 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiBERT: Introducing Linguistic Knowledge into BERT through a Lightweight Gated Injection Method
Oct 23, 2020



Large pre-trained language models such as BERT have been the driving force behind recent improvements across many NLP tasks. However, BERT is only trained to predict missing words - either behind masks or in the next sentence - and has no knowledge of lexical, syntactic or semantic information beyond what it picks up through unsupervised pre-training. We propose a novel method to explicitly inject linguistic knowledge in the form of word embeddings into any layer of a pre-trained BERT. Our performance improvements on multiple semantic similarity datasets when injecting dependency-based and counter-fitted embeddings indicate that such information is beneficial and currently missing from the original model. Our qualitative analysis shows that counter-fitted embedding injection particularly helps with cases involving synonym pairs.
QMUL-SDS at CheckThat! 2020: Determining COVID-19 Tweet Check-Worthiness Using an Enhanced CT-BERT with Numeric Expressions
Aug 30, 2020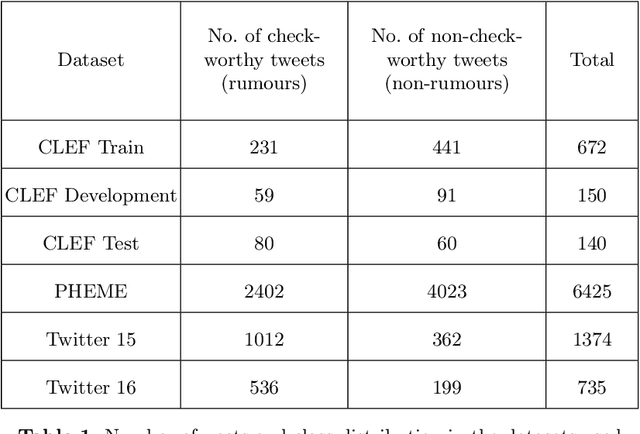
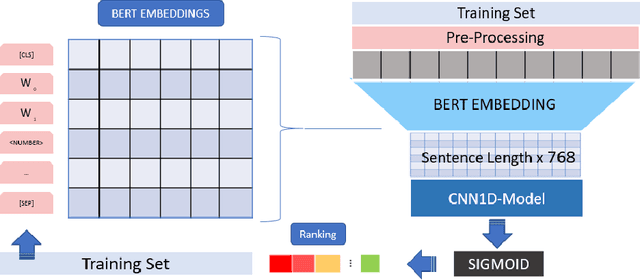
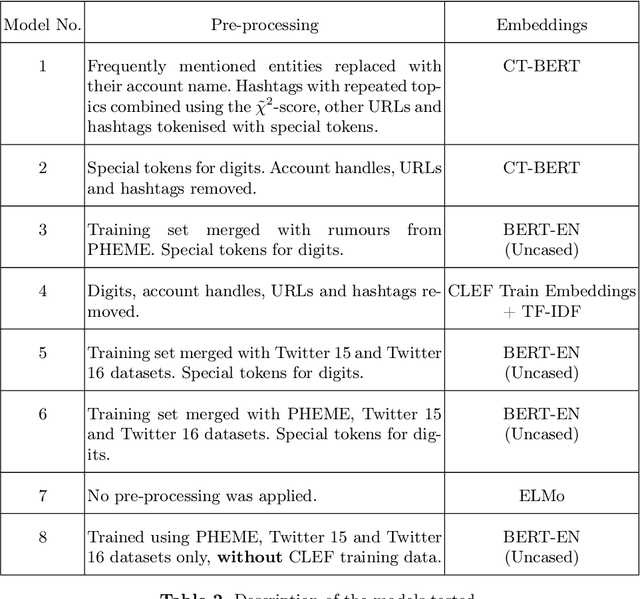
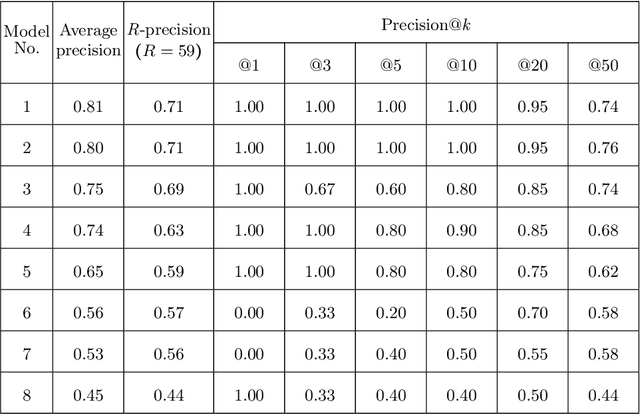
This paper describes the participation of the QMUL-SDS team for Task 1 of the CLEF 2020 CheckThat! shared task. The purpose of this task is to determine the check-worthiness of tweets about COVID-19 to identify and prioritise tweets that need fact-checking. The overarching aim is to further support ongoing efforts to protect the public from fake news and help people find reliable information. We describe and analyse the results of our submissions. We show that a CNN using COVID-Twitter-BERT (CT-BERT) enhanced with numeric expressions can effectively boost performance from baseline results. We also show results of training data augmentation with rumours on other topics. Our best system ranked fourth in the task with encouraging outcomes showing potential for improved results in the future.
Learning to Detect Bipolar Disorder and Borderline Personality Disorder with Language and Speech in Non-Clinical Interviews
Aug 08, 2020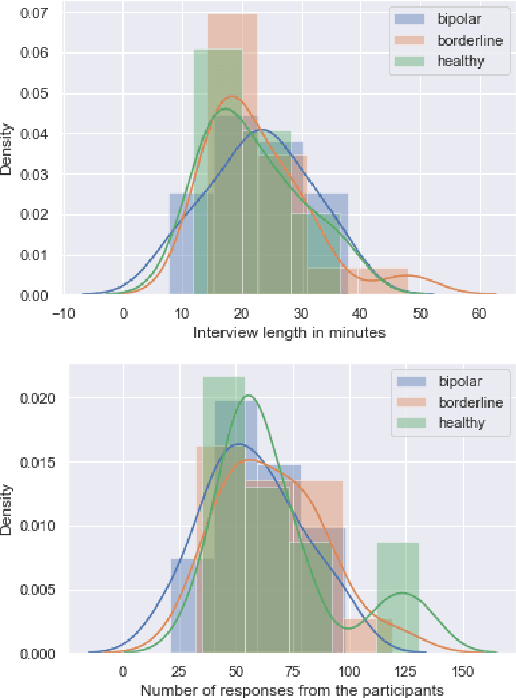
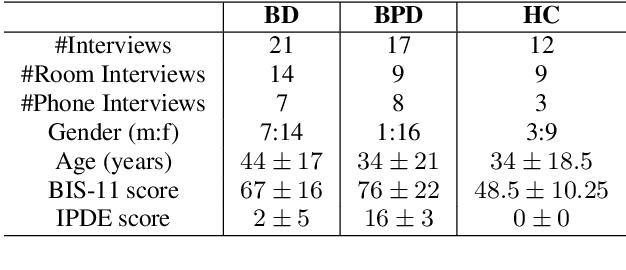
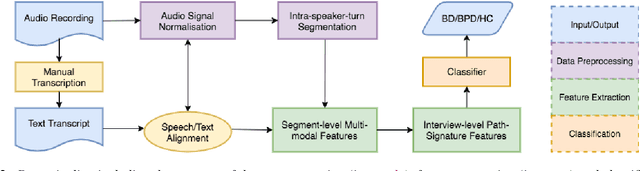

Bipolar disorder (BD) and borderline personality disorder (BPD) are both chronic psychiatric disorders. However, their overlapping symptoms and common comorbidity make it challenging for the clinicians to distinguish the two conditions on the basis of a clinical interview. In this work, we first present a new multi-modal dataset containing interviews involving individuals with BD or BPD being interviewed about a non-clinical topic . We investigate the automatic detection of the two conditions, and demonstrate a good linear classifier that can be learnt using a down-selected set of features from the different aspects of the interviews and a novel approach of summarising these features. Finally, we find that different sets of features characterise BD and BPD, thus providing insights into the difference between the automatic screening of the two conditions.
Measuring prominence of scientific work in online news as a proxy for impact
Jul 28, 2020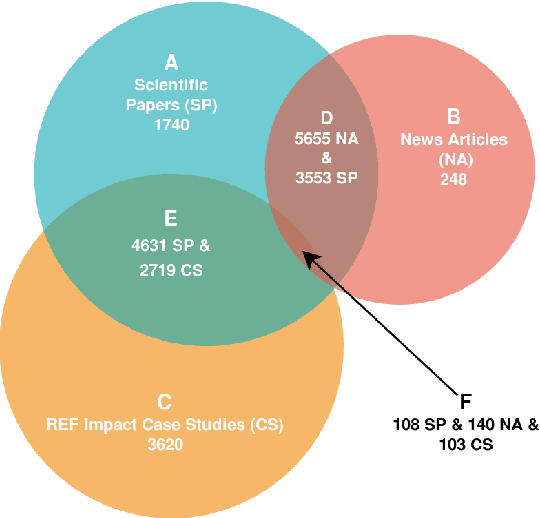

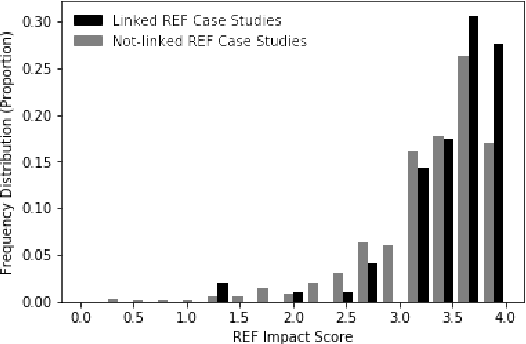

The impact made by a scientific paper on the work of other academics has many established metrics, including metrics based on citation counts and social media commenting. However, determination of the impact of a scientific paper on the wider society is less well established. For example, is it important for scientific work to be newsworthy? Here we present a new corpus of newspaper articles linked to the scientific papers that they describe. We find that Impact Case studies submitted to the UK Research Excellence Framework (REF) 2014 that refer to scientific papers mentioned in newspaper articles were awarded a higher score in the REF assessment. The papers associated with these case studies also feature prominently in the newspaper articles. We hypothesise that such prominence can be a useful proxy for societal impact. We therefore provide a novel baseline approach for measuring the prominence of scientific papers mentioned within news articles. Our measurement of prominence is based on semantic similarity through a graph-based ranking algorithm. We find that scientific papers with an associated REF case study are more likely to have a stronger prominence score. This supports our hypothesis that linguistic prominence in news can be used to suggest the wider non-academic impact of scientific work.
Better Early than Late: Fusing Topics with Word Embeddings for Neural Question Paraphrase Identification
Jul 22, 2020



Question paraphrase identification is a key task in Community Question Answering (CQA) to determine if an incoming question has been previously asked. Many current models use word embeddings to identify duplicate questions, but the use of topic models in feature-engineered systems suggests that they can be helpful for this task, too. We therefore propose two ways of merging topics with word embeddings (early vs. late fusion) in a new neural architecture for question paraphrase identification. Our results show that our system outperforms neural baselines on multiple CQA datasets, while an ablation study highlights the importance of topics and especially early topic-embedding fusion in our architecture.
Estimating predictive uncertainty for rumour verification models
May 14, 2020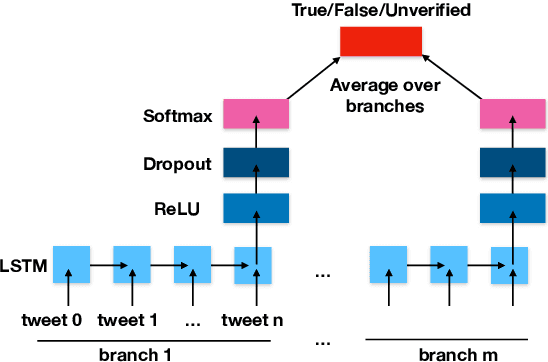
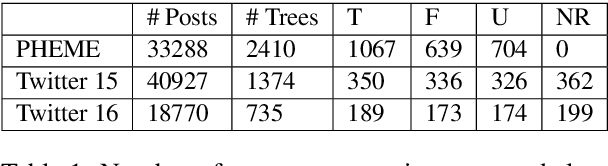

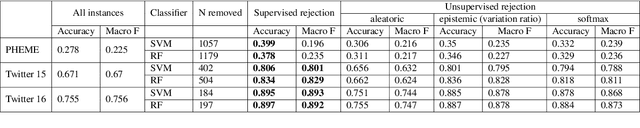
The inability to correctly resolve rumours circulating online can have harmful real-world consequences. We present a method for incorporating model and data uncertainty estimates into natural language processing models for automatic rumour verification. We show that these estimates can be used to filter out model predictions likely to be erroneous, so that these difficult instances can be prioritised by a human fact-checker. We propose two methods for uncertainty-based instance rejection, supervised and unsupervised. We also show how uncertainty estimates can be used to interpret model performance as a rumour unfolds.
Autoencoding Word Representations through Time for Semantic Change Detection
Apr 28, 2020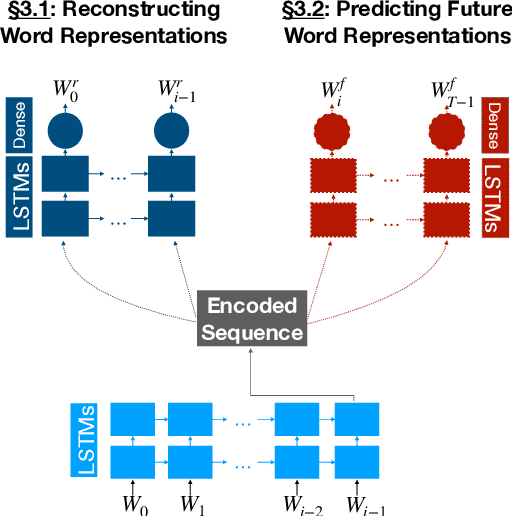
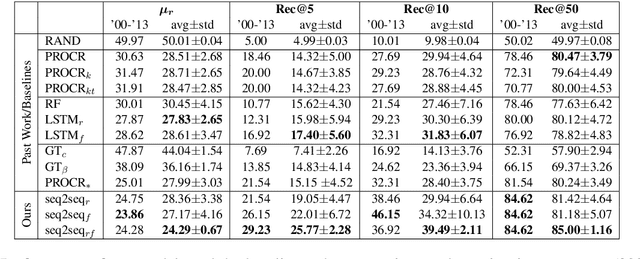
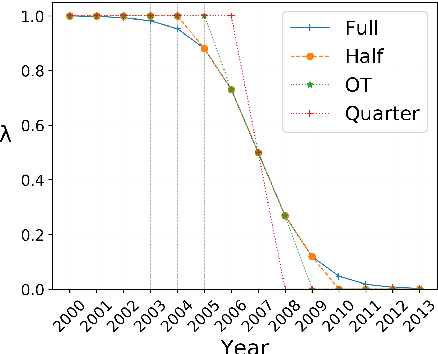
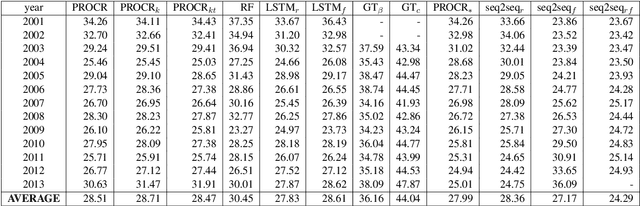
Semantic change detection concerns the task of identifying words whose meaning has changed over time. The current state-of-the-art detects the level of semantic change in a word by comparing its vector representation in two distinct time periods, without considering its evolution through time. In this work, we propose three variants of sequential models for detecting semantically shifted words, effectively accounting for the changes in the word representations over time, in a temporally sensitive manner. Through extensive experimentation under various settings with both synthetic and real data we showcase the importance of sequential modelling of word vectors through time for detecting the words whose semantics have changed the most. Finally, we take a step towards comparing different approaches in a quantitative manner, demonstrating that the temporal modelling of word representations yields a clear-cut advantage in performance.
How we do things with words: Analyzing text as social and cultural data
Jul 02, 2019In this article we describe our experiences with computational text analysis. We hope to achieve three primary goals. First, we aim to shed light on thorny issues not always at the forefront of discussions about computational text analysis methods. Second, we hope to provide a set of best practices for working with thick social and cultural concepts. Our guidance is based on our own experiences and is therefore inherently imperfect. Still, given our diversity of disciplinary backgrounds and research practices, we hope to capture a range of ideas and identify commonalities that will resonate for many. And this leads to our final goal: to help promote interdisciplinary collaborations. Interdisciplinary insights and partnerships are essential for realizing the full potential of any computational text analysis that involves social and cultural concepts, and the more we are able to bridge these divides, the more fruitful we believe our work will be.
RumourEval 2019: Determining Rumour Veracity and Support for Rumours
Sep 18, 2018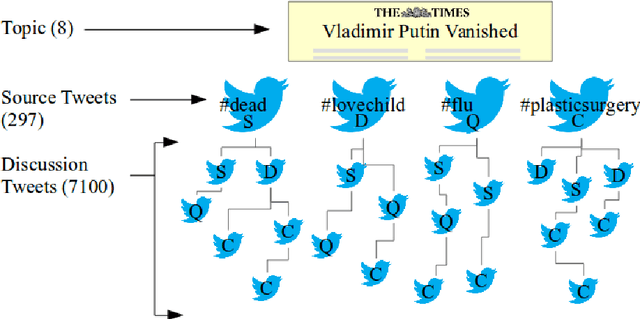
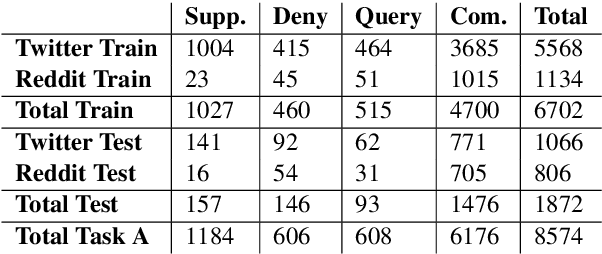
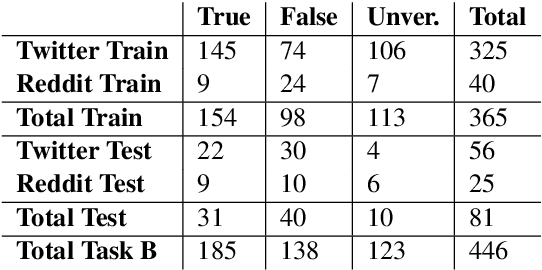
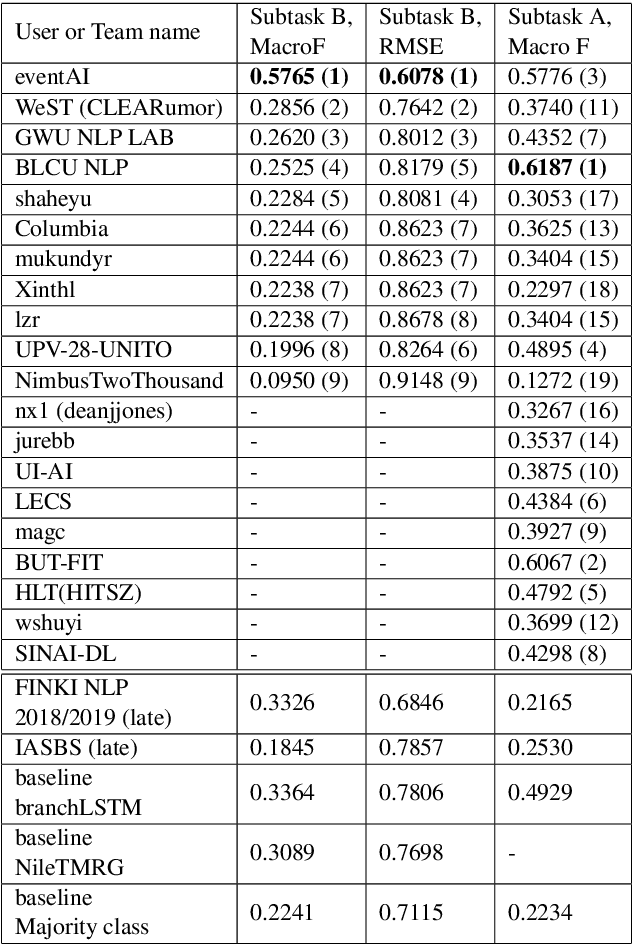
This is the proposal for RumourEval-2019, which will run in early 2019 as part of that year's SemEval event. Since the first RumourEval shared task in 2017, interest in automated claim validation has greatly increased, as the dangers of "fake news" have become a mainstream concern. Yet automated support for rumour checking remains in its infancy. For this reason, it is important that a shared task in this area continues to provide a focus for effort, which is likely to increase. We therefore propose a continuation in which the veracity of further rumours is determined, and as previously, supportive of this goal, tweets discussing them are classified according to the stance they take regarding the rumour. Scope is extended compared with the first RumourEval, in that the dataset is substantially expanded to include Reddit as well as Twitter data, and additional languages are also included.
Nowcasting the Stance of Social Media Users in a Sudden Vote: The Case of the Greek Referendum
Aug 26, 2018Modelling user voting intention in social media is an important research area, with applications in analysing electorate behaviour, online political campaigning and advertising. Previous approaches mainly focus on predicting national general elections, which are regularly scheduled and where data of past results and opinion polls are available. However, there is no evidence of how such models would perform during a sudden vote under time-constrained circumstances. That poses a more challenging task compared to traditional elections, due to its spontaneous nature. In this paper, we focus on the 2015 Greek bailout referendum, aiming to nowcast on a daily basis the voting intention of 2,197 Twitter users. We propose a semi-supervised multiple convolution kernel learning approach, leveraging temporally sensitive text and network information. Our evaluation under a real-time simulation framework demonstrates the effectiveness and robustness of our approach against competitive baselines, achieving a significant 20% increase in F-score compared to solely text-based models.