 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes CLIP Bind Concepts? Probing Compositionality in Large Image Models
Dec 20, 2022



Large-scale models combining text and images have made incredible progress in recent years. However, they can still fail at tasks requiring compositional knowledge, such as correctly picking out a red cube from a picture of multiple shapes. We examine the ability of CLIP (Radford et al., 2021), to caption images requiring compositional knowledge. We implement five compositional language models to probe the kinds of structure that CLIP may be using, and develop a novel training algorithm, Compositional Skipgram for Images (CoSI), to train these models. We look at performance in attribute-based tasks, requiring the identification of a particular combination of attribute and object (such as "red cube"), and in relational settings, where the spatial relation between two shapes (such as "cube behind sphere") must be identified. We find that in some conditions, CLIP is able to learn attribute-object labellings, and to generalize to unseen attribute-object combinations. However, we also see evidence that CLIP is not able to bind features together reliably. Moreover, CLIP is not able to reliably learn relations between objects, whereas some compositional models are able to learn these perfectly. Of the five models we developed, none were able to generalize to unseen relations.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Modelling Lexical Ambiguity with Density Matrices
Oct 12, 2020
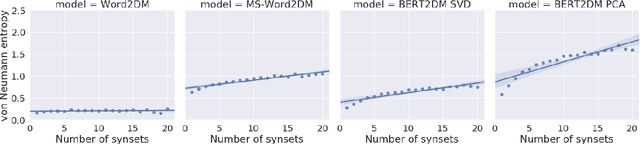
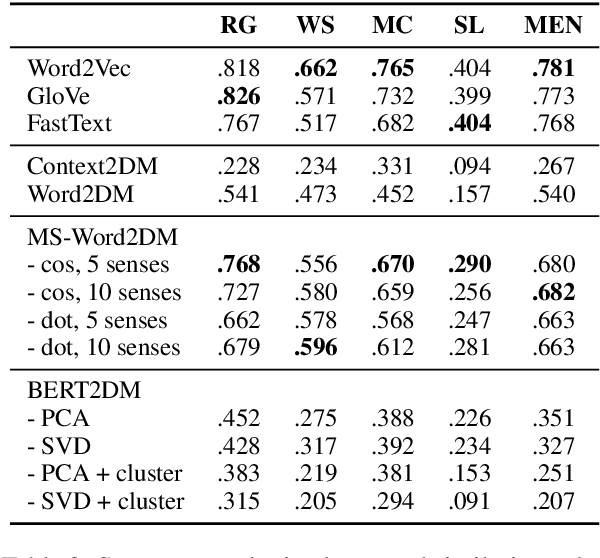
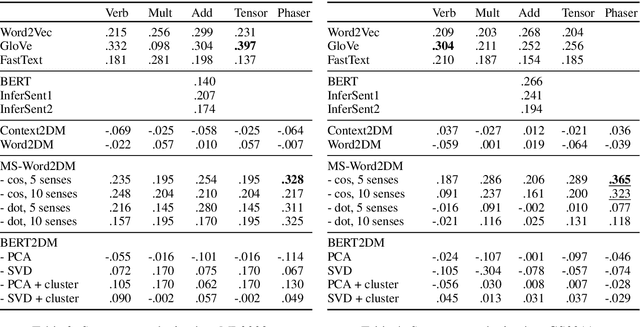
Words can have multiple senses. Compositional distributional models of meaning have been argued to deal well with finer shades of meaning variation known as polysemy, but are not so well equipped to handle word senses that are etymologically unrelated, or homonymy. Moving from vectors to density matrices allows us to encode a probability distribution over different senses of a word, and can also be accommodated within a compositional distributional model of meaning. In this paper we present three new neural models for learning density matrices from a corpus, and test their ability to discriminate between word senses on a range of compositional datasets. When paired with a particular composition method, our best model outperforms existing vector-based compositional models as well as strong sentence encoders.
Cats climb entails mammals move: preserving hyponymy in compositional distributional semantics
May 29, 2020
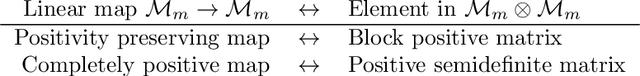
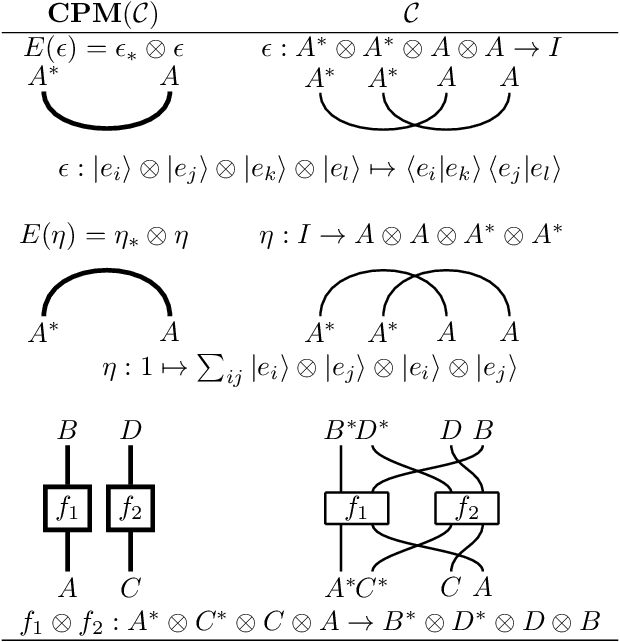
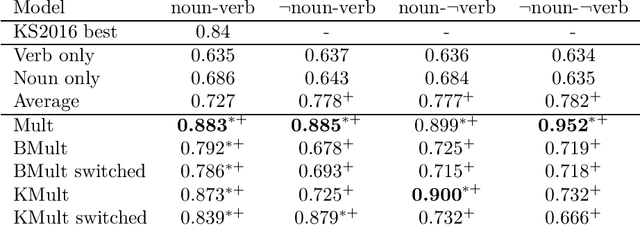
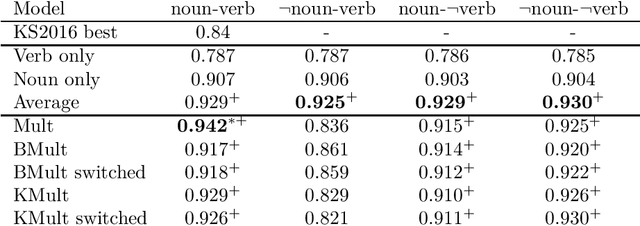
To give vector-based representations of meaning more structure, one approach is to use positive semidefinite (psd) matrices. These allow us to model similarity of words as well as the hyponymy or is-a relationship. Psd matrices can be learnt relatively easily in a given vector space $M\otimes M^*$, but to compose words to form phrases and sentences, we need representations in larger spaces. In this paper, we introduce a generic way of composing the psd matrices corresponding to words. We propose that psd matrices for verbs, adjectives, and other functional words be lifted to completely positive (CP) maps that match their grammatical type. This lifting is carried out by our composition rule called Compression, Compr. In contrast to previous composition rules like Fuzz and Phaser (a.k.a. KMult and BMult), Compr preserves hyponymy. Mathematically, Compr is itself a CP map, and is therefore linear and generally non-commutative. We give a number of proposals for the structure of Compr, based on spiders, cups and caps, and generate a range of composition rules. We test these rules on a small sentence entailment dataset, and see some improvements over the performance of Fuzz and Phaser.
Towards logical negation for compositional distributional semantics
May 11, 2020

The categorical compositional distributional model of meaning gives the composition of words into phrases and sentences pride of place. However, it has so far lacked a model of logical negation. This paper gives some steps towards providing this operator, modelling it as a version of projection onto the subspace orthogonal to a word. We give a small demonstration of the operators performance in a sentence entailment task.
Compositionality for Recursive Neural Networks
Jan 30, 2019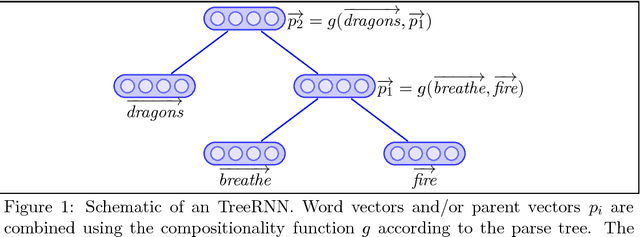
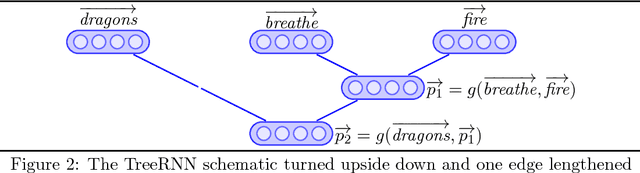

Modelling compositionality has been a longstanding area of research in the field of vector space semantics. The categorical approach to compositionality maps grammar onto vector spaces in a principled way, but comes under fire for requiring the formation of very high-dimensional matrices and tensors, and therefore being computationally infeasible. In this paper I show how a linear simplification of recursive neural tensor network models can be mapped directly onto the categorical approach, giving a way of computing the required matrices and tensors. This mapping suggests a number of lines of research for both categorical compositional vector space models of meaning and for recursive neural network models of compositionality.
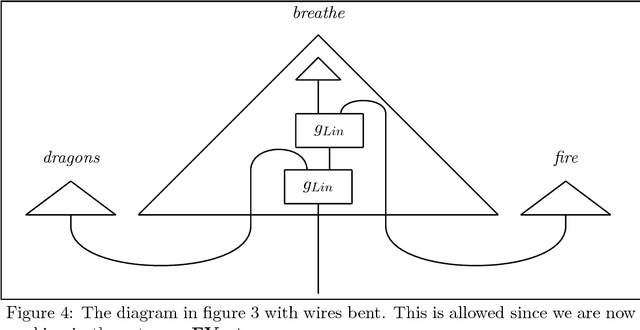
Internal Wiring of Cartesian Verbs and Prepositions
Nov 08, 2018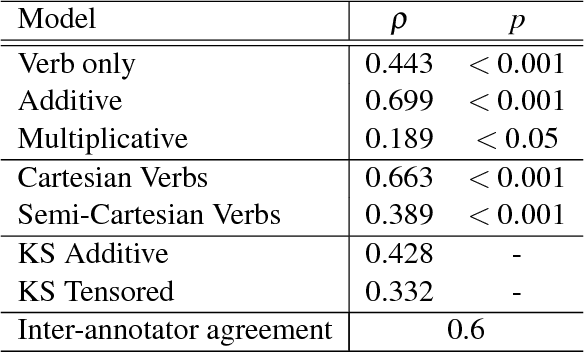
Categorical compositional distributional semantics (CCDS) allows one to compute the meaning of phrases and sentences from the meaning of their constituent words. A type-structure carried over from the traditional categorial model of grammar a la Lambek becomes a 'wire-structure' that mediates the interaction of word meanings. However, CCDS has a much richer logical structure than plain categorical semantics in that certain words can also be given an 'internal wiring' that either provides their entire meaning or reduces the size their meaning space. Previous examples of internal wiring include relative pronouns and intersective adjectives. Here we establish the same for a large class of well-behaved transitive verbs to which we refer as Cartesian verbs, and reduce the meaning space from a ternary tensor to a unary one. Some experimental evidence is also provided.
* In Proceedings CAPNS 2018, arXiv:1811.02701
Translating and Evolving: Towards a Model of Language Change in DisCoCat
Nov 08, 2018The categorical compositional distributional (DisCoCat) model of meaning developed by Coecke et al. (2010) has been successful in modeling various aspects of meaning. However, it fails to model the fact that language can change. We give an approach to DisCoCat that allows us to represent language models and translations between them, enabling us to describe translations from one language to another, or changes within the same language. We unify the product space representation given in (Coecke et al., 2010) and the functorial description in (Kartsaklis et al., 2013), in a way that allows us to view a language as a catalogue of meanings. We formalize the notion of a lexicon in DisCoCat, and define a dictionary of meanings between two lexicons. All this is done within the framework of monoidal categories. We give examples of how to apply our methods, and give a concrete suggestion for compositional translation in corpora.
* In Proceedings CAPNS 2018, arXiv:1811.02701
Proceedings of the 2018 Workshop on Compositional Approaches in Physics, NLP, and Social Sciences
Nov 06, 2018The ability to compose parts to form a more complex whole, and to analyze a whole as a combination of elements, is desirable across disciplines. This workshop bring together researchers applying compositional approaches to physics, NLP, cognitive science, and game theory. Within NLP, a long-standing aim is to represent how words can combine to form phrases and sentences. Within the framework of distributional semantics, words are represented as vectors in vector spaces. The categorical model of Coecke et al. [2010], inspired by quantum protocols, has provided a convincing account of compositionality in vector space models of NLP. There is furthermore a history of vector space models in cognitive science. Theories of categorization such as those developed by Nosofsky [1986] and Smith et al. [1988] utilise notions of distance between feature vectors. More recently G\"ardenfors [2004, 2014] has developed a model of concepts in which conceptual spaces provide geometric structures, and information is represented by points, vectors and regions in vector spaces. The same compositional approach has been applied to this formalism, giving conceptual spaces theory a richer model of compositionality than previously [Bolt et al., 2018]. Compositional approaches have also been applied in the study of strategic games and Nash equilibria. In contrast to classical game theory, where games are studied monolithically as one global object, compositional game theory works bottom-up by building large and complex games from smaller components. Such an approach is inherently difficult since the interaction between games has to be considered. Research into categorical compositional methods for this field have recently begun [Ghani et al., 2018]. Moreover, the interaction between the three disciplines of cognitive science, linguistics and game theory is a fertile ground for research. Game theory in cognitive science is a well-established area [Camerer, 2011]. Similarly game theoretic approaches have been applied in linguistics [J\"ager, 2008]. Lastly, the study of linguistics and cognitive science is intimately intertwined [Smolensky and Legendre, 2006, Jackendoff, 2007]. Physics supplies compositional approaches via vector spaces and categorical quantum theory, allowing the interplay between the three disciplines to be examined.
Towards functorial language-games
Jul 20, 2018In categorical compositional semantics of natural language one studies functors from a category of grammatical derivations (such as a Lambek pregroup) to a semantic category (such as real vector spaces). We compositionally build game-theoretic semantics of sentences by taking the semantic category to be the category whose morphisms are open games. This requires some modifications to the grammar category to compensate for the failure of open games to form a compact closed category. We illustrate the theory using simple examples of Wittgenstein's language-games.