 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-WGAN: A Gradient-Sanitized Approach for Learning Differentially Private Generators
Jun 15, 2020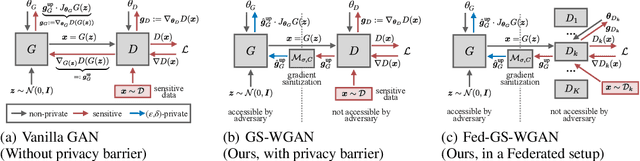
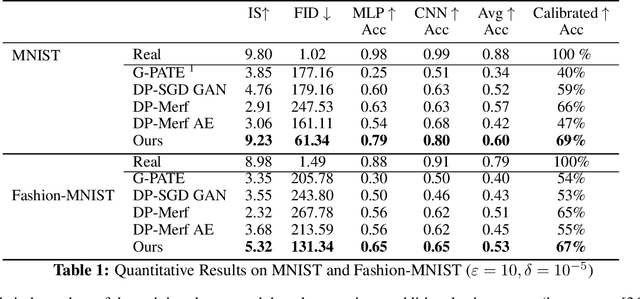
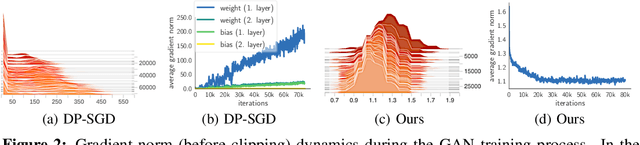
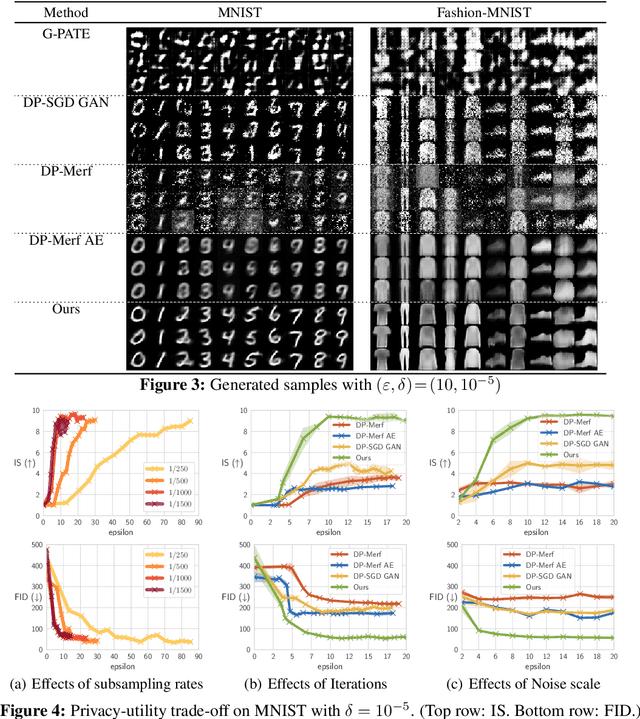
The wide-spread availability of rich data has fueled the growth of machine learning applications in numerous domains. However, growth in domains with highly-sensitive data (e.g., medical) is largely hindered as the private nature of data prohibits it from being shared. To this end, we propose Gradient-sanitized Wasserstein Generative Adversarial Networks (GS-WGAN), which allows releasing a sanitized form of the sensitive data with rigorous privacy guarantees. In contrast to prior work, our approach is able to distort gradient information more precisely, and thereby enabling training deeper models which generate more informative samples. Moreover, our formulation naturally allows for training GANs in both centralized and federated (i.e., decentralized) data scenarios. Through extensive experiments, we find our approach consistently outperforms state-of-the-art approaches across multiple metrics (e.g., sample quality) and datasets.
InfoScrub: Towards Attribute Privacy by Targeted Obfuscation
May 20, 2020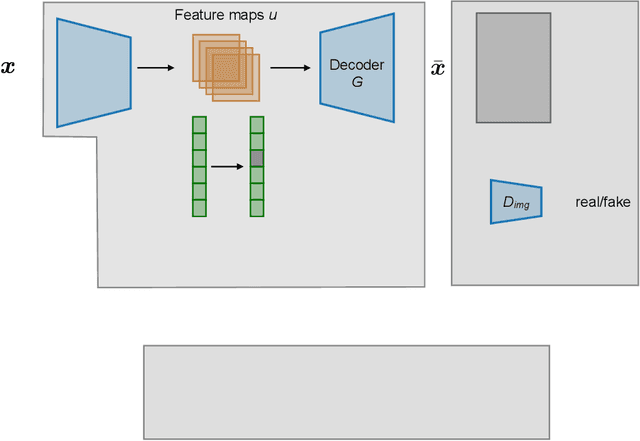

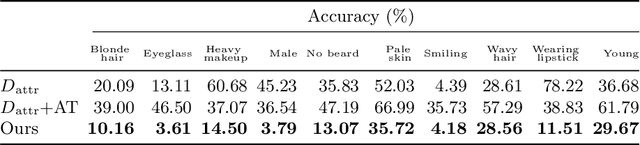
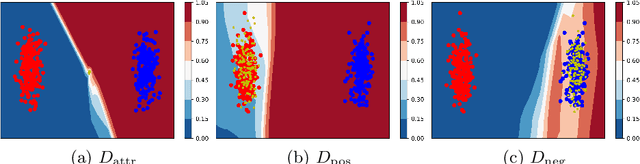
Personal photos of individuals when shared online, apart from exhibiting a myriad of memorable details, also reveals a wide range of private information and potentially entails privacy risks (e.g., online harassment, tracking). To mitigate such risks, it is crucial to study techniques that allow individuals to limit the private information leaked in visual data. We tackle this problem in a novel image obfuscation framework: to maximize entropy on inferences over targeted privacy attributes, while retaining image fidelity. We approach the problem based on an encoder-decoder style architecture, with two key novelties: (a) introducing a discriminator to perform bi-directional translation simultaneously from multiple unpaired domains; (b) predicting an image interpolation which maximizes uncertainty over a target set of attributes. We find our approach generates obfuscated images faithful to the original input images, and additionally increase uncertainty by 6.2$\times$ (or up to 0.85 bits) over the non-obfuscated counterparts.
Inclusive GAN: Improving Data and Minority Coverage in Generative Models
Apr 12, 2020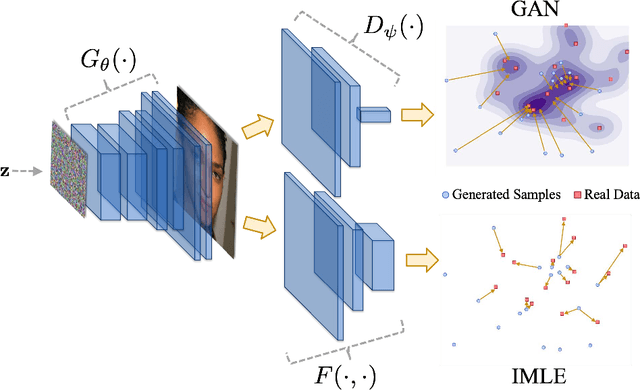

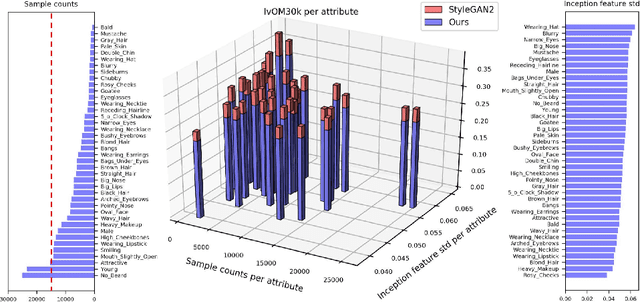
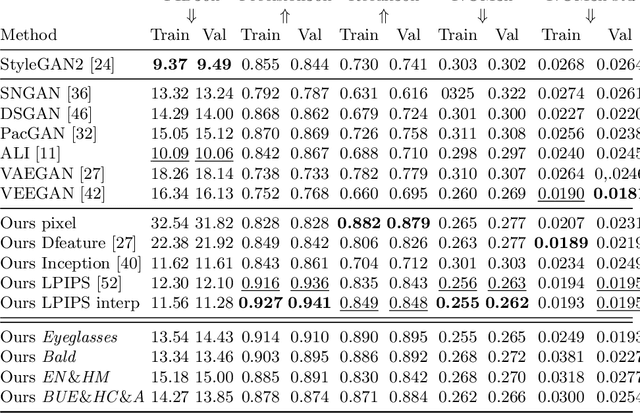
Generative Adversarial Networks (GANs) have brought about rapid progress towards generating photorealistic images. Yet the equitable allocation of their modeling capacity among subgroups has received less attention, which could lead to potential biases against underrepresented minorities if left uncontrolled. In this work, we first formalize the problem of minority inclusion as one of data coverage, and then propose to improve data coverage by harmonizing adversarial training with reconstructive generation. The experiments show that our method outperforms the existing state-of-the-art methods in terms of data coverage on both seen and unseen data. We develop an extension that allows explicit control over the minority subgroups that the model should ensure to include, and validate its effectiveness at little compromise from the overall performance on the entire dataset. Code, models, and supplemental videos are available at GitHub.
Normalizing Flows with Multi-Scale Autoregressive Priors
Apr 08, 2020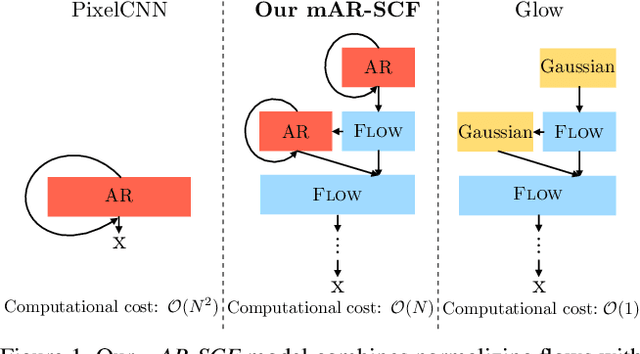
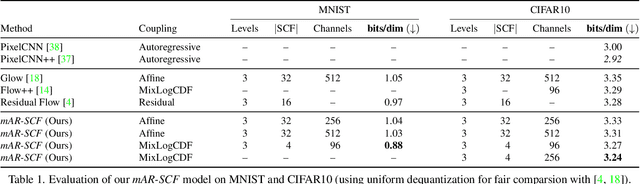
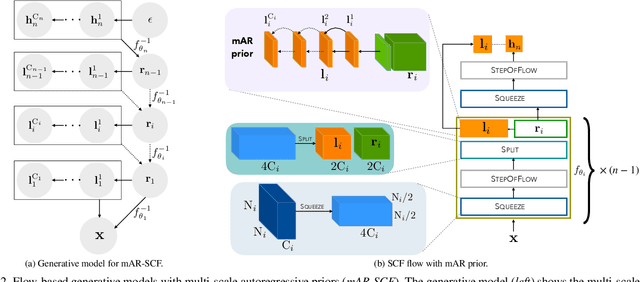
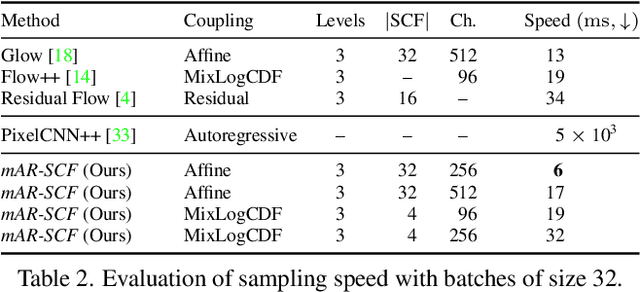
Flow-based generative models are an important class of exact inference models that admit efficient inference and sampling for image synthesis. Owing to the efficiency constraints on the design of the flow layers, e.g. split coupling flow layers in which approximately half the pixels do not undergo further transformations, they have limited expressiveness for modeling long-range data dependencies compared to autoregressive models that rely on conditional pixel-wise generation. In this work, we improve the representational power of flow-based models by introducing channel-wise dependencies in their latent space through multi-scale autoregressive priors (mAR). Our mAR prior for models with split coupling flow layers (mAR-SCF) can better capture dependencies in complex multimodal data. The resulting model achieves state-of-the-art density estimation results on MNIST, CIFAR-10, and ImageNet. Furthermore, we show that mAR-SCF allows for improved image generation quality, with gains in FID and Inception scores compared to state-of-the-art flow-based models.
Long-Tailed Recognition Using Class-Balanced Experts
Apr 07, 2020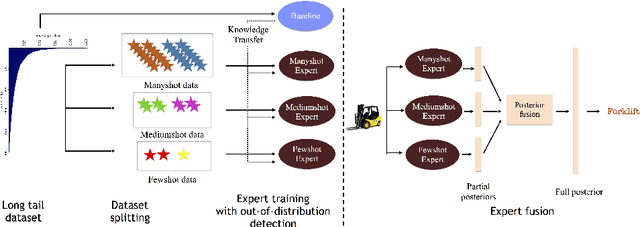
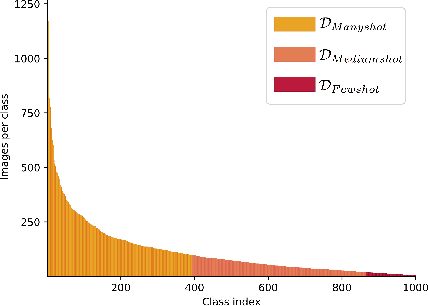

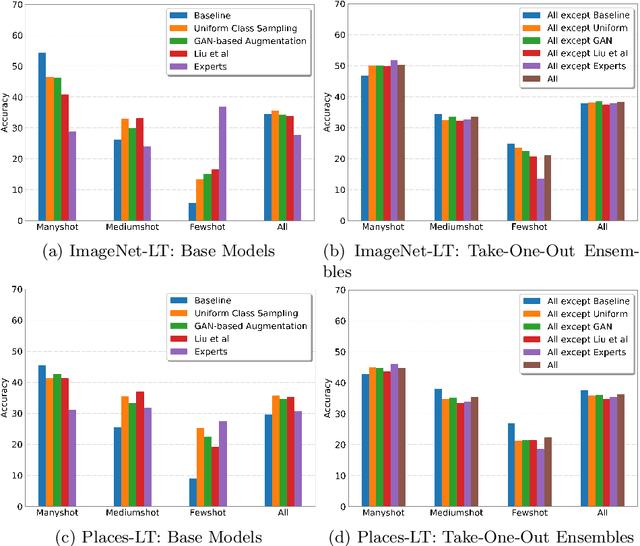
Classic deep learning methods achieve impressive results in image recognition over large-scale artificially-balanced datasets. However, real-world datasets exhibit highly class-imbalanced distributions. In this work we address the problem of long tail recognition wherein the training set is highly imbalanced and the test set is kept balanced. The key challenges faced by any long tail recognition technique are relative imbalance amongst the classes and data scarcity or unseen concepts for mediumshot or fewshot classes. Existing techniques rely on data-resampling, cost sensitive learning, online hard example mining, reshaping the loss objective and complex memory based models to address this problem. We instead propose an ensemble of experts technique that decomposes the imbalanced problem into multiple balanced classification problems which are more tractable. Our ensemble of experts reaches close to state-of-the-art results and an extended ensemble establishes new state-of-the-art on two benchmarks for long tail recognition. We conduct numerous experiments to analyse the performance of the ensemble, and show that in modern datasets relative imbalance is a harder problem than data scarcity.
Towards Causal VQA: Revealing and Reducing Spurious Correlations by Invariant and Covariant Semantic Editing
Dec 22, 2019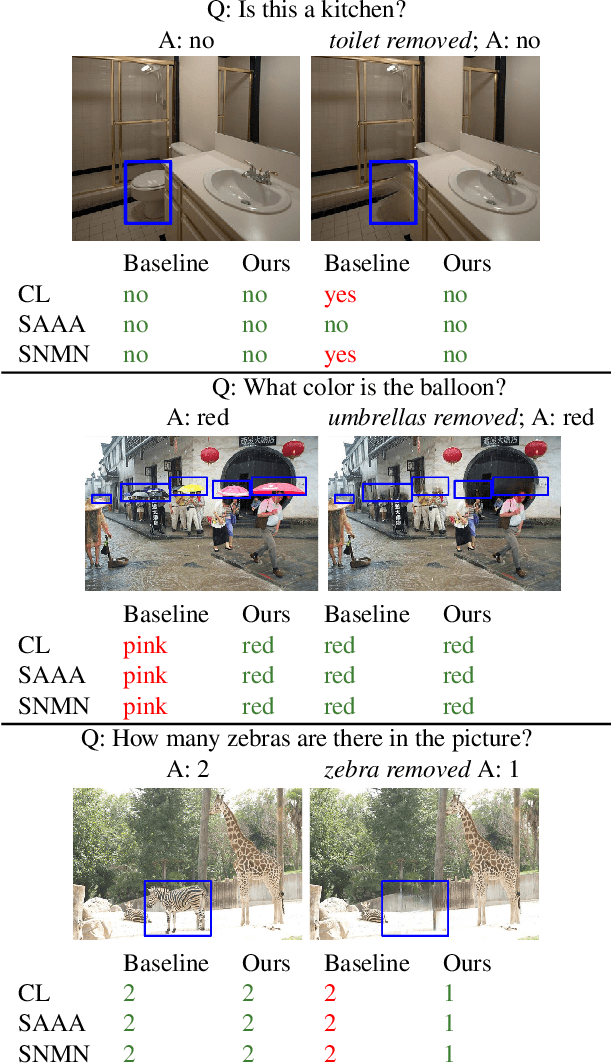

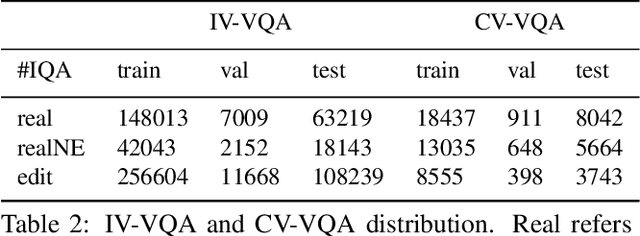

Despite significant success in Visual Question Answering (VQA), VQA models have been shown to be notoriously brittle to linguistic variations in the questions. Due to deficiencies in models and datasets, today's models often rely on correlations rather than predictions that are causal w.r.t. data. In this paper, we propose a novel way to analyze and measure the robustness of the state of the art models w.r.t semantic visual variations as well as propose ways to make models more robust against spurious correlations. Our method performs automated semantic image manipulations and tests for consistency in model predictions to quantify the model robustness as well as generate synthetic data to counter these problems. We perform our analysis on three diverse, state of the art VQA models and diverse question types with a particular focus on challenging counting questions. In addition, we show that models can be made significantly more robust against inconsistent predictions using our edited data. Finally, we show that results also translate to real-world error cases of state of the art models, which results in improved overall performance
Segmentations-Leak: Membership Inference Attacks and Defenses in Semantic Image Segmentation
Dec 20, 2019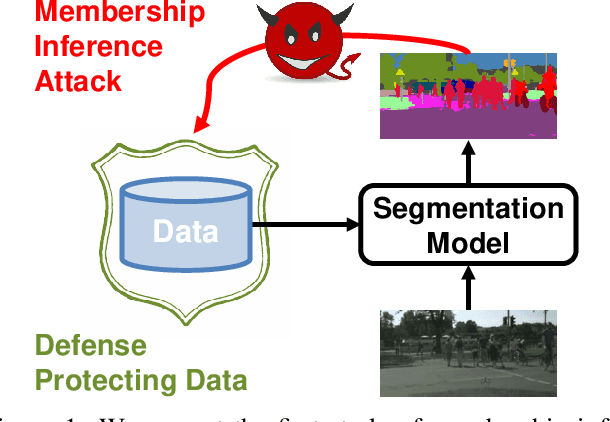

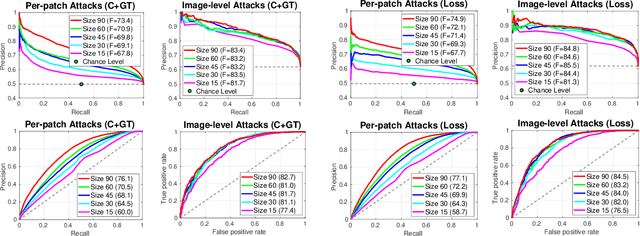
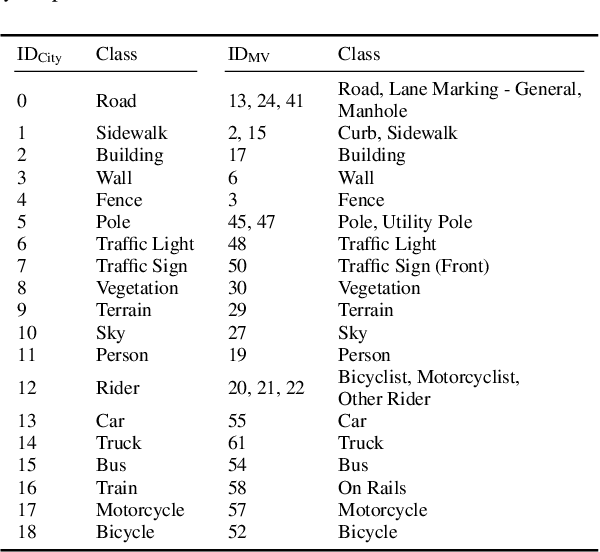
Today's success of state of the art methods for semantic segmentation is driven by large datasets. Data is considered an important asset that needs to be protected, as the collection and annotation of such datasets comes at significant efforts and associated costs. In addition, visual data might contain private or sensitive information, that makes it equally unsuited for public release. Unfortunately, recent work on membership inference in the broader area of adversarial machine learning and inference attacks on machine learning models has shown that even black box classifiers leak information on the dataset that they were trained on. We present the first attacks and defenses for complex, state of the art models for semantic segmentation. In order to mitigate the associated risks, we also study a series of defenses against such membership inference attacks and find effective counter measures against the existing risks. Finally, we extensively evaluate our attacks and defenses on a range of relevant real-world datasets: Cityscapes, BDD100K, and Mapillary Vistas.
"Best-of-Many-Samples" Distribution Matching
Sep 27, 2019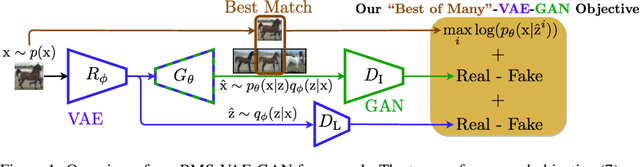
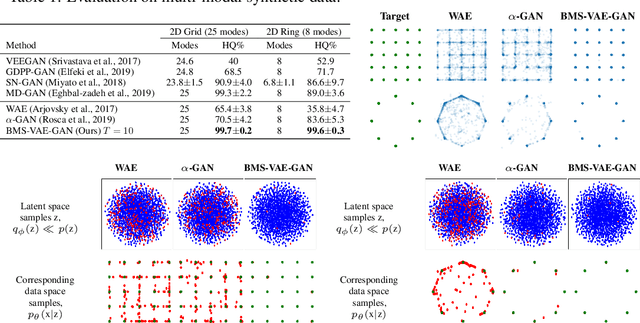


Generative Adversarial Networks (GANs) can achieve state-of-the-art sample quality in generative modelling tasks but suffer from the mode collapse problem. Variational Autoencoders (VAE) on the other hand explicitly maximize a reconstruction-based data log-likelihood forcing it to cover all modes, but suffer from poorer sample quality. Recent works have proposed hybrid VAE-GAN frameworks which integrate a GAN-based synthetic likelihood to the VAE objective to address both the mode collapse and sample quality issues, with limited success. This is because the VAE objective forces a trade-off between the data log-likelihood and divergence to the latent prior. The synthetic likelihood ratio term also shows instability during training. We propose a novel objective with a "Best-of-Many-Samples" reconstruction cost and a stable direct estimate of the synthetic likelihood. This enables our hybrid VAE-GAN framework to achieve high data log-likelihood and low divergence to the latent prior at the same time and shows significant improvement over both hybrid VAE-GANS and plain GANs in mode coverage and quality.
GAN-Leaks: A Taxonomy of Membership Inference Attacks against GANs
Sep 09, 2019
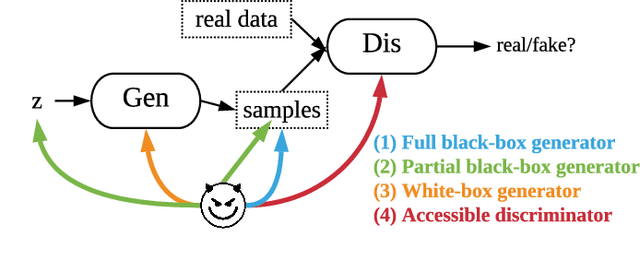

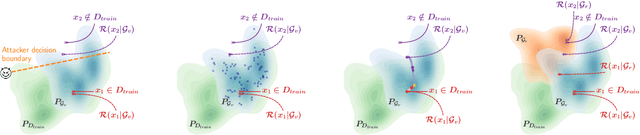
In recent years, the success of deep learning has carried over from discriminative models to generative models. In particular, generative adversarial networks (GANs) have facilitated a new level of performance ranging from media manipulation to dataset re-generation. Despite the success, the potential risks of privacy breach stemming from GANs are less well explored. In this paper, we focus on membership inference attack against GANs that has the potential to reveal information about victim models' training data. Specifically, we present the first taxonomy of membership inference attacks, which encompasses not only existing attacks but also our novel ones. We also propose the first generic attack model that can be instantiated in various settings according to adversary's knowledge about the victim model. We complement our systematic analysis of attack vectors with a comprehensive experimental study, that investigates the effectiveness of these attacks w.r.t. model type, training configurations, and attack type across three diverse application scenarios ranging from images, over medical data to location data. We show consistent effectiveness in all the setups, which bridges the assumption gap and performance gap in previous study with a complete spectrum of performance across settings. We conclusively remind users to think over before publicizing any part of their models.
WhiteNet: Phishing Website Detection by Visual Whitelists
Sep 01, 2019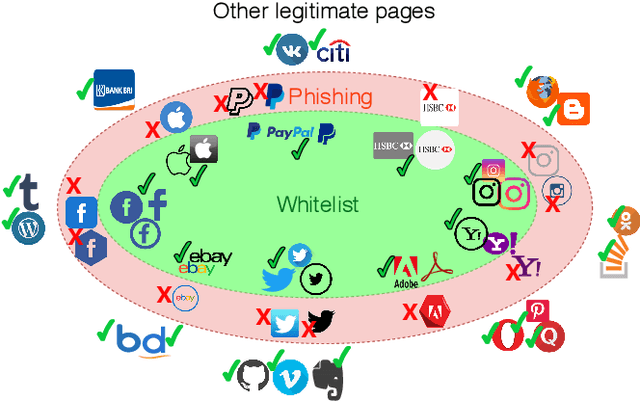
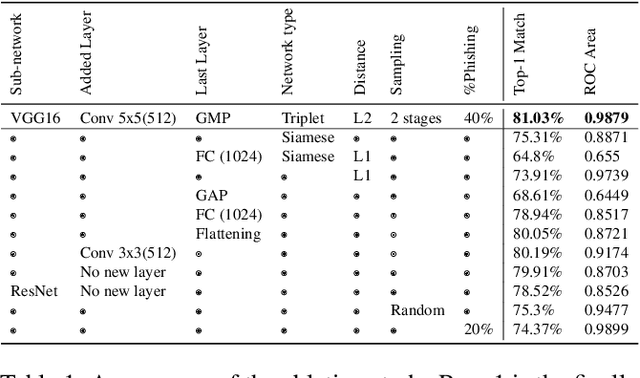
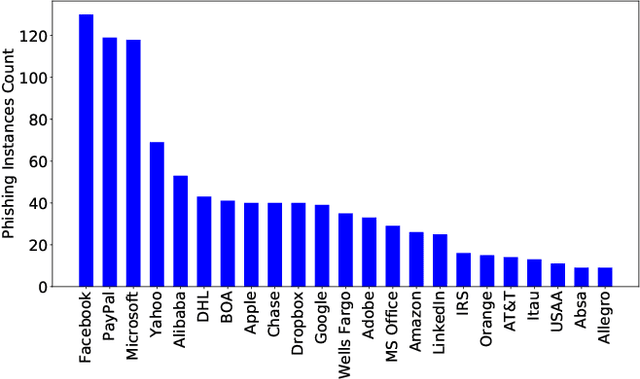

Phishing websites aiming at stealing users' information by claiming fake identities and impersonating visual profiles belonging to trustworthy websites are still a major threat for today's Internet thread. Therefore, detecting visual similarity to a set of whitelisted legitimate websites was often used in phishing detection literature. Despite numerous previous efforts, these methods are either evaluated on datasets with severe limitations or assume a close copy of the targeted legitimate webpages, which makes them easy to be bypassed. This paper contributes WhiteNet, a new similarity-based phishing detection framework, i.e., a triplet network with three shared Convolutional Neural Networks (CNNs). We furthermore present WhitePhish, an improved dataset to evaluate WhiteNet and other frameworks in an ecologically valid manner. WhiteNet learns profiles for websites in order to detect zero-day phishing websites and achieves an area of 0.9879 under the ROC curve of legitimate versus phishing binary classification which outperforms re-implemented state-of-the-art methods. WhitePhish is an extended dataset based on an in-depth analysis of whitelist sources and dataset characteristics.