 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore, Exploit or Listen: Combining Human Feedback and Policy Model to Speed up Deep Reinforcement Learning in 3D Worlds
Paper and Code
Sep 12, 2017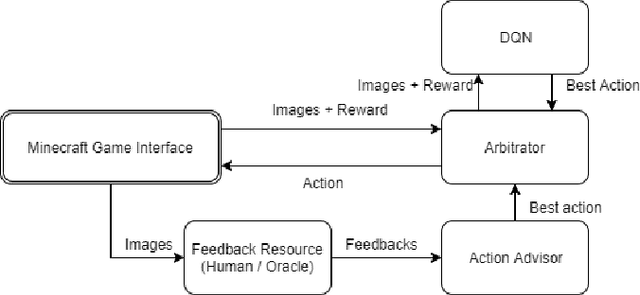

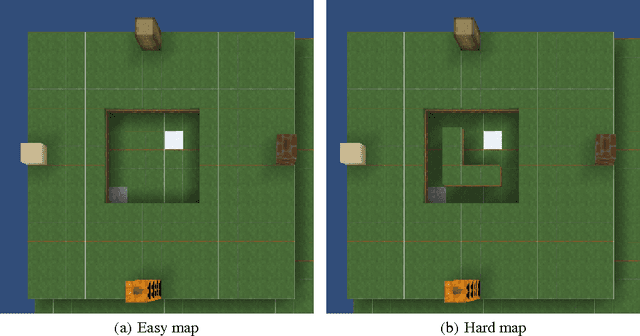
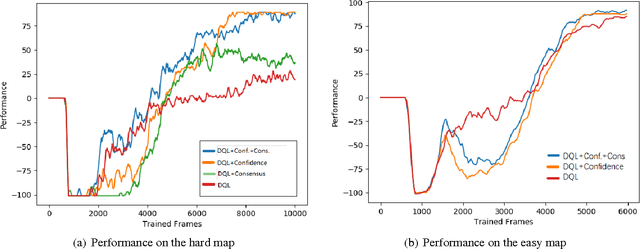
We describe a method to use discrete human feedback to enhance the performance of deep learning agents in virtual three-dimensional environments by extending deep-reinforcement learning to model the confidence and consistency of human feedback. This enables deep reinforcement learning algorithms to determine the most appropriate time to listen to the human feedback, exploit the current policy model, or explore the agent's environment. Managing the trade-off between these three strategies allows DRL agents to be robust to inconsistent or intermittent human feedback. Through experimentation using a synthetic oracle, we show that our technique improves the training speed and overall performance of deep reinforcement learning in navigating three-dimensional environments using Minecraft. We further show that our technique is robust to highly innacurate human feedback and can also operate when no human feedback is given.