 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrdinal Regression for Difficulty Estimation of StepMania Levels
Jan 23, 2023StepMania is a popular open-source clone of a rhythm-based video game. As is common in popular games, there is a large number of community-designed levels. It is often difficult for players and level authors to determine the difficulty level of such community contributions. In this work, we formalize and analyze the difficulty prediction task on StepMania levels as an ordinal regression (OR) task. We standardize a more extensive and diverse selection of this data resulting in five data sets, two of which are extensions of previous work. We evaluate many competitive OR and non-OR models, demonstrating that neural network-based models significantly outperform the state of the art and that StepMania-level data makes for an excellent test bed for deep OR models. We conclude with a user experiment showing our trained models' superiority over human labeling.
Generalization Bounds for Inductive Matrix Completion in Low-noise Settings
Dec 16, 2022We study inductive matrix completion (matrix completion with side information) under an i.i.d. subgaussian noise assumption at a low noise regime, with uniform sampling of the entries. We obtain for the first time generalization bounds with the following three properties: (1) they scale like the standard deviation of the noise and in particular approach zero in the exact recovery case; (2) even in the presence of noise, they converge to zero when the sample size approaches infinity; and (3) for a fixed dimension of the side information, they only have a logarithmic dependence on the size of the matrix. Differently from many works in approximate recovery, we present results both for bounded Lipschitz losses and for the absolute loss, with the latter relying on Talagrand-type inequalities. The proofs create a bridge between two approaches to the theoretical analysis of matrix completion, since they consist in a combination of techniques from both the exact recovery literature and the approximate recovery literature.
* 30 Pages, 1 figure; Accepted for publication at AAAI 2023
Unsupervised Anomaly Detection for Auditing Data and Impact of Categorical Encodings
Oct 26, 2022



In this paper, we introduce the Vehicle Claims dataset, consisting of fraudulent insurance claims for automotive repairs. The data belongs to the more broad category of Auditing data, which includes also Journals and Network Intrusion data. Insurance claim data are distinctively different from other auditing data (such as network intrusion data) in their high number of categorical attributes. We tackle the common problem of missing benchmark datasets for anomaly detection: datasets are mostly confidential, and the public tabular datasets do not contain relevant and sufficient categorical attributes. Therefore, a large-sized dataset is created for this purpose and referred to as Vehicle Claims (VC) dataset. The dataset is evaluated on shallow and deep learning methods. Due to the introduction of categorical attributes, we encounter the challenge of encoding them for the large dataset. As One Hot encoding of high cardinal dataset invokes the "curse of dimensionality", we experiment with GEL encoding and embedding layer for representing categorical attributes. Our work compares competitive learning, reconstruction-error, density estimation and contrastive learning approaches for Label, One Hot, GEL encoding and embedding layer to handle categorical values.
Training Normalizing Flows from Dependent Data
Sep 29, 2022
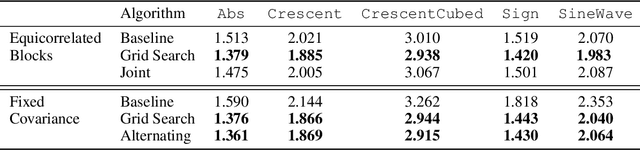
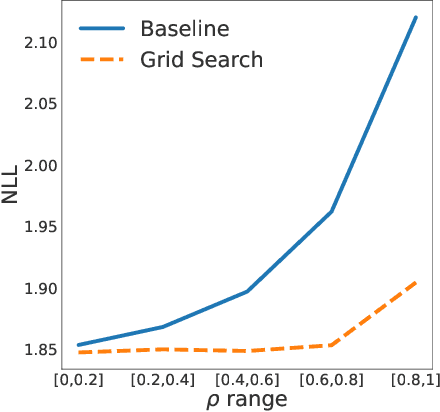

Normalizing flows are powerful non-parametric statistical models that function as a hybrid between density estimators and generative models. Current learning algorithms for normalizing flows assume that data points are sampled independently, an assumption that is frequently violated in practice, which may lead to erroneous density estimation and data generation. We propose a likelihood objective of normalizing flows incorporating dependencies between the data points, for which we derive a flexible and efficient learning algorithm suitable for different dependency structures. We show that respecting dependencies between observations can improve empirical results on both synthetic and real-world data.
Raising the Bar in Graph-level Anomaly Detection
May 27, 2022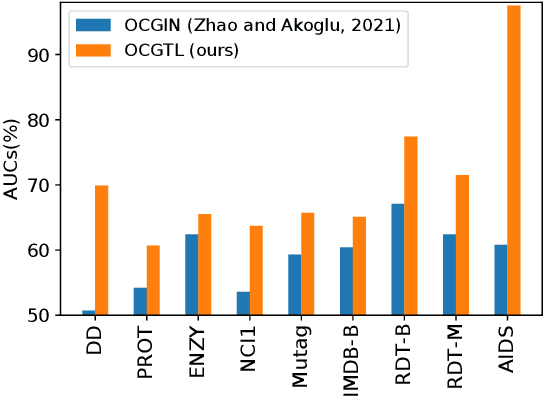
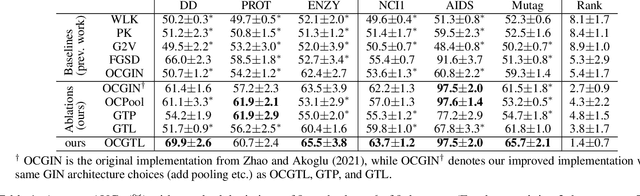
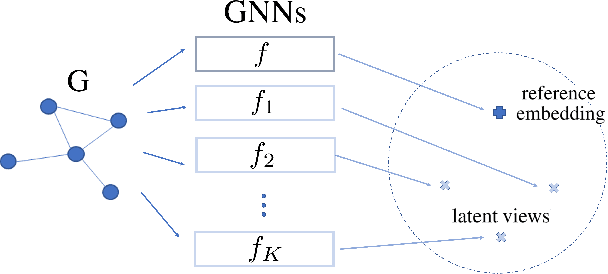

Graph-level anomaly detection has become a critical topic in diverse areas, such as financial fraud detection and detecting anomalous activities in social networks. While most research has focused on anomaly detection for visual data such as images, where high detection accuracies have been obtained, existing deep learning approaches for graphs currently show considerably worse performance. This paper raises the bar on graph-level anomaly detection, i.e., the task of detecting abnormal graphs in a set of graphs. By drawing on ideas from self-supervised learning and transformation learning, we present a new deep learning approach that significantly improves existing deep one-class approaches by fixing some of their known problems, including hypersphere collapse and performance flip. Experiments on nine real-world data sets involving nine techniques reveal that our method achieves an average performance improvement of 11.8% AUC compared to the best existing approach.
Exposing Outlier Exposure: What Can Be Learned From Few, One, and Zero Outlier Images
May 23, 2022

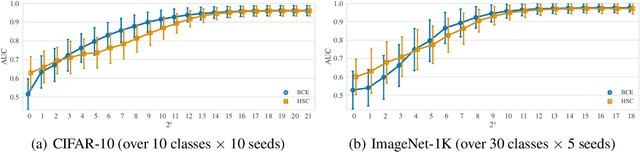
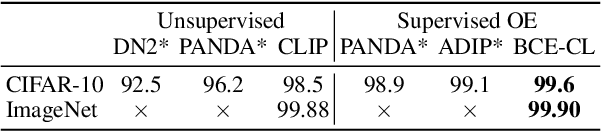
Traditionally anomaly detection (AD) is treated as an unsupervised problem utilizing only normal samples due to the intractability of characterizing everything that looks unlike the normal data. However, it has recently been found that unsupervised image anomaly detection can be drastically improved through the utilization of huge corpora of random images to represent anomalousness; a technique which is known as Outlier Exposure. In this paper we show that specialized AD learning methods seem actually superfluous and huge corpora of data expendable. For a common AD benchmark on ImageNet, standard classifiers and semi-supervised one-class methods trained to discern between normal samples and just a few random natural images are able to outperform the current state of the art in deep AD, and only one useful outlier sample is sufficient to perform competitively. We investigate this phenomenon and reveal that one-class methods are more robust towards the particular choice of training outliers. Furthermore, we find that a simple classifier based on representations from CLIP, a recent foundation model, achieves state-of-the-art results on CIFAR-10 and also outperforms all previous AD methods on ImageNet without any training samples (i.e., in a zero-shot setting).
Latent Outlier Exposure for Anomaly Detection with Contaminated Data
Feb 20, 2022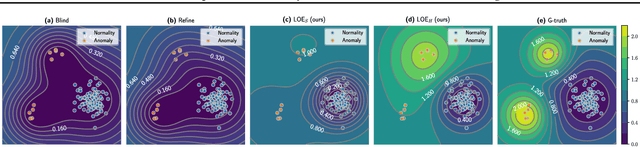
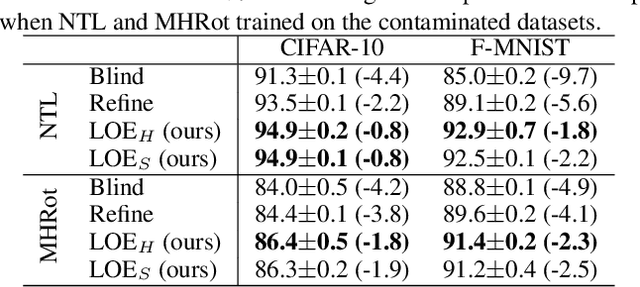
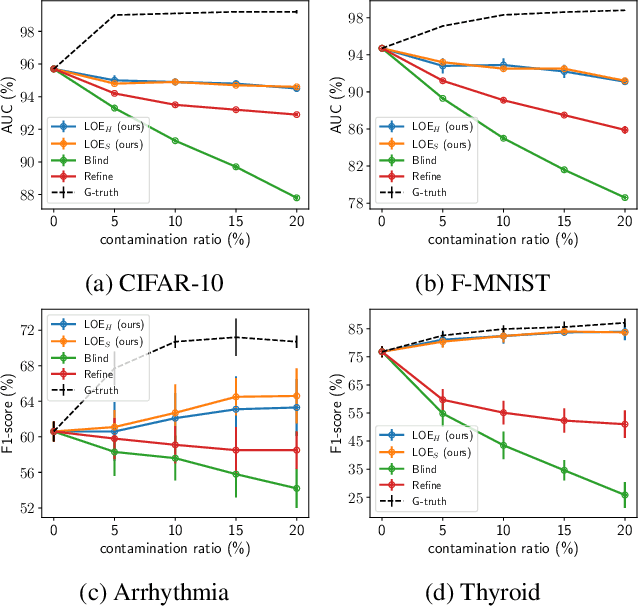
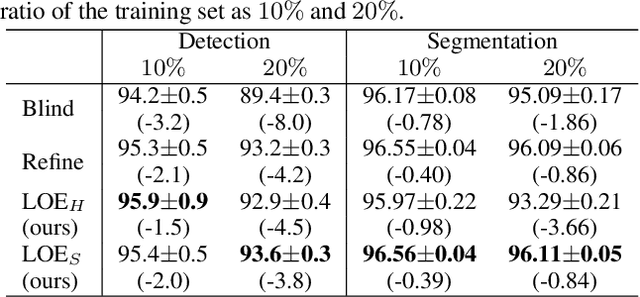
Anomaly detection aims at identifying data points that show systematic deviations from the majority of data in an unlabeled dataset. A common assumption is that clean training data (free of anomalies) is available, which is often violated in practice. We propose a strategy for training an anomaly detector in the presence of unlabeled anomalies that is compatible with a broad class of models. The idea is to jointly infer binary labels to each datum (normal vs. anomalous) while updating the model parameters. Inspired by outlier exposure (Hendrycks et al., 2018) that considers synthetically created, labeled anomalies, we thereby use a combination of two losses that share parameters: one for the normal and one for the anomalous data. We then iteratively proceed with block coordinate updates on the parameters and the most likely (latent) labels. Our experiments with several backbone models on three image datasets, 30 tabular data sets, and a video anomaly detection benchmark showed consistent and significant improvements over the baselines.
Detecting Anomalies within Time Series using Local Neural Transformations
Feb 08, 2022We develop a new method to detect anomalies within time series, which is essential in many application domains, reaching from self-driving cars, finance, and marketing to medical diagnosis and epidemiology. The method is based on self-supervised deep learning that has played a key role in facilitating deep anomaly detection on images, where powerful image transformations are available. However, such transformations are widely unavailable for time series. Addressing this, we develop Local Neural Transformations(LNT), a method learning local transformations of time series from data. The method produces an anomaly score for each time step and thus can be used to detect anomalies within time series. We prove in a theoretical analysis that our novel training objective is more suitable for transformation learning than previous deep Anomaly detection(AD) methods. Our experiments demonstrate that LNT can find anomalies in speech segments from the LibriSpeech data set and better detect interruptions to cyber-physical systems than previous work. Visualization of the learned transformations gives insight into the type of transformations that LNT learns.
Trainability for Universal GNNs Through Surgical Randomness
Dec 08, 2021

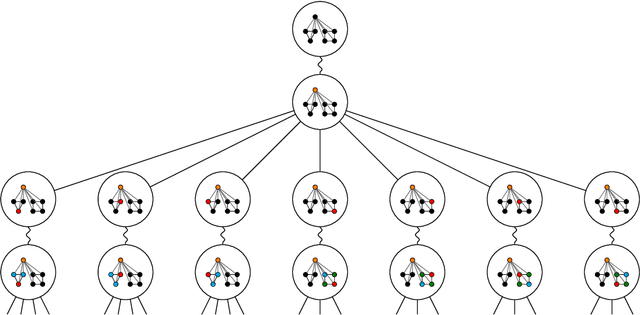
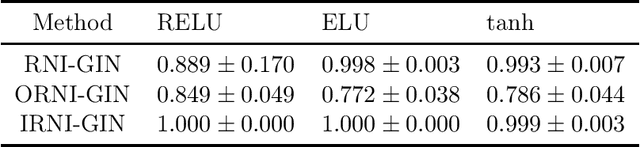
Message passing neural networks (MPNN) have provable limitations, which can be overcome by universal networks. However, universal networks are typically impractical. The only exception is random node initialization (RNI), a data augmentation method that results in provably universal networks. Unfortunately, RNI suffers from severe drawbacks such as slow convergence and high sensitivity to changes in hyperparameters. We transfer powerful techniques from the practical world of graph isomorphism testing to MPNNs, resolving these drawbacks. This culminates in individualization-refinement node initialization (IRNI). We replace the indiscriminate and haphazard randomness used in RNI by a surgical incision of only a few random bits at well-selected nodes. Our novel non-intrusive data-augmentation scheme maintains the networks' universality while resolving the trainability issues. We formally prove the claimed universality and corroborate experimentally -- on synthetic benchmarks sets previously explicitly designed for that purpose -- that IRNI overcomes the limitations of MPNNs. We also verify the practical efficacy of our approach on the standard benchmark data sets PROTEINS and NCI1.
Learning Interpretable Concept Groups in CNNs
Sep 21, 2021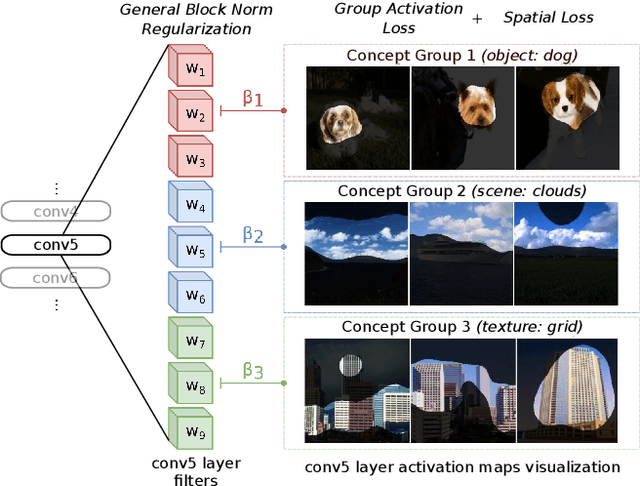
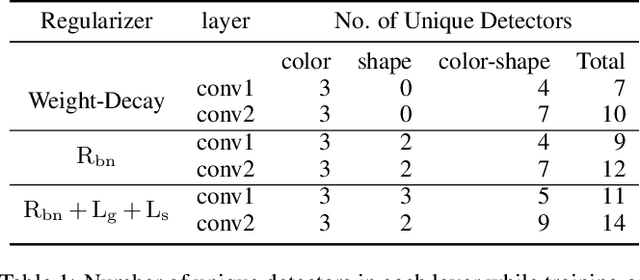
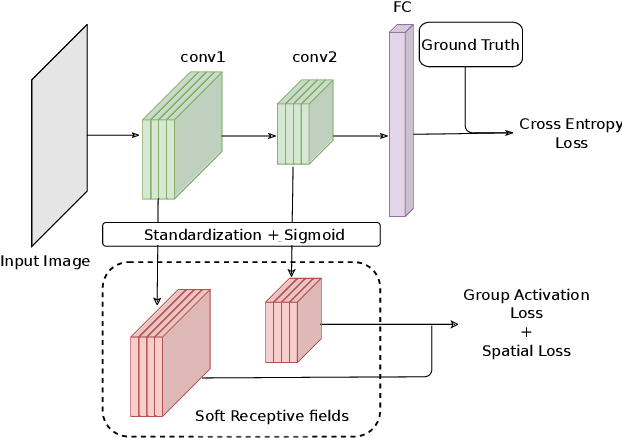
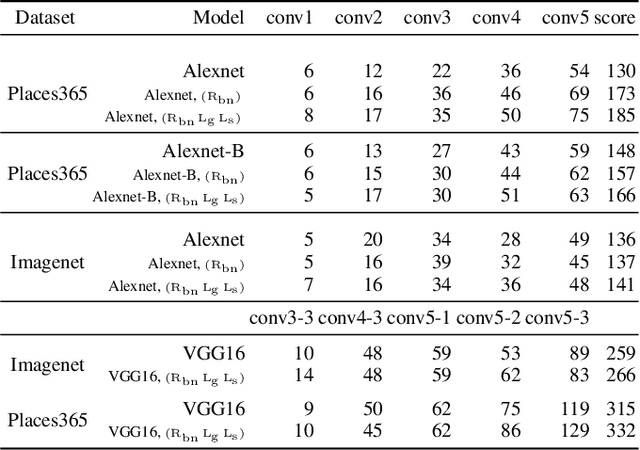
We propose a novel training methodology -- Concept Group Learning (CGL) -- that encourages training of interpretable CNN filters by partitioning filters in each layer into concept groups, each of which is trained to learn a single visual concept. We achieve this through a novel regularization strategy that forces filters in the same group to be active in similar image regions for a given layer. We additionally use a regularizer to encourage a sparse weighting of the concept groups in each layer so that a few concept groups can have greater importance than others. We quantitatively evaluate CGL's model interpretability using standard interpretability evaluation techniques and find that our method increases interpretability scores in most cases. Qualitatively we compare the image regions that are most active under filters learned using CGL versus filters learned without CGL and find that CGL activation regions more strongly concentrate around semantically relevant features.