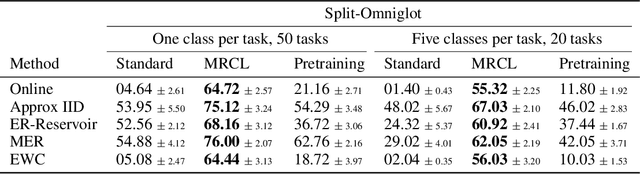
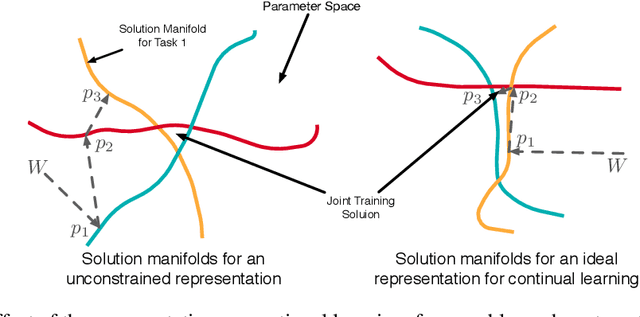

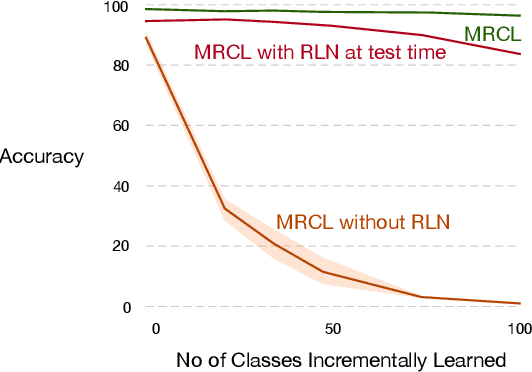
A continual learning agent should be able to build on top of existing knowledge to learn on new data quickly while minimizing forgetting. Current intelligent systems based on neural network function approximators arguably do the opposite---they are highly prone to forgetting and rarely trained to facilitate future learning. One reason for this poor behavior is that they learn from a representation that is not explicitly trained for these two goals. In this paper, we propose MRCL, an objective to explicitly learn representations that accelerate future learning and are robust to forgetting under online updates in continual learning. The idea is to optimize the representation such that online updates minimize error on all samples with little forgetting. We show that it is possible to learn representations that are more effective for online updating and that sparsity naturally emerges in these representations. Moreover, our method is complementary to existing continual learning strategies, like MER, which can learn more effectively from representations learned by our objective. Finally, we demonstrate that a basic online updating strategy with our learned representation is competitive with rehearsal based methods for continual learning. We release an implementation of our method at https://github.com/khurramjaved96/mrcl .
Planning with Expectation Models
Apr 03, 2019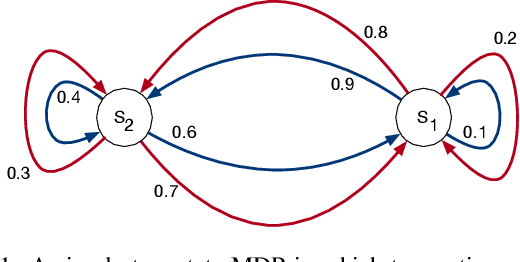
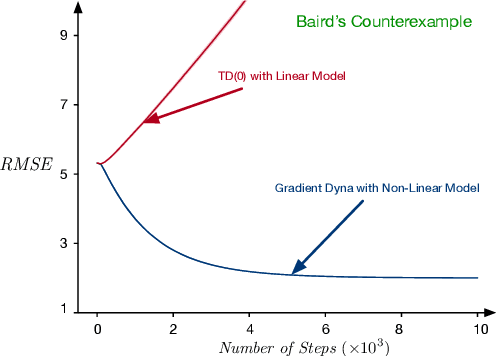
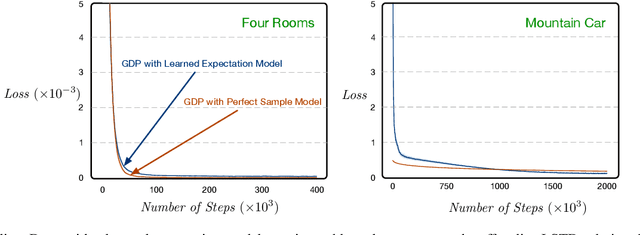
Distribution and sample models are two popular model choices in model-based reinforcement learning (MBRL). However, learning these models can be intractable, particularly when the state and action spaces are large. Expectation models, on the other hand, are relatively easier to learn due to their compactness and have also been widely used for deterministic environments. For stochastic environments, it is not obvious how expectation models can be used for planning as they only partially characterize a distribution. In this paper, we propose a sound way of using approximate expectation models for MBRL. In particular, we 1) show that planning with an expectation model is equivalent to planning with a distribution model if the state value function is linear in state features, 2) analyze two common parametrization choices for approximating the expectation: linear and non-linear expectation models, 3) propose a sound model-based policy evaluation algorithm and present its convergence results, and 4) empirically demonstrate the effectiveness of the proposed planning algorithm.