 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopy First, Translate Later: Interpreting Translation Dynamics in Multilingual Pretraining
Apr 19, 2026Large language models exhibit impressive cross-lingual capabilities. However, prior work analyzes this phenomenon through isolated factors and at sparse points during training, limiting our understanding of how cross-lingual generalization emerges--particularly in the early phases of learning. To study the early trajectory of linguistic and translation capabilities, we pretrain a multilingual 1.7B model on nine diverse languages, capturing checkpoints at a much finer granularity. We further introduce a novel word-level translation dataset and trace how translation develops over training through behavioral analyses, model-component analysis, and parameter-based ablations. We find that the model quickly acquires basic linguistic capabilities in parallel with token-level copying, while translation develops in two distinct phases: an initial phase dominated by copying and surface-level similarities, and a second phase in which more generalizing translation mechanisms are developed while copying is refined. Together, these findings provide a fine-grained view of how cross-lingual generalization develops during multilingual pretraining.
Conflicting Biases at the Edge of Stability: Norm versus Sharpness Regularization
May 27, 2025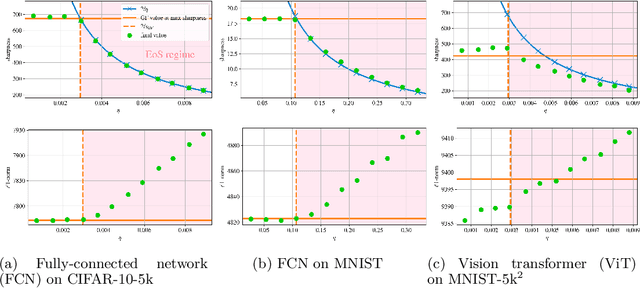
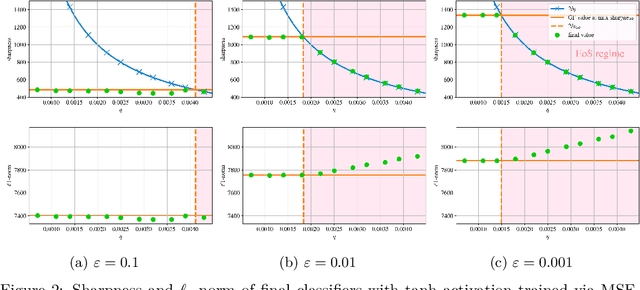
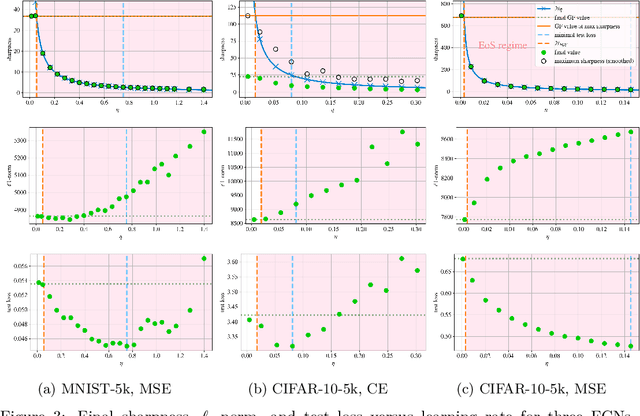
A widely believed explanation for the remarkable generalization capacities of overparameterized neural networks is that the optimization algorithms used for training induce an implicit bias towards benign solutions. To grasp this theoretically, recent works examine gradient descent and its variants in simplified training settings, often assuming vanishing learning rates. These studies reveal various forms of implicit regularization, such as $\ell_1$-norm minimizing parameters in regression and max-margin solutions in classification. Concurrently, empirical findings show that moderate to large learning rates exceeding standard stability thresholds lead to faster, albeit oscillatory, convergence in the so-called Edge-of-Stability regime, and induce an implicit bias towards minima of low sharpness (norm of training loss Hessian). In this work, we argue that a comprehensive understanding of the generalization performance of gradient descent requires analyzing the interaction between these various forms of implicit regularization. We empirically demonstrate that the learning rate balances between low parameter norm and low sharpness of the trained model. We furthermore prove for diagonal linear networks trained on a simple regression task that neither implicit bias alone minimizes the generalization error. These findings demonstrate that focusing on a single implicit bias is insufficient to explain good generalization, and they motivate a broader view of implicit regularization that captures the dynamic trade-off between norm and sharpness induced by non-negligible learning rates.