 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Playtesting for Game Parameter Tuning via Active Learning
Aug 04, 2019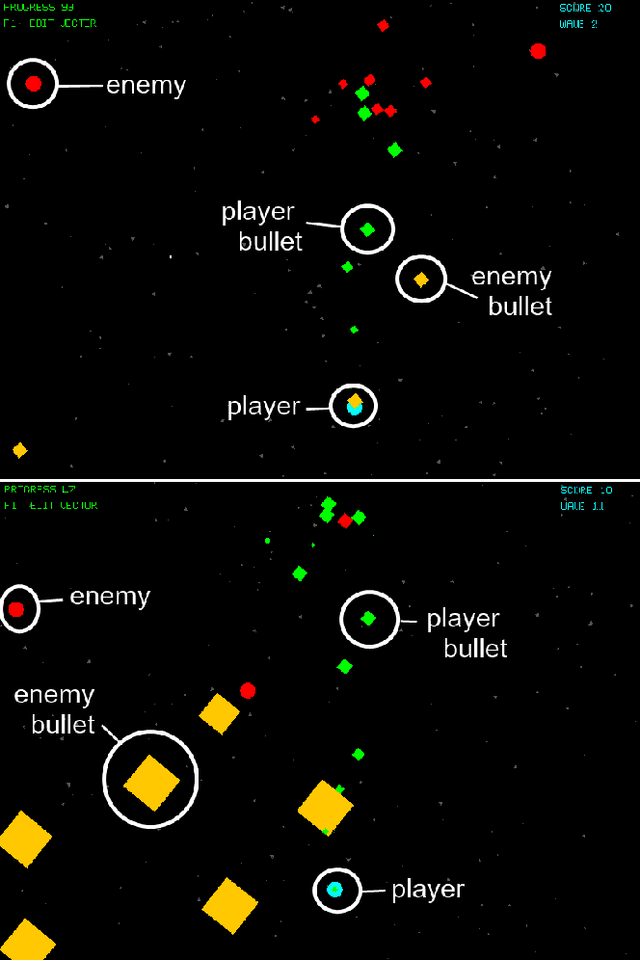
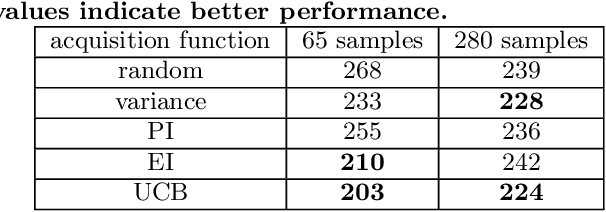
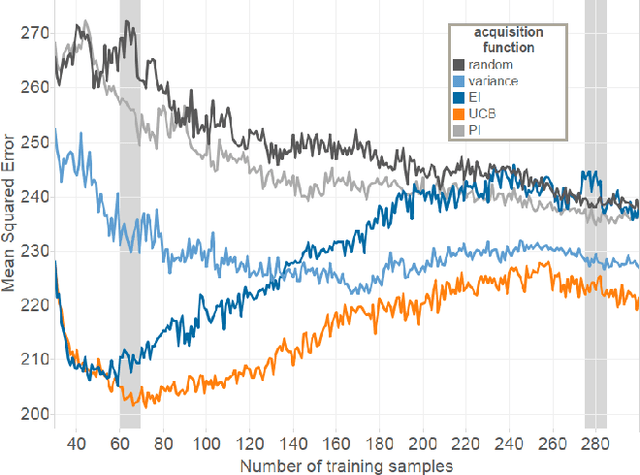
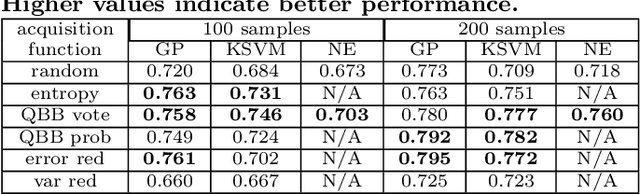
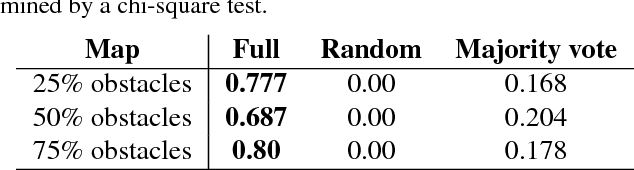
Game designers use human playtesting to gather feedback about game design elements when iteratively improving a game. Playtesting, however, is expensive: human testers must be recruited, playtest results must be aggregated and interpreted, and changes to game designs must be extrapolated from these results. Can automated methods reduce this expense? We show how active learning techniques can formalize and automate a subset of playtesting goals. Specifically, we focus on the low-level parameter tuning required to balance a game once the mechanics have been chosen. Through a case study on a shoot-`em-up game we demonstrate the efficacy of active learning to reduce the amount of playtesting needed to choose the optimal set of game parameters for two classes of (formal) design objectives. This work opens the potential for additional methods to reduce the human burden of performing playtesting for a variety of relevant design concerns.
Human-Centered Artificial Intelligence and Machine Learning
Jan 31, 2019Humans are increasingly coming into contact with artificial intelligence and machine learning systems. Human-centered artificial intelligence is a perspective on AI and ML that algorithms must be designed with awareness that they are part of a larger system consisting of humans. We lay forth an argument that human-centered artificial intelligence can be broken down into two aspects: (1) AI systems that understand humans from a sociocultural perspective, and (2) AI systems that help humans understand them. We further argue that issues of social responsibility such as fairness, accountability, interpretability, and transparency.
Playing Text-Adventure Games with Graph-Based Deep Reinforcement Learning
Dec 04, 2018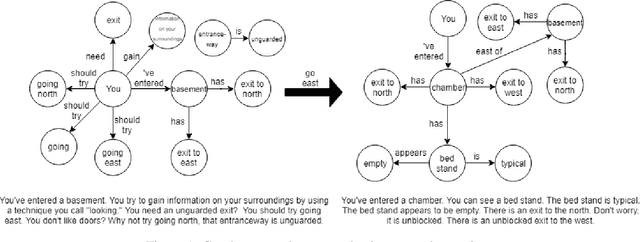

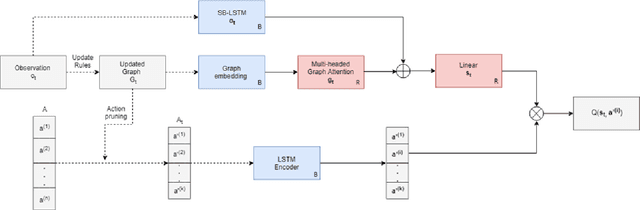

Text-based adventure games provide a platform on which to explore reinforcement learning in the context of a combinatorial action space, such as natural language. We present a deep reinforcement learning architecture that represents the game state as a knowledge graph which is learned during exploration. This graph is used to prune the action space, enabling more efficient exploration. The question of which action to take can be reduced to a question-answering task, a form of transfer learning that pre-trains certain parts of our architecture. In experiments using the TextWorld framework, we show that our proposed technique can learn a control policy faster than baseline alternatives.
Controllable Neural Story Generation via Reinforcement Learning
Sep 27, 2018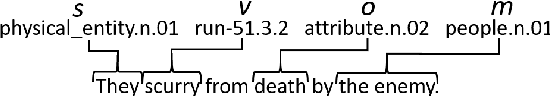
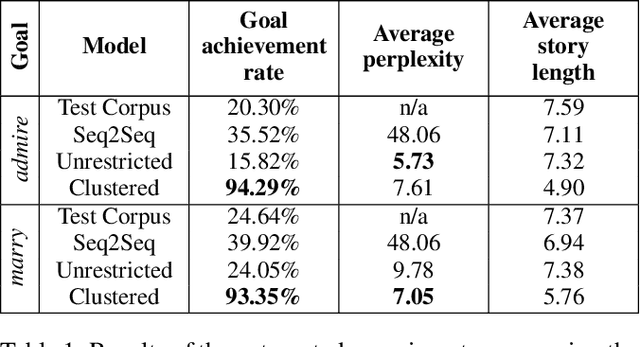
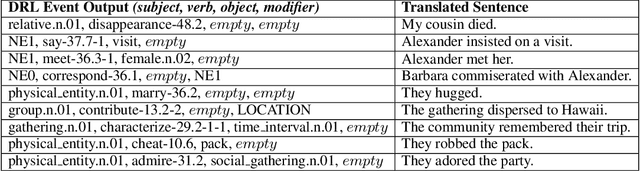
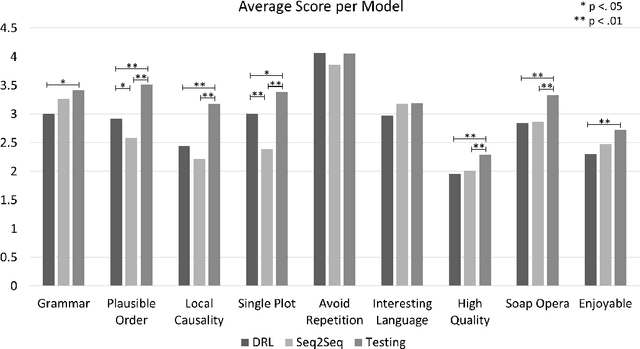
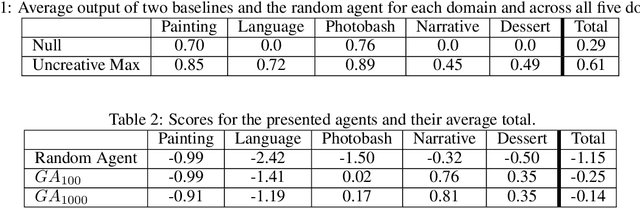
Open story generation is the problem of automatically creating a story for any domain without retraining. Neural language models can be trained on large corpora across many domains and then used to generate stories. However, stories generated via language models tend to lack direction and coherence. We introduce a policy gradient reinforcement learning approach to open story generation that learns to achieve a given narrative goal state. In this work, the goal is for a story to end with a specific type of event, given in advance. However, a reward based on achieving the given goal is too sparse for effective learning. We use reward shaping to provide the reinforcement learner with a partial reward at every step. We show that our technique can train a model that generates a story that reaches the goal 94% of the time and reduces model perplexity. A human subject evaluation shows that stories generated by our technique are perceived to have significantly higher plausible event ordering and plot coherence over a baseline language modeling technique without perceived degradation of overall quality, enjoyability, or local causality.
Combinets: Creativity via Recombination of Neural Networks
Sep 06, 2018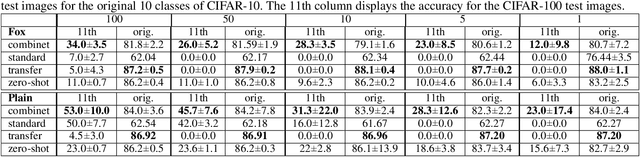


One of the defining characteristics of human creativity is the ability to make conceptual leaps, creating something surprising from typical knowledge. In comparison, deep neural networks often struggle to handle cases outside of their training data, which is especially problematic for problems with limited training data. Approaches exist to transfer knowledge from problems with sufficient data to those with insufficient data, but they tend to require additional training or a domain-specific method of transfer. We present a new approach, conceptual expansion, that serves as a general representation for reusing existing trained models to derive new models without backpropagation. We evaluate our approach on few-shot variations of two tasks: image classification and image generation, and outperform standard transfer learning approaches.
Creative Invention Benchmark
May 09, 2018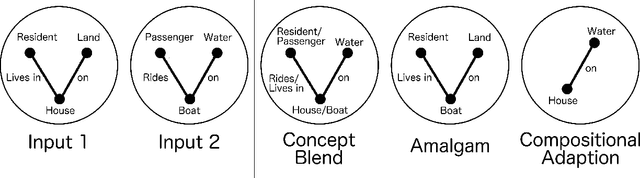

In this paper we present the Creative Invention Benchmark (CrIB), a 2000-problem benchmark for evaluating a particular facet of computational creativity. Specifically, we address combinational p-creativity, the creativity at play when someone combines existing knowledge to achieve a solution novel to that individual. We present generation strategies for the five problem categories of the benchmark and a set of initial baselines.
Rationalization: A Neural Machine Translation Approach to Generating Natural Language Explanations
Dec 19, 2017
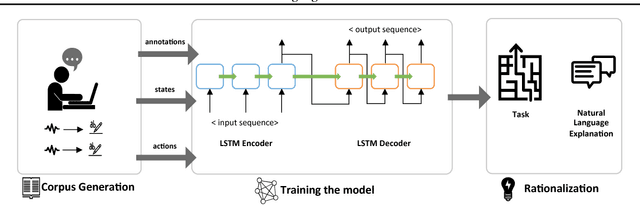
We introduce AI rationalization, an approach for generating explanations of autonomous system behavior as if a human had performed the behavior. We describe a rationalization technique that uses neural machine translation to translate internal state-action representations of an autonomous agent into natural language. We evaluate our technique in the Frogger game environment, training an autonomous game playing agent to rationalize its action choices using natural language. A natural language training corpus is collected from human players thinking out loud as they play the game. We motivate the use of rationalization as an approach to explanation generation and show the results of two experiments evaluating the effectiveness of rationalization. Results of these evaluations show that neural machine translation is able to accurately generate rationalizations that describe agent behavior, and that rationalizations are more satisfying to humans than other alternative methods of explanation.
Guiding Reinforcement Learning Exploration Using Natural Language
Sep 14, 2017
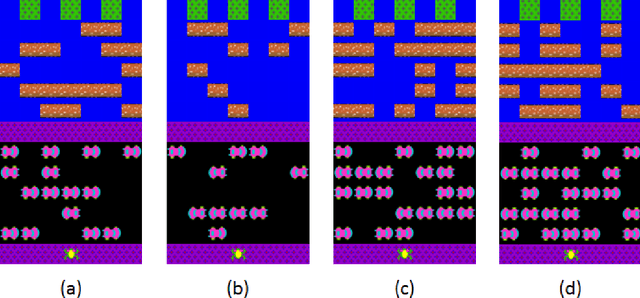
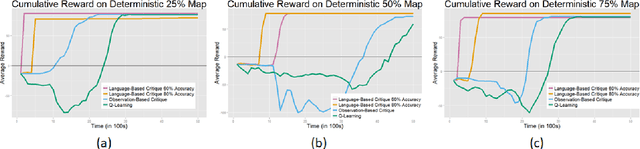
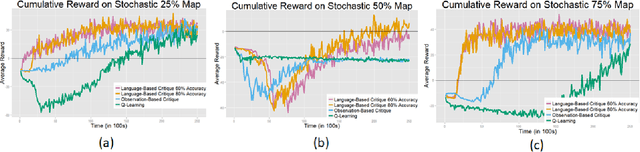
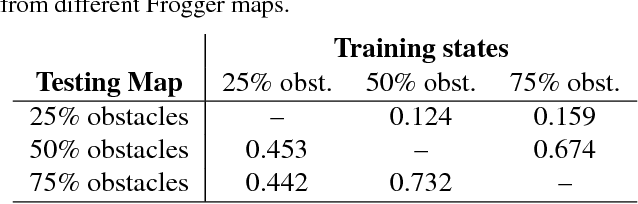
In this work we present a technique to use natural language to help reinforcement learning generalize to unseen environments. This technique uses neural machine translation, specifically the use of encoder-decoder networks, to learn associations between natural language behavior descriptions and state-action information. We then use this learned model to guide agent exploration using a modified version of policy shaping to make it more effective at learning in unseen environments. We evaluate this technique using the popular arcade game, Frogger, under ideal and non-ideal conditions. This evaluation shows that our modified policy shaping algorithm improves over a Q-learning agent as well as a baseline version of policy shaping.
Explore, Exploit or Listen: Combining Human Feedback and Policy Model to Speed up Deep Reinforcement Learning in 3D Worlds
Sep 12, 2017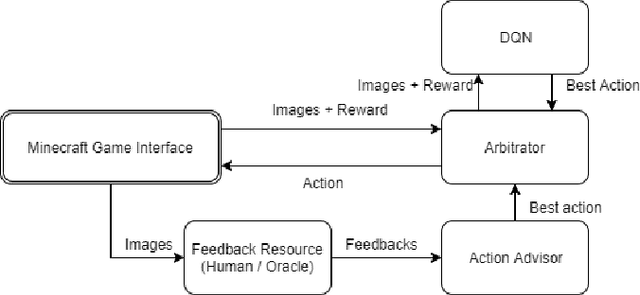

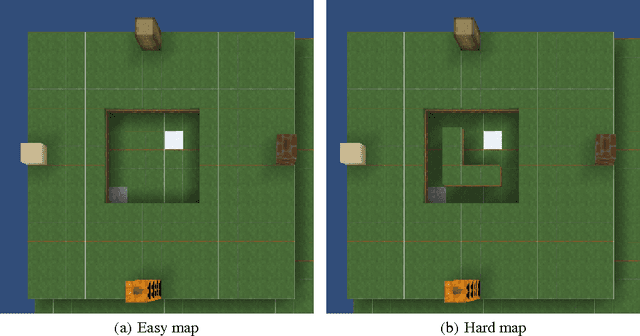
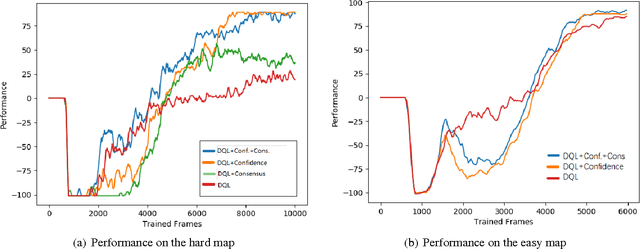
We describe a method to use discrete human feedback to enhance the performance of deep learning agents in virtual three-dimensional environments by extending deep-reinforcement learning to model the confidence and consistency of human feedback. This enables deep reinforcement learning algorithms to determine the most appropriate time to listen to the human feedback, exploit the current policy model, or explore the agent's environment. Managing the trade-off between these three strategies allows DRL agents to be robust to inconsistent or intermittent human feedback. Through experimentation using a synthetic oracle, we show that our technique improves the training speed and overall performance of deep reinforcement learning in navigating three-dimensional environments using Minecraft. We further show that our technique is robust to highly innacurate human feedback and can also operate when no human feedback is given.
Event Representations for Automated Story Generation with Deep Neural Nets
Sep 12, 2017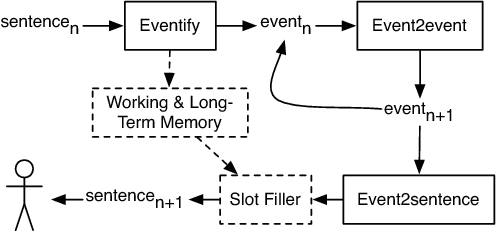
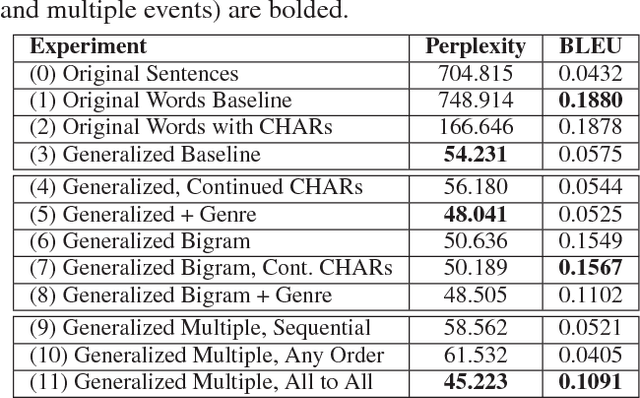
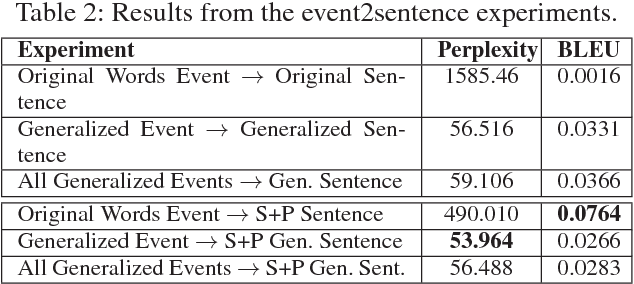
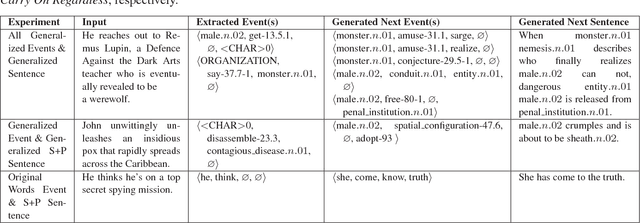
Automated story generation is the problem of automatically selecting a sequence of events, actions, or words that can be told as a story. We seek to develop a system that can generate stories by learning everything it needs to know from textual story corpora. To date, recurrent neural networks that learn language models at character, word, or sentence levels have had little success generating coherent stories. We explore the question of event representations that provide a mid-level of abstraction between words and sentences in order to retain the semantic information of the original data while minimizing event sparsity. We present a technique for preprocessing textual story data into event sequences. We then present a technique for automated story generation whereby we decompose the problem into the generation of successive events (event2event) and the generation of natural language sentences from events (event2sentence). We give empirical results comparing different event representations and their effects on event successor generation and the translation of events to natural language.