 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBURG-Toolkit: Robot Grasping Experiments in Simulation and the Real World
May 27, 2022
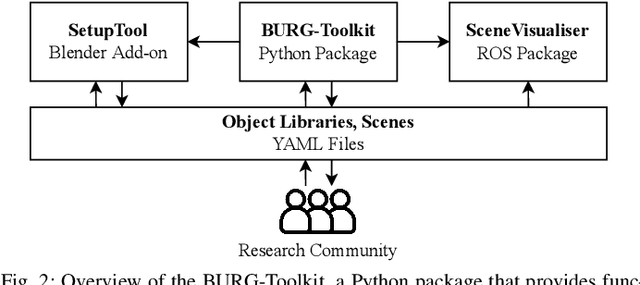

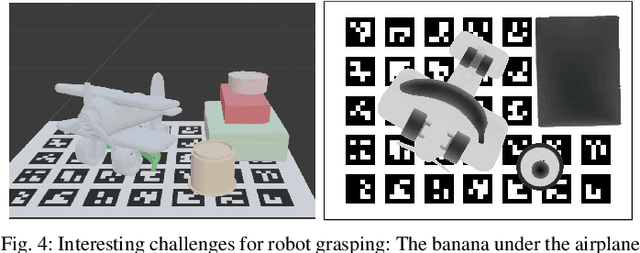
This paper presents BURG-Toolkit, a set of open-source tools for Benchmarking and Understanding Robotic Grasping. Our tools allow researchers to: (1) create virtual scenes for generating training data and performing grasping in simulation; (2) recreate the scene by arranging the corresponding objects accurately in the physical world for real robot experiments, supporting an analysis of the sim-to-real gap; and (3) share the scenes with other researchers to foster comparability and reproducibility of experimental results. We explain how to use our tools by describing some potential use cases. We further provide proof-of-concept experimental results quantifying the sim-to-real gap for robot grasping in some example scenes. The tools are available at: https://mrudorfer.github.io/burg-toolkit/
SporeAgent: Reinforced Scene-level Plausibility for Object Pose Refinement
Jan 01, 2022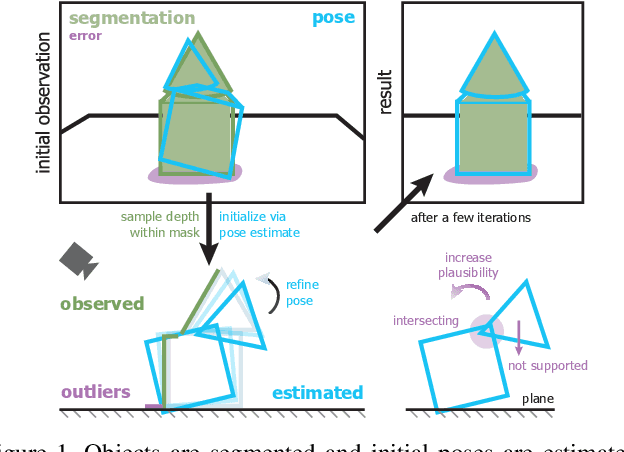
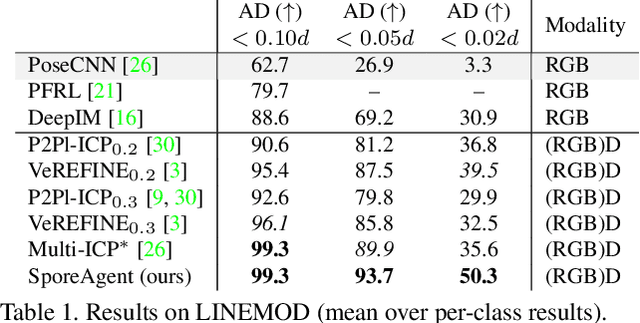
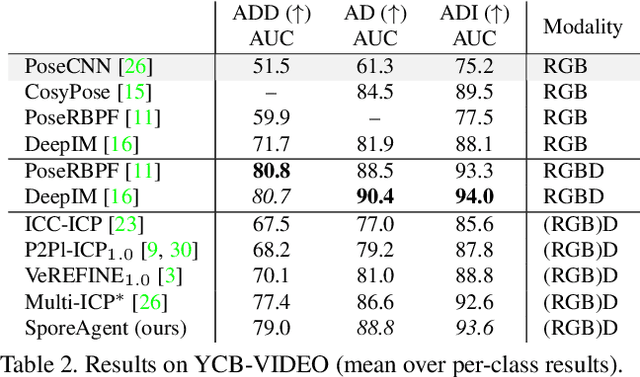
Observational noise, inaccurate segmentation and ambiguity due to symmetry and occlusion lead to inaccurate object pose estimates. While depth- and RGB-based pose refinement approaches increase the accuracy of the resulting pose estimates, they are susceptible to ambiguity in the observation as they consider visual alignment. We propose to leverage the fact that we often observe static, rigid scenes. Thus, the objects therein need to be under physically plausible poses. We show that considering plausibility reduces ambiguity and, in consequence, allows poses to be more accurately predicted in cluttered environments. To this end, we extend a recent RL-based registration approach towards iterative refinement of object poses. Experiments on the LINEMOD and YCB-VIDEO datasets demonstrate the state-of-the-art performance of our depth-based refinement approach.
Event-Based high-speed low-latency fiducial marker tracking
Oct 12, 2021
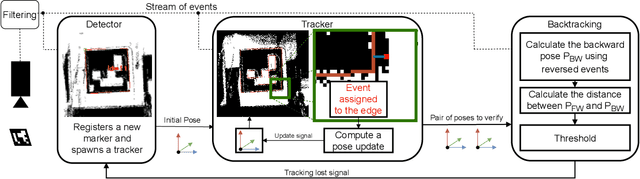

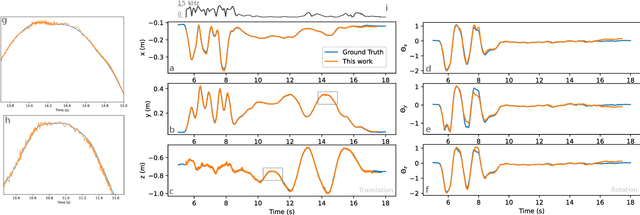
Motion and dynamic environments, especially under challenging lighting conditions, are still an open issue for robust robotic applications. In this paper, we propose an end-to-end pipeline for real-time, low latency, 6 degrees-of-freedom pose estimation of fiducial markers. Instead of achieving a pose estimation through a conventional frame-based approach, we employ the high-speed abilities of event-based sensors to directly refine the spatial transformation, using consecutive events. Furthermore, we introduce a novel two-way verification process for detecting tracking errors by backtracking the estimated pose, allowing us to evaluate the quality of our tracking. This approach allows us to achieve pose estimation at a rate up to 156~kHz, while only relying on CPU resources. The average end-to-end latency of our method is 3~ms. Experimental results demonstrate outstanding potential for robotic tasks, such as visual servoing in fast action-perception loops.
UnrealROX+: An Improved Tool for Acquiring Synthetic Data from Virtual 3D Environments
Apr 23, 2021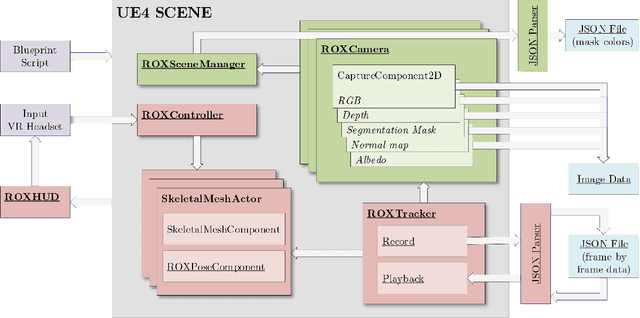



Synthetic data generation has become essential in last years for feeding data-driven algorithms, which surpassed traditional techniques performance in almost every computer vision problem. Gathering and labelling the amount of data needed for these data-hungry models in the real world may become unfeasible and error-prone, while synthetic data give us the possibility of generating huge amounts of data with pixel-perfect annotations. However, most synthetic datasets lack from enough realism in their rendered images. In that context UnrealROX generation tool was presented in 2019, allowing to generate highly realistic data, at high resolutions and framerates, with an efficient pipeline based on Unreal Engine, a cutting-edge videogame engine. UnrealROX enabled robotic vision researchers to generate realistic and visually plausible data with full ground truth for a wide variety of problems such as class and instance semantic segmentation, object detection, depth estimation, visual grasping, and navigation. Nevertheless, its workflow was very tied to generate image sequences from a robotic on-board camera, making hard to generate data for other purposes. In this work, we present UnrealROX+, an improved version of UnrealROX where its decoupled and easy-to-use data acquisition system allows to quickly design and generate data in a much more flexible and customizable way. Moreover, it is packaged as an Unreal plug-in, which makes it more comfortable to use with already existing Unreal projects, and it also includes new features such as generating albedo or a Python API for interacting with the virtual environment from Deep Learning frameworks.
Risk-Averse Biased Human Policies in Assistive Multi-Armed Bandit Settings
Apr 12, 2021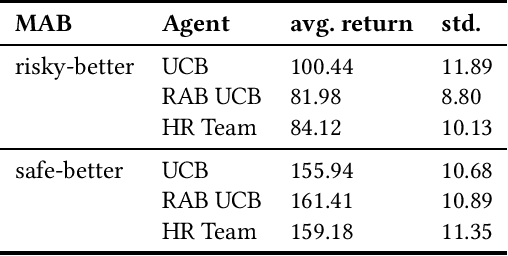
Assistive multi-armed bandit problems can be used to model team situations between a human and an autonomous system like a domestic service robot. To account for human biases such as the risk-aversion described in the Cumulative Prospect Theory, the setting is expanded to using observable rewards. When robots leverage knowledge about the risk-averse human model they eliminate the bias and make more rational choices. We present an algorithm that increases the utility value of such human-robot teams. A brief evaluation indicates that arbitrary reward functions can be handled.
ReAgent: Point Cloud Registration using Imitation and Reinforcement Learning
Mar 28, 2021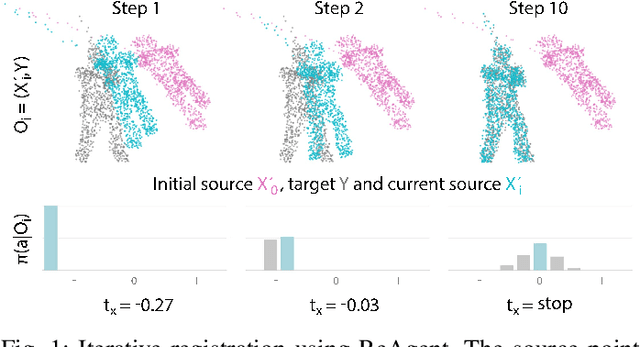
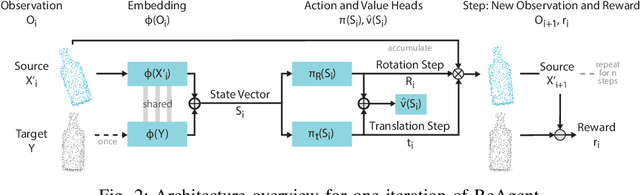
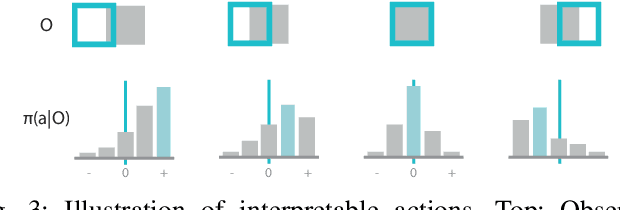
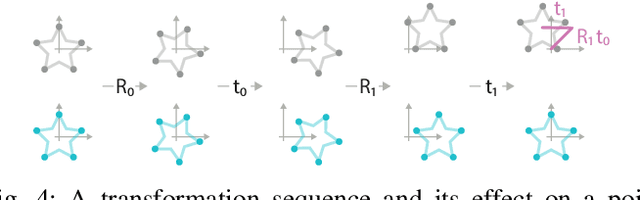
Point cloud registration is a common step in many 3D computer vision tasks such as object pose estimation, where a 3D model is aligned to an observation. Classical registration methods generalize well to novel domains but fail when given a noisy observation or a bad initialization. Learning-based methods, in contrast, are more robust but lack in generalization capacity. We propose to consider iterative point cloud registration as a reinforcement learning task and, to this end, present a novel registration agent (ReAgent). We employ imitation learning to initialize its discrete registration policy based on a steady expert policy. Integration with policy optimization, based on our proposed alignment reward, further improves the agent's registration performance. We compare our approach to classical and learning-based registration methods on both ModelNet40 (synthetic) and ScanObjectNN (real data) and show that our ReAgent achieves state-of-the-art accuracy. The lightweight architecture of the agent, moreover, enables reduced inference time as compared to related approaches. In addition, we apply our method to the object pose estimation task on real data (LINEMOD), outperforming state-of-the-art pose refinement approaches.
Sim2Real 3D Object Classification using Spherical Kernel Point Convolution and a Deep Center Voting Scheme
Mar 10, 2021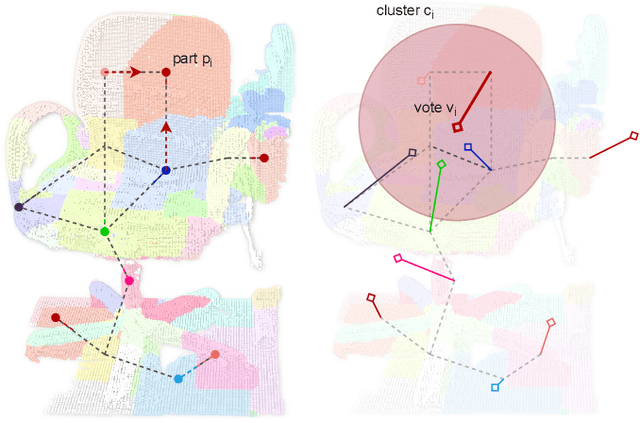
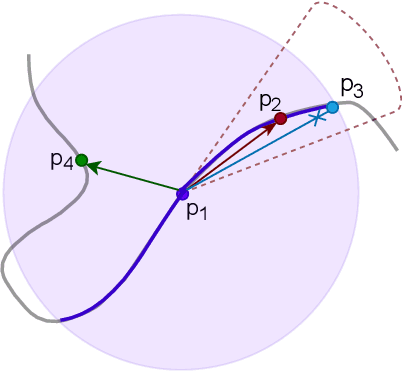
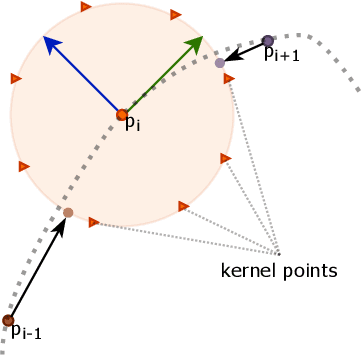
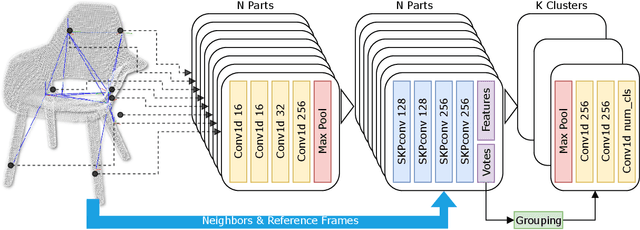
While object semantic understanding is essential for most service robotic tasks, 3D object classification is still an open problem. Learning from artificial 3D models alleviates the cost of annotation necessary to approach this problem, but most methods still struggle with the differences existing between artificial and real 3D data. We conjecture that the cause of those issue is the fact that many methods learn directly from point coordinates, instead of the shape, as the former is hard to center and to scale under variable occlusions reliably. We introduce spherical kernel point convolutions that directly exploit the object surface, represented as a graph, and a voting scheme to limit the impact of poor segmentation on the classification results. Our proposed approach improves upon state-of-the-art methods by up to 36% when transferring from artificial objects to real objects.
PyraPose: Feature Pyramids for Fast and Accurate Object Pose Estimation under Domain Shift
Oct 30, 2020
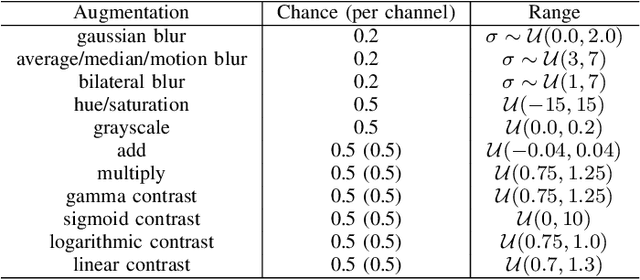
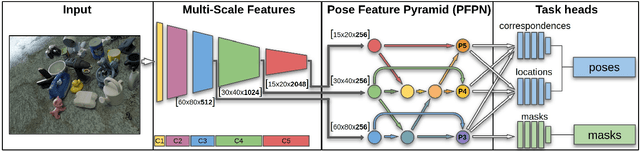
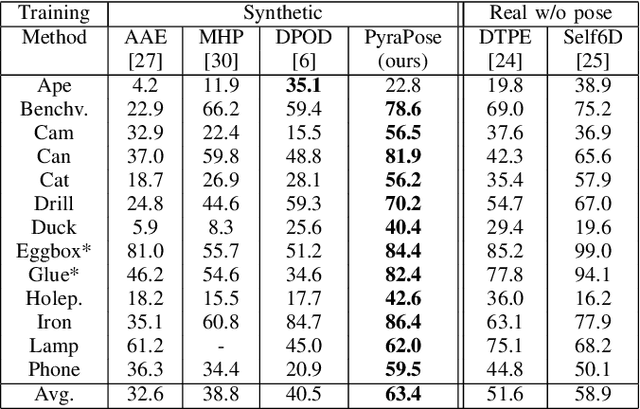
Object pose estimation enables robots to understand and interact with their environments. Training with synthetic data is necessary in order to adapt to novel situations. Unfortunately, pose estimation under domain shift, i.e., training on synthetic data and testing in the real world, is challenging. Deep learning-based approaches currently perform best when using encoder-decoder networks but typically do not generalize to new scenarios with different scene characteristics. We argue that patch-based approaches, instead of encoder-decoder networks, are more suited for synthetic-to-real transfer because local to global object information is better represented. To that end, we present a novel approach based on a specialized feature pyramid network to compute multi-scale features for creating pose hypotheses on different feature map resolutions in parallel. Our single-shot pose estimation approach is evaluated on multiple standard datasets and outperforms the state of the art by up to 35%. We also perform grasping experiments in the real world to demonstrate the advantage of using synthetic data to generalize to novel environments.
Neural Object Learning for 6D Pose Estimation Using a Few Cluttered Images
May 07, 2020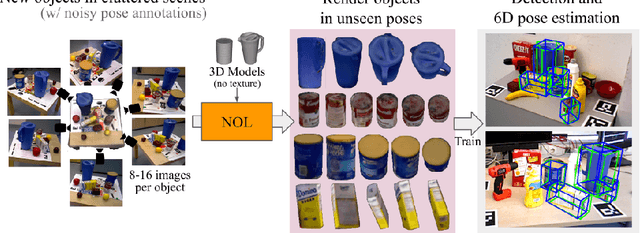
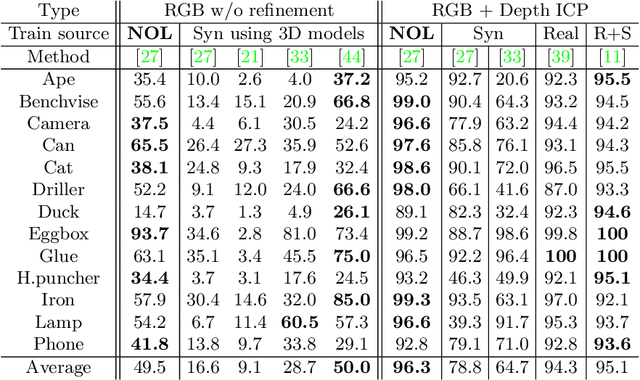
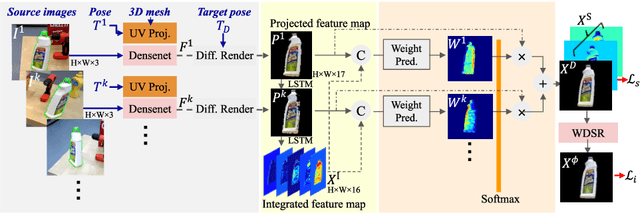

Recent methods for 6D pose estimation of objects assume either textured 3D models or real images that cover the entire range of target poses. However, it is difficult to obtain textured 3D models and annotate the poses of objects in real scenarios. This paper proposes a method, Neural Object Learning (NOL), that creates synthetic images of objects in arbitrary poses by combining only a few observations from cluttered images. A novel refinement step is proposed to align inaccurate poses of objects in source images, which results in better quality images. Evaluations performed on two public datasets show that the rendered images created by NOL lead to state-of-the-art performance in comparison to methods that use 10 times the number of real images. Evaluations on our new dataset show multiple objects can be trained and recognized simultaneously using a sequence of a fixed scene.
Unsupervised Domain Adaptation through Inter-modal Rotation for RGB-D Object Recognition
Apr 21, 2020
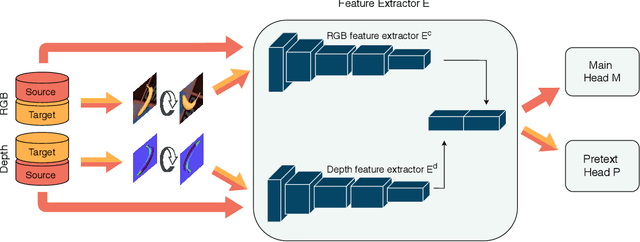


Unsupervised Domain Adaptation (DA) exploits the supervision of a label-rich source dataset to make predictions on an unlabeled target dataset by aligning the two data distributions. In robotics, DA is used to take advantage of automatically generated synthetic data, that come with "free" annotation, to make effective predictions on real data. However, existing DA methods are not designed to cope with the multi-modal nature of RGB-D data, which are widely used in robotic vision. We propose a novel RGB-D DA method that reduces the synthetic-to-real domain shift by exploiting the inter-modal relation between the RGB and depth image. Our method consists of training a convolutional neural network to solve, in addition to the main recognition task, the pretext task of predicting the relative rotation between the RGB and depth image. To evaluate our method and encourage further research in this area, we define two benchmark datasets for object categorization and instance recognition. With extensive experiments, we show the benefits of leveraging the inter-modal relations for RGB-D DA.