 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Biases in Context-Dependent Health Questions
Mar 07, 2024Chat-based large language models have the opportunity to empower individuals lacking high-quality healthcare access to receive personalized information across a variety of topics. However, users may ask underspecified questions that require additional context for a model to correctly answer. We study how large language model biases are exhibited through these contextual questions in the healthcare domain. To accomplish this, we curate a dataset of sexual and reproductive healthcare questions that are dependent on age, sex, and location attributes. We compare models' outputs with and without demographic context to determine group alignment among our contextual questions. Our experiments reveal biases in each of these attributes, where young adult female users are favored.
An Eye on Clinical BERT: Investigating Language Model Generalization for Diabetic Eye Disease Phenotyping
Nov 15, 2023Diabetic eye disease is a major cause of blindness worldwide. The ability to monitor relevant clinical trajectories and detect lapses in care is critical to managing the disease and preventing blindness. Alas, much of the information necessary to support these goals is found only in the free text of the electronic medical record. To fill this information gap, we introduce a system for extracting evidence from clinical text of 19 clinical concepts related to diabetic eye disease and inferring relevant attributes for each. In developing this ophthalmology phenotyping system, we are also afforded a unique opportunity to evaluate the effectiveness of clinical language models at adapting to new clinical domains. Across multiple training paradigms, we find that BERT language models pretrained on out-of-distribution clinical data offer no significant improvement over BERT language models pretrained on non-clinical data for our domain. Our study tempers recent claims that language models pretrained on clinical data are necessary for clinical NLP tasks and highlights the importance of not treating clinical language data as a single homogeneous domain.
Selecting Shots for Demographic Fairness in Few-Shot Learning with Large Language Models
Nov 14, 2023Recently, work in NLP has shifted to few-shot (in-context) learning, with large language models (LLMs) performing well across a range of tasks. However, while fairness evaluations have become a standard for supervised methods, little is known about the fairness of LLMs as prediction systems. Further, common standard methods for fairness involve access to models weights or are applied during finetuning, which are not applicable in few-shot learning. Do LLMs exhibit prediction biases when used for standard NLP tasks? In this work, we explore the effect of shots, which directly affect the performance of models, on the fairness of LLMs as NLP classification systems. We consider how different shot selection strategies, both existing and new demographically sensitive methods, affect model fairness across three standard fairness datasets. We discuss how future work can include LLM fairness evaluations.
MixCE: Training Autoregressive Language Models by Mixing Forward and Reverse Cross-Entropies
May 26, 2023



Autoregressive language models are trained by minimizing the cross-entropy of the model distribution Q relative to the data distribution P -- that is, minimizing the forward cross-entropy, which is equivalent to maximum likelihood estimation (MLE). We have observed that models trained in this way may "over-generalize", in the sense that they produce non-human-like text. Moreover, we believe that reverse cross-entropy, i.e., the cross-entropy of P relative to Q, is a better reflection of how a human would evaluate text generated by a model. Hence, we propose learning with MixCE, an objective that mixes the forward and reverse cross-entropies. We evaluate models trained with this objective on synthetic data settings (where P is known) and real data, and show that the resulting models yield better generated text without complex decoding strategies. Our code and models are publicly available at https://github.com/bloomberg/mixce-acl2023
Generalizing Fairness using Multi-Task Learning without Demographic Information
May 22, 2023To ensure the fairness of machine learning systems, we can include a fairness loss during training based on demographic information associated with the training data. However, we cannot train debiased classifiers for most tasks since the relevant datasets lack demographic annotations. Can we utilize demographic data for a related task to improve the fairness of our target task? We demonstrate that demographic fairness objectives transfer to new tasks trained within a multi-task framework. We adapt a single-task fairness loss to a multi-task setting to exploit demographic labels from a related task in debiasing a target task. We explore different settings with missing demographic data and show how our loss can improve fairness even without in-task demographics, across various domains and tasks.
BloombergGPT: A Large Language Model for Finance
Mar 30, 2023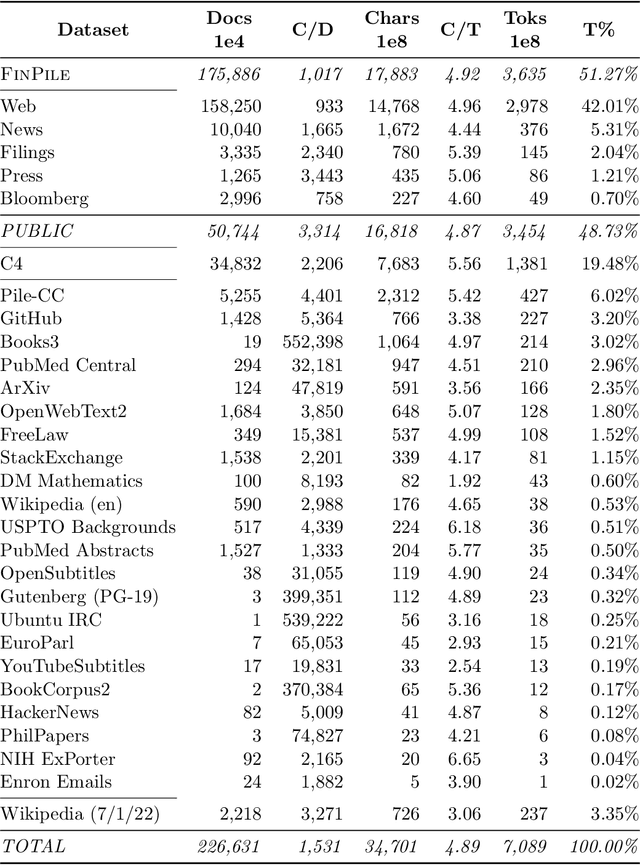
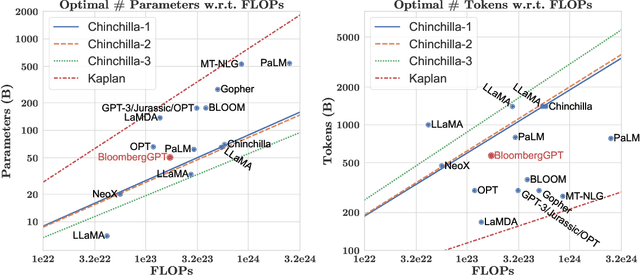
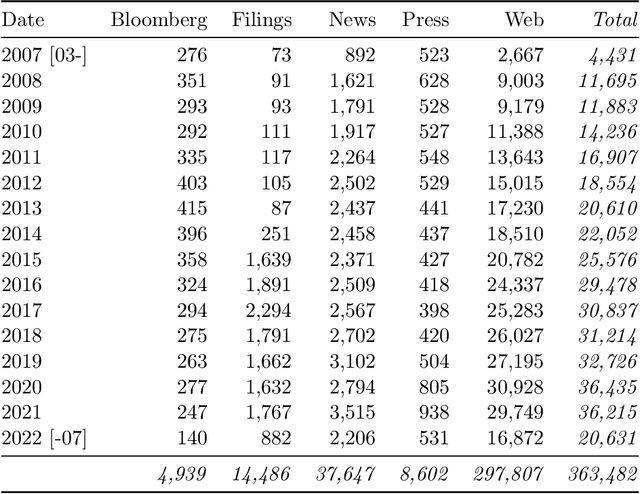
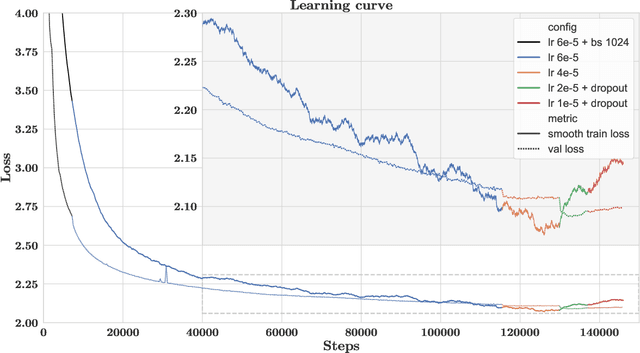
The use of NLP in the realm of financial technology is broad and complex, with applications ranging from sentiment analysis and named entity recognition to question answering. Large Language Models (LLMs) have been shown to be effective on a variety of tasks; however, no LLM specialized for the financial domain has been reported in literature. In this work, we present BloombergGPT, a 50 billion parameter language model that is trained on a wide range of financial data. We construct a 363 billion token dataset based on Bloomberg's extensive data sources, perhaps the largest domain-specific dataset yet, augmented with 345 billion tokens from general purpose datasets. We validate BloombergGPT on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that most accurately reflect our intended usage. Our mixed dataset training leads to a model that outperforms existing models on financial tasks by significant margins without sacrificing performance on general LLM benchmarks. Additionally, we explain our modeling choices, training process, and evaluation methodology. As a next step, we plan to release training logs (Chronicles) detailing our experience in training BloombergGPT.
Do Text-to-Text Multi-Task Learners Suffer from Task Conflict?
Dec 13, 2022



Traditional multi-task learning architectures train a single model across multiple tasks through a shared encoder followed by task-specific decoders. Learning these models often requires specialized training algorithms that address task-conflict in the shared parameter updates, which otherwise can lead to negative transfer. A new type of multi-task learning within NLP homogenizes multi-task architectures as a shared encoder and language model decoder, which does surprisingly well across a range of diverse tasks. Does this new architecture suffer from task-conflicts that require specialized training algorithms? We study how certain factors in the shift towards text-to-text models affects multi-task conflict and negative transfer, finding that both directional conflict and transfer are surprisingly constant across architectures.
Using Open-Ended Stressor Responses to Predict Depressive Symptoms across Demographics
Nov 15, 2022Stressors are related to depression, but this relationship is complex. We investigate the relationship between open-ended text responses about stressors and depressive symptoms across gender and racial/ethnic groups. First, we use topic models and other NLP tools to find thematic and vocabulary differences when reporting stressors across demographic groups. We train language models using self-reported stressors to predict depressive symptoms, finding a relationship between stressors and depression. Finally, we find that differences in stressors translate to downstream performance differences across demographic groups.
Zero-shot Cross-lingual Transfer is Under-specified Optimization
Jul 12, 2022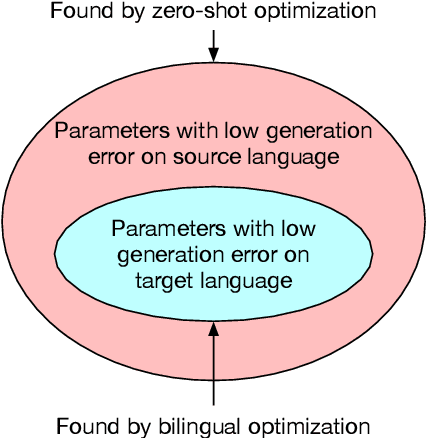
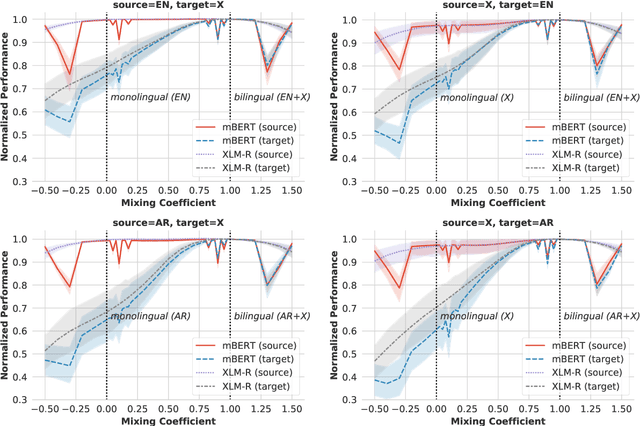
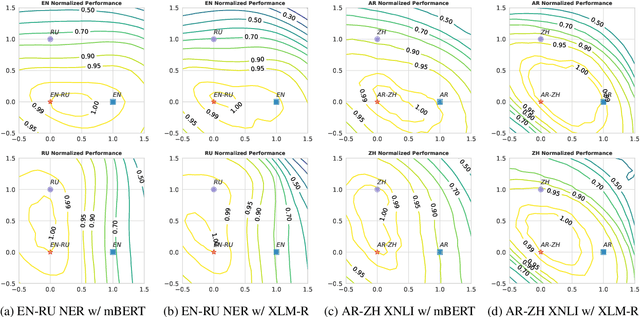
Pretrained multilingual encoders enable zero-shot cross-lingual transfer, but often produce unreliable models that exhibit high performance variance on the target language. We postulate that this high variance results from zero-shot cross-lingual transfer solving an under-specified optimization problem. We show that any linear-interpolated model between the source language monolingual model and source + target bilingual model has equally low source language generalization error, yet the target language generalization error reduces smoothly and linearly as we move from the monolingual to bilingual model, suggesting that the model struggles to identify good solutions for both source and target languages using the source language alone. Additionally, we show that zero-shot solution lies in non-flat region of target language error generalization surface, causing the high variance.
The Problem of Semantic Shift in Longitudinal Monitoring of Social Media: A Case Study on Mental Health During the COVID-19 Pandemic
Jun 22, 2022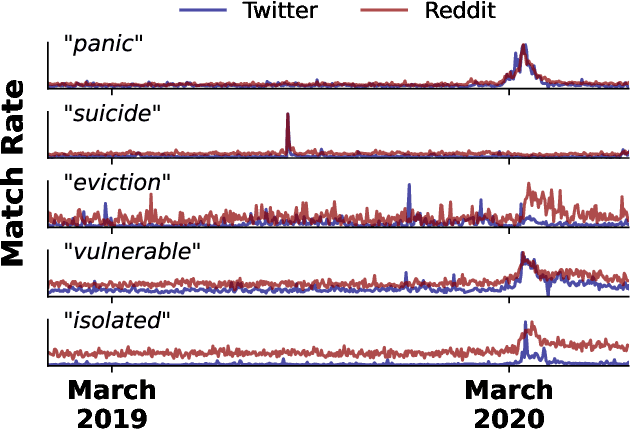
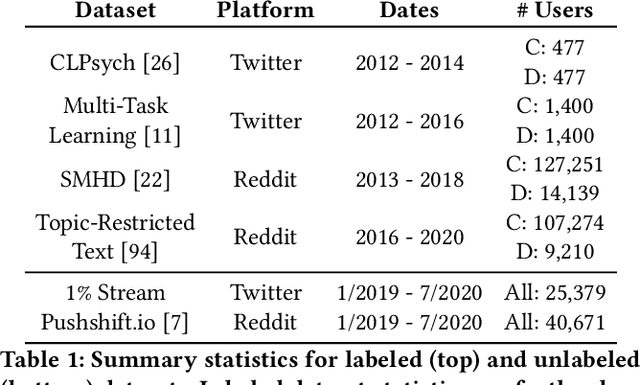
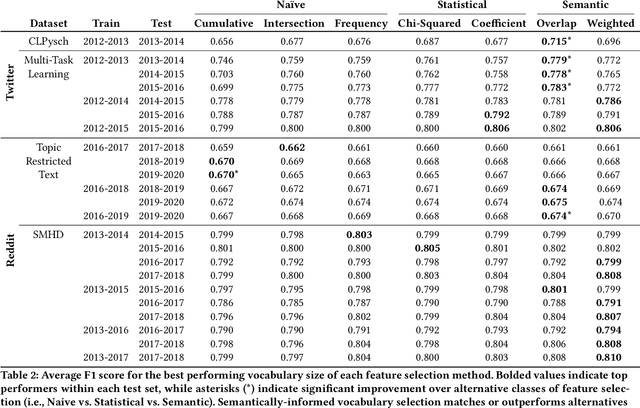
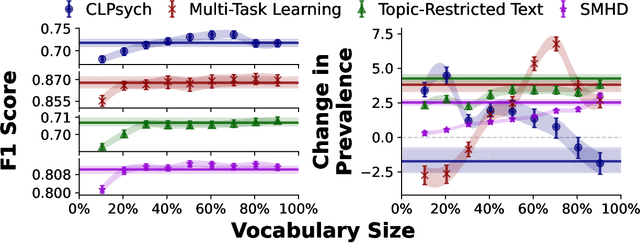
Social media allows researchers to track societal and cultural changes over time based on language analysis tools. Many of these tools rely on statistical algorithms which need to be tuned to specific types of language. Recent studies have shown the absence of appropriate tuning, specifically in the presence of semantic shift, can hinder robustness of the underlying methods. However, little is known about the practical effect this sensitivity may have on downstream longitudinal analyses. We explore this gap in the literature through a timely case study: understanding shifts in depression during the course of the COVID-19 pandemic. We find that inclusion of only a small number of semantically-unstable features can promote significant changes in longitudinal estimates of our target outcome. At the same time, we demonstrate that a recently-introduced method for measuring semantic shift may be used to proactively identify failure points of language-based models and, in turn, improve predictive generalization.