 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Token-Level Confidence Improves Caption Correctness
May 11, 2023



The ability to judge whether a caption correctly describes an image is a critical part of vision-language understanding. However, state-of-the-art models often misinterpret the correctness of fine-grained details, leading to errors in outputs such as hallucinating objects in generated captions or poor compositional reasoning. In this work, we explore Token-Level Confidence, or TLC, as a simple yet surprisingly effective method to assess caption correctness. Specifically, we fine-tune a vision-language model on image captioning, input an image and proposed caption to the model, and aggregate either algebraic or learned token confidences over words or sequences to estimate image-caption consistency. Compared to sequence-level scores from pretrained models, TLC with algebraic confidence measures achieves a relative improvement in accuracy by 10% on verb understanding in SVO-Probes and outperforms prior state-of-the-art in image and group scores for compositional reasoning in Winoground by a relative 37% and 9%, respectively. When training data are available, a learned confidence estimator provides further improved performance, reducing object hallucination rates in MS COCO Captions by a relative 30% over the original model and setting a new state-of-the-art.
Learn2Augment: Learning to Composite Videos for Data Augmentation in Action Recognition
Jun 09, 2022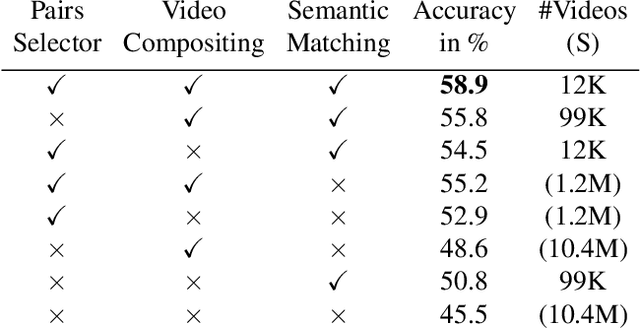


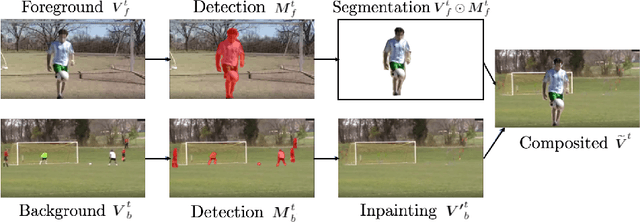
We address the problem of data augmentation for video action recognition. Standard augmentation strategies in video are hand-designed and sample the space of possible augmented data points either at random, without knowing which augmented points will be better, or through heuristics. We propose to learn what makes a good video for action recognition and select only high-quality samples for augmentation. In particular, we choose video compositing of a foreground and a background video as the data augmentation process, which results in diverse and realistic new samples. We learn which pairs of videos to augment without having to actually composite them. This reduces the space of possible augmentations, which has two advantages: it saves computational cost and increases the accuracy of the final trained classifier, as the augmented pairs are of higher quality than average. We present experimental results on the entire spectrum of training settings: few-shot, semi-supervised and fully supervised. We observe consistent improvements across all of them over prior work and baselines on Kinetics, UCF101, HMDB51, and achieve a new state-of-the-art on settings with limited data. We see improvements of up to 8.6% in the semi-supervised setting.
Reliable Visual Question Answering: Abstain Rather Than Answer Incorrectly
Apr 28, 2022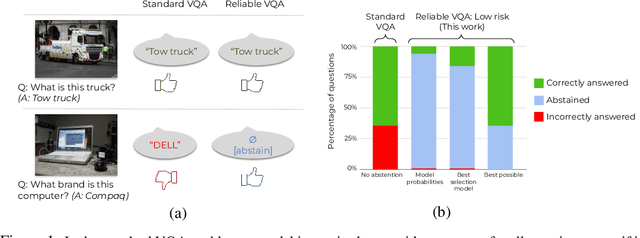
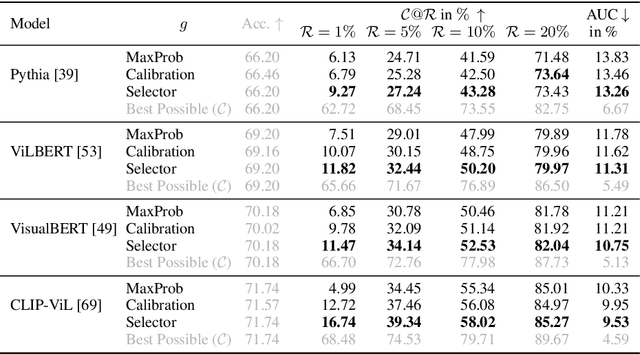


Machine learning has advanced dramatically, narrowing the accuracy gap to humans in multimodal tasks like visual question answering (VQA). However, while humans can say "I don't know" when they are uncertain (i.e., abstain from answering a question), such ability has been largely neglected in multimodal research, despite the importance of this problem to the usage of VQA in real settings. In this work, we promote a problem formulation for reliable VQA, where we prefer abstention over providing an incorrect answer. We first enable abstention capabilities for several VQA models, and analyze both their coverage, the portion of questions answered, and risk, the error on that portion. For that we explore several abstention approaches. We find that although the best performing models achieve over 71% accuracy on the VQA v2 dataset, introducing the option to abstain by directly using a model's softmax scores limits them to answering less than 8% of the questions to achieve a low risk of error (i.e., 1%). This motivates us to utilize a multimodal selection function to directly estimate the correctness of the predicted answers, which we show can triple the coverage from, for example, 5.0% to 16.7% at 1% risk. While it is important to analyze both coverage and risk, these metrics have a trade-off which makes comparing VQA models challenging. To address this, we also propose an Effective Reliability metric for VQA that places a larger cost on incorrect answers compared to abstentions. This new problem formulation, metric, and analysis for VQA provide the groundwork for building effective and reliable VQA models that have the self-awareness to abstain if and only if they don't know the answer.
Learning To Recognize Procedural Activities with Distant Supervision
Jan 26, 2022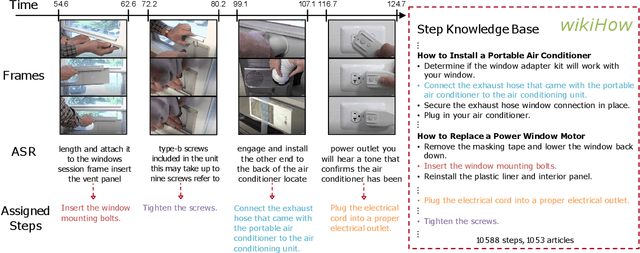

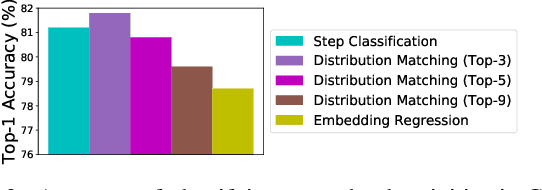

In this paper we consider the problem of classifying fine-grained, multi-step activities (e.g., cooking different recipes, making disparate home improvements, creating various forms of arts and crafts) from long videos spanning up to several minutes. Accurately categorizing these activities requires not only recognizing the individual steps that compose the task but also capturing their temporal dependencies. This problem is dramatically different from traditional action classification, where models are typically optimized on videos that span only a few seconds and that are manually trimmed to contain simple atomic actions. While step annotations could enable the training of models to recognize the individual steps of procedural activities, existing large-scale datasets in this area do not include such segment labels due to the prohibitive cost of manually annotating temporal boundaries in long videos. To address this issue, we propose to automatically identify steps in instructional videos by leveraging the distant supervision of a textual knowledge base (wikiHow) that includes detailed descriptions of the steps needed for the execution of a wide variety of complex activities. Our method uses a language model to match noisy, automatically-transcribed speech from the video to step descriptions in the knowledge base. We demonstrate that video models trained to recognize these automatically-labeled steps (without manual supervision) yield a representation that achieves superior generalization performance on four downstream tasks: recognition of procedural activities, step classification, step forecasting and egocentric video classification.
FLAVA: A Foundational Language And Vision Alignment Model
Dec 08, 2021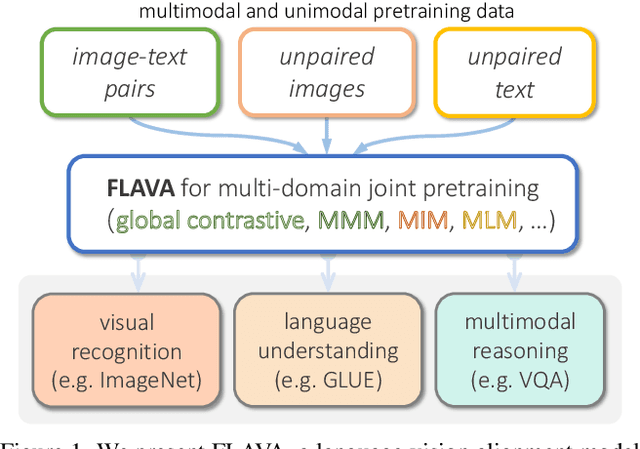
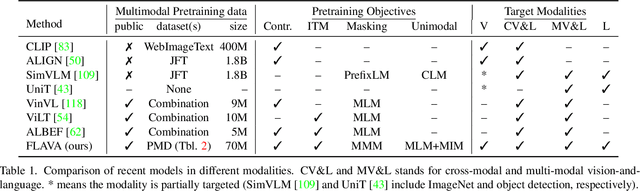
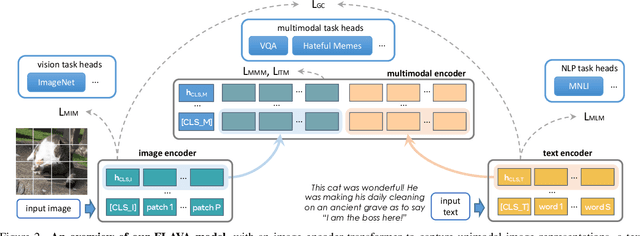
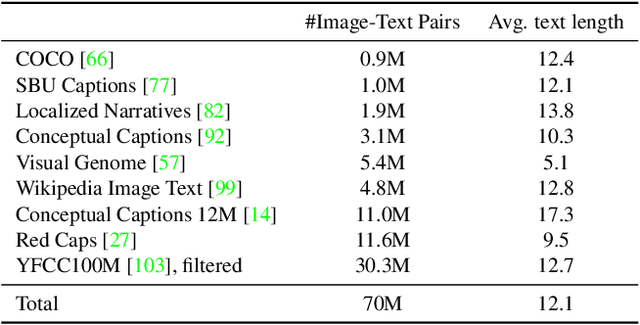
State-of-the-art vision and vision-and-language models rely on large-scale visio-linguistic pretraining for obtaining good performance on a variety of downstream tasks. Generally, such models are often either cross-modal (contrastive) or multi-modal (with earlier fusion) but not both; and they often only target specific modalities or tasks. A promising direction would be to use a single holistic universal model, as a "foundation", that targets all modalities at once -- a true vision and language foundation model should be good at vision tasks, language tasks, and cross- and multi-modal vision and language tasks. We introduce FLAVA as such a model and demonstrate impressive performance on a wide range of 35 tasks spanning these target modalities.
A New Split for Evaluating True Zero-Shot Action Recognition
Jul 27, 2021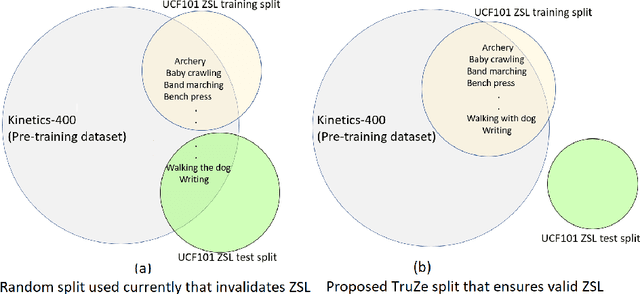
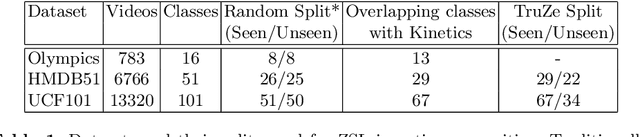
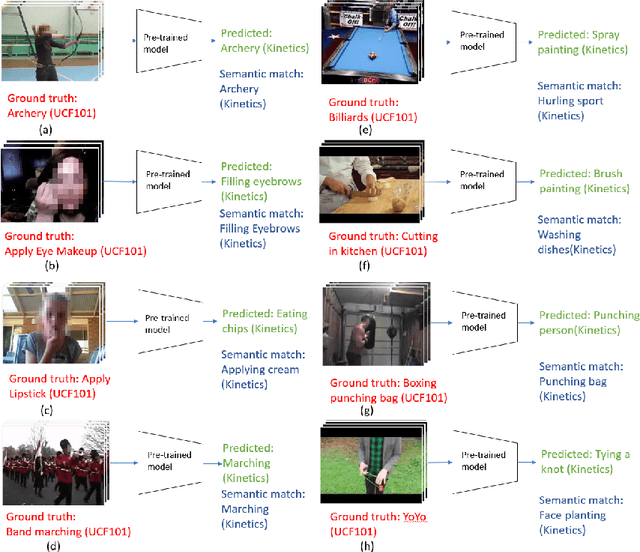
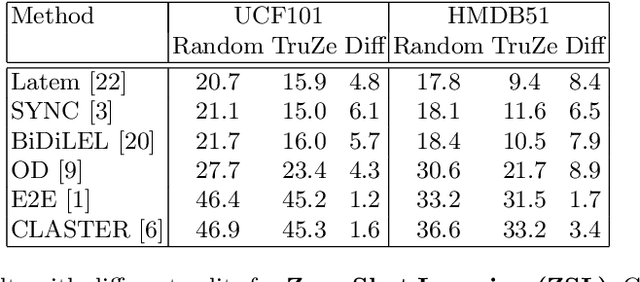
Zero-shot action recognition is the task of classifying action categories that are not available in the training set. In this setting, the standard evaluation protocol is to use existing action recognition datasets (e.g. UCF101) and randomly split the classes into seen and unseen. However, most recent work builds on representations pre-trained on the Kinetics dataset, where classes largely overlap with classes in the zero-shot evaluation datasets. As a result, classes which are supposed to be unseen, are present during supervised pre-training, invalidating the condition of the zero-shot setting. A similar concern was previously noted several years ago for image based zero-shot recognition, but has not been considered by the zero-shot action recognition community. In this paper, we propose a new split for true zero-shot action recognition with no overlap between unseen test classes and training or pre-training classes. We benchmark several recent approaches on the proposed True Zero-Shot (TruZe) Split for UCF101 and HMDB51, with zero-shot and generalized zero-shot evaluation. In our extensive analysis we find that our TruZe splits are significantly harder than comparable random splits as nothing is leaking from pre-training, i.e. unseen performance is consistently lower, up to 9.4% for zero-shot action recognition. In an additional evaluation we also find that similar issues exist in the splits used in few-shot action recognition, here we see differences of up to 14.1%. We publish our splits and hope that our benchmark analysis will change how the field is evaluating zero- and few-shot action recognition moving forward.
CLASTER: Clustering with Reinforcement Learning for Zero-Shot Action Recognition
Jan 18, 2021
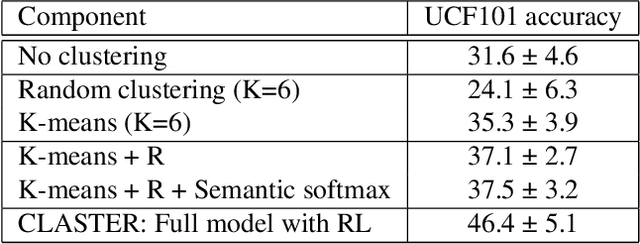
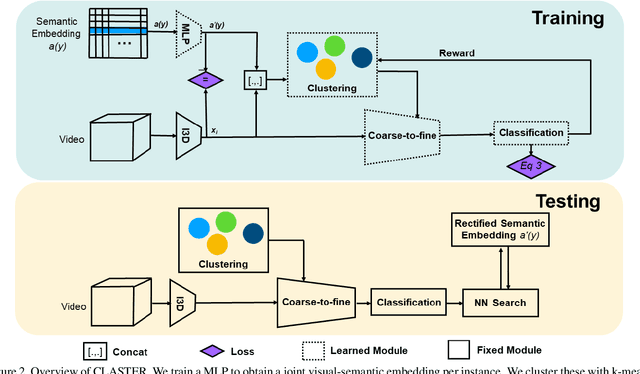
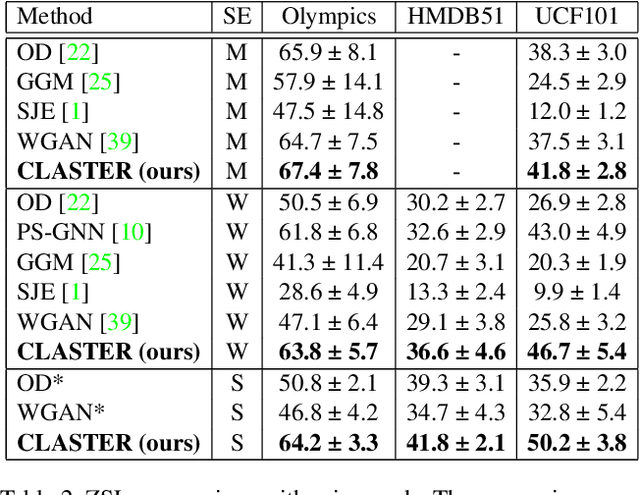
Zero-shot action recognition is the task of recognizing action classes without visual examples, only with a semantic embedding which relates unseen to seen classes. The problem can be seen as learning a function which generalizes well to instances of unseen classes without losing discrimination between classes. Neural networks can model the complex boundaries between visual classes, which explains their success as supervised models. However, in zero-shot learning, these highly specialized class boundaries may not transfer well from seen to unseen classes. In this paper, we propose a clustering-based model, which considers all training samples at once, instead of optimizing for each instance individually. We optimize the clustering using Reinforcement Learning which we show is critical for our approach to work. We call the proposed method CLASTER and observe that it consistently improves over the state-of-the-art in all standard datasets, UCF101, HMDB51, and Olympic Sports; both in the standard zero-shot evaluation and the generalized zero-shot learning.
KRISP: Integrating Implicit and Symbolic Knowledge for Open-Domain Knowledge-Based VQA
Dec 20, 2020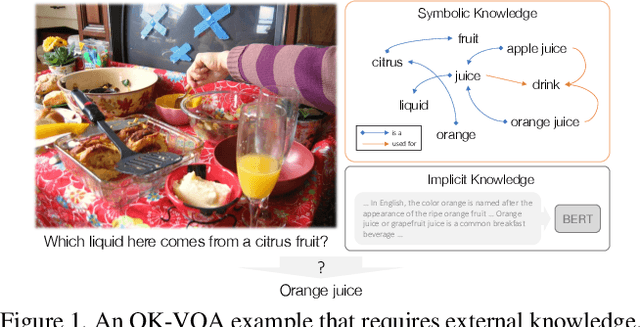



One of the most challenging question types in VQA is when answering the question requires outside knowledge not present in the image. In this work we study open-domain knowledge, the setting when the knowledge required to answer a question is not given/annotated, neither at training nor test time. We tap into two types of knowledge representations and reasoning. First, implicit knowledge which can be learned effectively from unsupervised language pre-training and supervised training data with transformer-based models. Second, explicit, symbolic knowledge encoded in knowledge bases. Our approach combines both - exploiting the powerful implicit reasoning of transformer models for answer prediction, and integrating symbolic representations from a knowledge graph, while never losing their explicit semantics to an implicit embedding. We combine diverse sources of knowledge to cover the wide variety of knowledge needed to solve knowledge-based questions. We show our approach, KRISP (Knowledge Reasoning with Implicit and Symbolic rePresentations), significantly outperforms state-of-the-art on OK-VQA, the largest available dataset for open-domain knowledge-based VQA. We show with extensive ablations that while our model successfully exploits implicit knowledge reasoning, the symbolic answer module which explicitly connects the knowledge graph to the answer vocabulary is critical to the performance of our method and generalizes to rare answers.
SMART Frame Selection for Action Recognition
Dec 19, 2020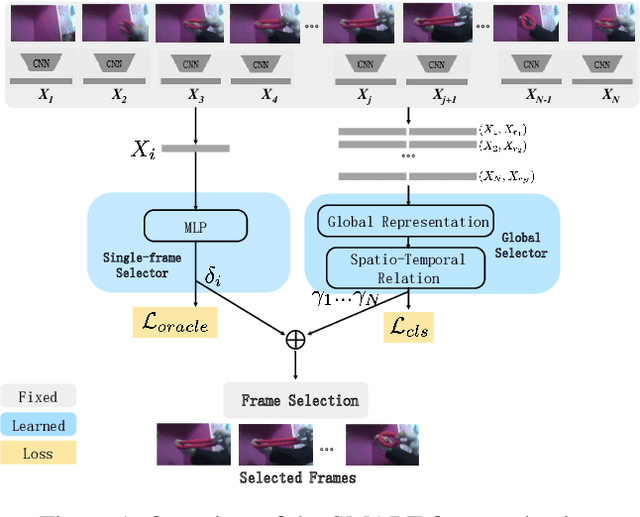
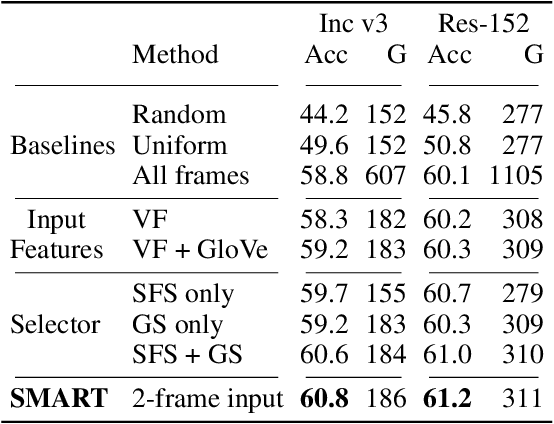

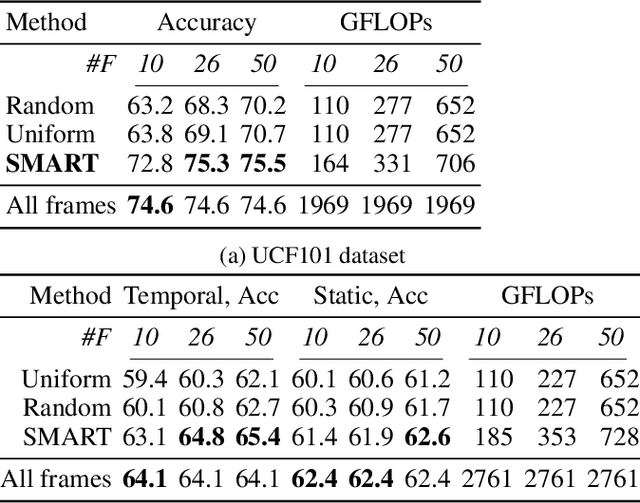
Action recognition is computationally expensive. In this paper, we address the problem of frame selection to improve the accuracy of action recognition. In particular, we show that selecting good frames helps in action recognition performance even in the trimmed videos domain. Recent work has successfully leveraged frame selection for long, untrimmed videos, where much of the content is not relevant, and easy to discard. In this work, however, we focus on the more standard short, trimmed action recognition problem. We argue that good frame selection can not only reduce the computational cost of action recognition but also increase the accuracy by getting rid of frames that are hard to classify. In contrast to previous work, we propose a method that instead of selecting frames by considering one at a time, considers them jointly. This results in a more efficient selection, where good frames are more effectively distributed over the video, like snapshots that tell a story. We call the proposed frame selection SMART and we test it in combination with different backbone architectures and on multiple benchmarks (Kinetics, Something-something, UCF101). We show that the SMART frame selection consistently improves the accuracy compared to other frame selection strategies while reducing the computational cost by a factor of 4 to 10 times. Additionally, we show that when the primary goal is recognition performance, our selection strategy can improve over recent state-of-the-art models and frame selection strategies on various benchmarks (UCF101, HMDB51, FCVID, and ActivityNet).
Remembering for the Right Reasons: Explanations Reduce Catastrophic Forgetting
Oct 04, 2020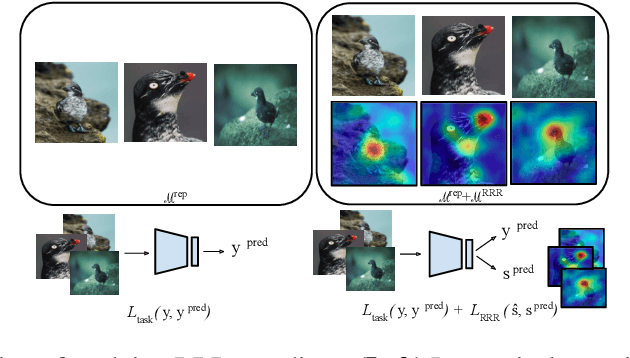

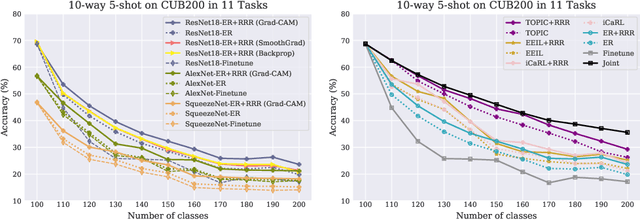

The goal of continual learning (CL) is to learn a sequence of tasks without suffering from the phenomenon of catastrophic forgetting. Previous work has shown that leveraging memory in the form of a replay buffer can reduce performance degradation on prior tasks. We hypothesize that forgetting can be further reduced when the model is encouraged to remember the \textit{evidence} for previously made decisions. As a first step towards exploring this hypothesis, we propose a simple novel training paradigm, called Remembering for the Right Reasons (RRR), that additionally stores visual model explanations for each example in the buffer and ensures the model has "the right reasons" for its predictions by encouraging its explanations to remain consistent with those used to make decisions at training time. Without this constraint, there is a drift in explanations and increase in forgetting as conventional continual learning algorithms learn new tasks. We demonstrate how RRR can be easily added to any memory or regularization-based approach and results in reduced forgetting, and more importantly, improved model explanations. We have evaluated our approach in the standard and few-shot settings and observed a consistent improvement across various CL approaches using different architectures and techniques to generate model explanations and demonstrated our approach showing a promising connection between explainability and continual learning. Our code is available at https://github.com/SaynaEbrahimi/Remembering-for-the-Right-Reasons.