 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable k-Means Clustering via Lightweight Coresets
Jun 06, 2018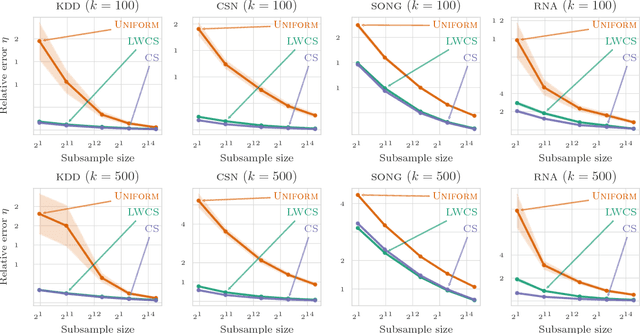
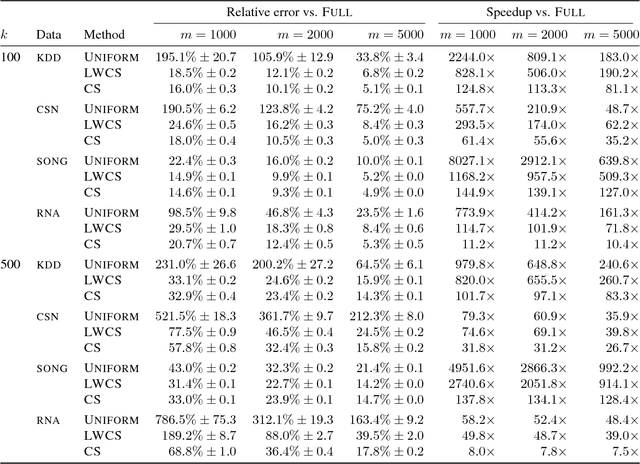
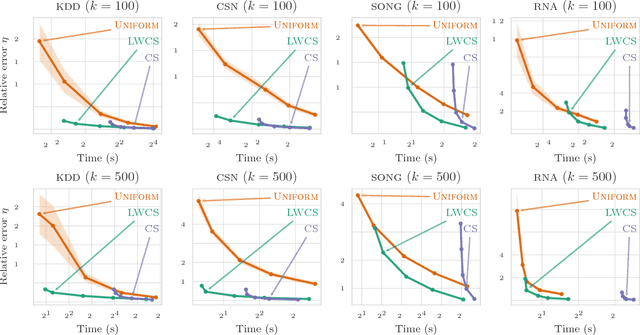
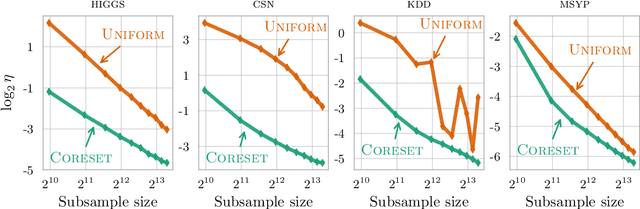
Coresets are compact representations of data sets such that models trained on a coreset are provably competitive with models trained on the full data set. As such, they have been successfully used to scale up clustering models to massive data sets. While existing approaches generally only allow for multiplicative approximation errors, we propose a novel notion of lightweight coresets that allows for both multiplicative and additive errors. We provide a single algorithm to construct lightweight coresets for k-means clustering as well as soft and hard Bregman clustering. The algorithm is substantially faster than existing constructions, embarrassingly parallel, and the resulting coresets are smaller. We further show that the proposed approach naturally generalizes to statistical k-means clustering and that, compared to existing results, it can be used to compute smaller summaries for empirical risk minimization. In extensive experiments, we demonstrate that the proposed algorithm outperforms existing data summarization strategies in practice.
One-Shot Coresets: The Case of k-Clustering
Feb 20, 2018Scaling clustering algorithms to massive data sets is a challenging task. Recently, several successful approaches based on data summarization methods, such as coresets and sketches, were proposed. While these techniques provide provably good and small summaries, they are inherently problem dependent - the practitioner has to commit to a fixed clustering objective before even exploring the data. However, can one construct small data summaries for a wide range of clustering problems simultaneously? In this work, we affirmatively answer this question by proposing an efficient algorithm that constructs such one-shot summaries for k-clustering problems while retaining strong theoretical guarantees.
Training Gaussian Mixture Models at Scale via Coresets
Jan 15, 2018
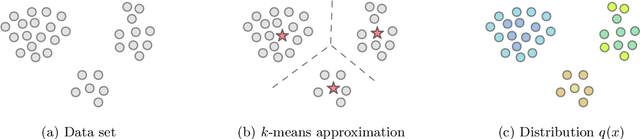
How can we train a statistical mixture model on a massive data set? In this work we show how to construct coresets for mixtures of Gaussians. A coreset is a weighted subset of the data, which guarantees that models fitting the coreset also provide a good fit for the original data set. We show that, perhaps surprisingly, Gaussian mixtures admit coresets of size polynomial in dimension and the number of mixture components, while being independent of the data set size. Hence, one can harness computationally intensive algorithms to compute a good approximation on a significantly smaller data set. More importantly, such coresets can be efficiently constructed both in distributed and streaming settings and do not impose restrictions on the data generating process. Our results rely on a novel reduction of statistical estimation to problems in computational geometry and new combinatorial complexity results for mixtures of Gaussians. Empirical evaluation on several real-world datasets suggests that our coreset-based approach enables significant reduction in training-time with negligible approximation error.
Stochastic Submodular Maximization: The Case of Coverage Functions
Nov 05, 2017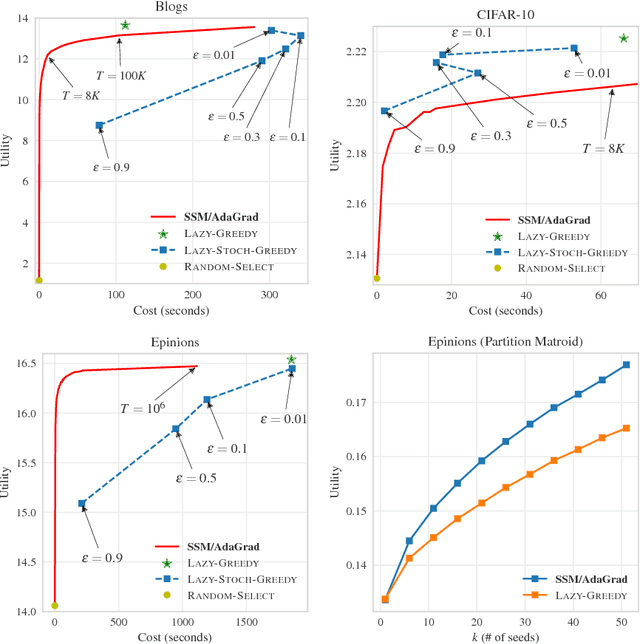
Stochastic optimization of continuous objectives is at the heart of modern machine learning. However, many important problems are of discrete nature and often involve submodular objectives. We seek to unleash the power of stochastic continuous optimization, namely stochastic gradient descent and its variants, to such discrete problems. We first introduce the problem of stochastic submodular optimization, where one needs to optimize a submodular objective which is given as an expectation. Our model captures situations where the discrete objective arises as an empirical risk (e.g., in the case of exemplar-based clustering), or is given as an explicit stochastic model (e.g., in the case of influence maximization in social networks). By exploiting that common extensions act linearly on the class of submodular functions, we employ projected stochastic gradient ascent and its variants in the continuous domain, and perform rounding to obtain discrete solutions. We focus on the rich and widely used family of weighted coverage functions. We show that our approach yields solutions that are guaranteed to match the optimal approximation guarantees, while reducing the computational cost by several orders of magnitude, as we demonstrate empirically.
Practical Coreset Constructions for Machine Learning
Jun 04, 2017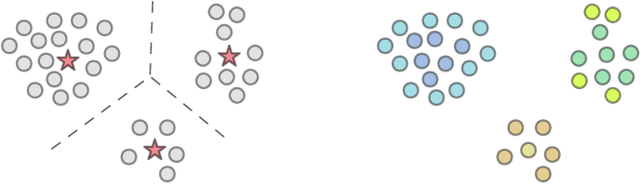
We investigate coresets - succinct, small summaries of large data sets - so that solutions found on the summary are provably competitive with solution found on the full data set. We provide an overview over the state-of-the-art in coreset construction for machine learning. In Section 2, we present both the intuition behind and a theoretically sound framework to construct coresets for general problems and apply it to $k$-means clustering. In Section 3 we summarize existing coreset construction algorithms for a variety of machine learning problems such as maximum likelihood estimation of mixture models, Bayesian non-parametric models, principal component analysis, regression and general empirical risk minimization.
Uniform Deviation Bounds for Unbounded Loss Functions like k-Means
Feb 27, 2017Uniform deviation bounds limit the difference between a model's expected loss and its loss on an empirical sample uniformly for all models in a learning problem. As such, they are a critical component to empirical risk minimization. In this paper, we provide a novel framework to obtain uniform deviation bounds for loss functions which are *unbounded*. In our main application, this allows us to obtain bounds for $k$-Means clustering under weak assumptions on the underlying distribution. If the fourth moment is bounded, we prove a rate of $\mathcal{O}\left(m^{-\frac12}\right)$ compared to the previously known $\mathcal{O}\left(m^{-\frac14}\right)$ rate. Furthermore, we show that the rate also depends on the kurtosis - the normalized fourth moment which measures the "tailedness" of a distribution. We further provide improved rates under progressively stronger assumptions, namely, bounded higher moments, subgaussianity and bounded support.
Horizontally Scalable Submodular Maximization
May 31, 2016
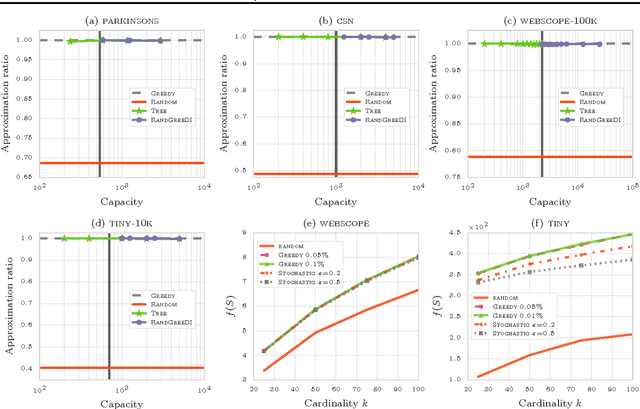
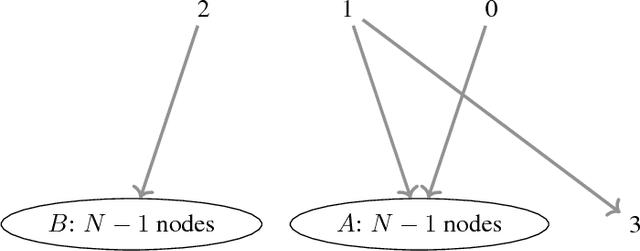
A variety of large-scale machine learning problems can be cast as instances of constrained submodular maximization. Existing approaches for distributed submodular maximization have a critical drawback: The capacity - number of instances that can fit in memory - must grow with the data set size. In practice, while one can provision many machines, the capacity of each machine is limited by physical constraints. We propose a truly scalable approach for distributed submodular maximization under fixed capacity. The proposed framework applies to a broad class of algorithms and constraints and provides theoretical guarantees on the approximation factor for any available capacity. We empirically evaluate the proposed algorithm on a variety of data sets and demonstrate that it achieves performance competitive with the centralized greedy solution.
Tradeoffs for Space, Time, Data and Risk in Unsupervised Learning
May 02, 2016
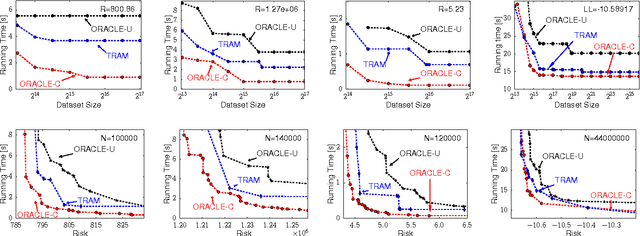
Faced with massive data, is it possible to trade off (statistical) risk, and (computational) space and time? This challenge lies at the heart of large-scale machine learning. Using k-means clustering as a prototypical unsupervised learning problem, we show how we can strategically summarize the data (control space) in order to trade off risk and time when data is generated by a probabilistic model. Our summarization is based on coreset constructions from computational geometry. We also develop an algorithm, TRAM, to navigate the space/time/data/risk tradeoff in practice. In particular, we show that for a fixed risk (or data size), as the data size increases (resp. risk increases) the running time of TRAM decreases. Our extensive experiments on real data sets demonstrate the existence and practical utility of such tradeoffs, not only for k-means but also for Gaussian Mixture Models.
Linear-time Outlier Detection via Sensitivity
May 02, 2016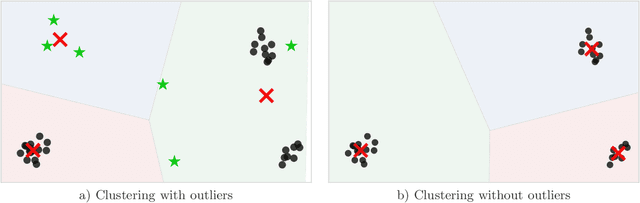
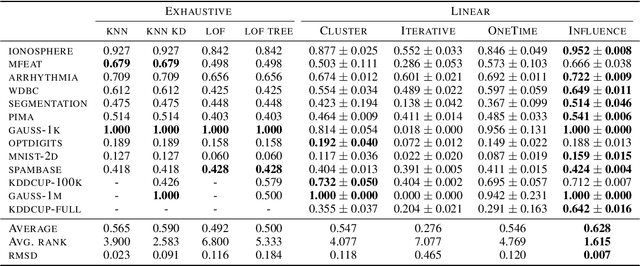

Outliers are ubiquitous in modern data sets. Distance-based techniques are a popular non-parametric approach to outlier detection as they require no prior assumptions on the data generating distribution and are simple to implement. Scaling these techniques to massive data sets without sacrificing accuracy is a challenging task. We propose a novel algorithm based on the intuition that outliers have a significant influence on the quality of divergence-based clustering solutions. We propose sensitivity - the worst-case impact of a data point on the clustering objective - as a measure of outlierness. We then prove that influence, a (non-trivial) upper-bound on the sensitivity, can be computed by a simple linear time algorithm. To scale beyond a single machine, we propose a communication efficient distributed algorithm. In an extensive experimental evaluation, we demonstrate the effectiveness and establish the statistical significance of the proposed approach. In particular, it outperforms the most popular distance-based approaches while being several orders of magnitude faster.
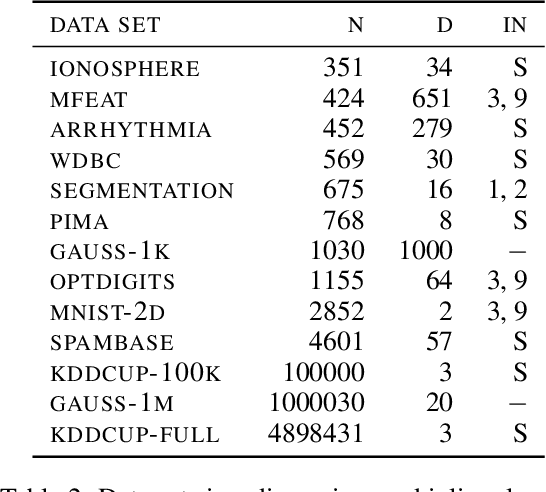
Strong Coresets for Hard and Soft Bregman Clustering with Applications to Exponential Family Mixtures
May 02, 2016
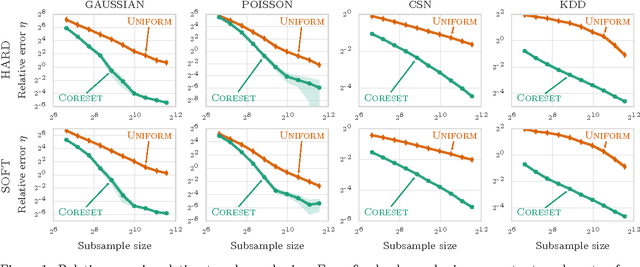
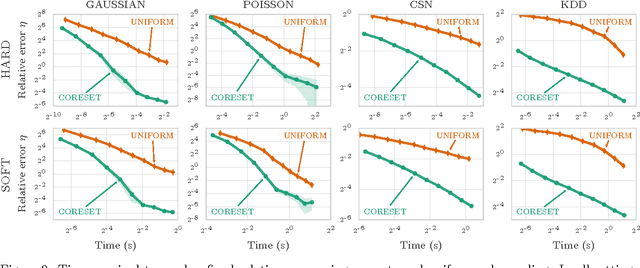

Coresets are efficient representations of data sets such that models trained on the coreset are provably competitive with models trained on the original data set. As such, they have been successfully used to scale up clustering models such as K-Means and Gaussian mixture models to massive data sets. However, until now, the algorithms and the corresponding theory were usually specific to each clustering problem. We propose a single, practical algorithm to construct strong coresets for a large class of hard and soft clustering problems based on Bregman divergences. This class includes hard clustering with popular distortion measures such as the Squared Euclidean distance, the Mahalanobis distance, KL-divergence and Itakura-Saito distance. The corresponding soft clustering problems are directly related to popular mixture models due to a dual relationship between Bregman divergences and Exponential family distributions. Our theoretical results further imply a randomized polynomial-time approximation scheme for hard clustering. We demonstrate the practicality of the proposed algorithm in an empirical evaluation.