 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Consistent Discounting
Jul 27, 2011A possibly immortal agent tries to maximise its summed discounted rewards over time, where discounting is used to avoid infinite utilities and encourage the agent to value current rewards more than future ones. Some commonly used discount functions lead to time-inconsistent behavior where the agent changes its plan over time. These inconsistencies can lead to very poor behavior. We generalise the usual discounted utility model to one where the discount function changes with the age of the agent. We then give a simple characterisation of time-(in)consistent discount functions and show the existence of a rational policy for an agent that knows its discount function is time-inconsistent.
* 17 LaTeX pages, 5 figures
Axioms for Rational Reinforcement Learning
Jul 27, 2011We provide a formal, simple and intuitive theory of rational decision making including sequential decisions that affect the environment. The theory has a geometric flavor, which makes the arguments easy to visualize and understand. Our theory is for complete decision makers, which means that they have a complete set of preferences. Our main result shows that a complete rational decision maker implicitly has a probabilistic model of the environment. We have a countable version of this result that brings light on the issue of countable vs finite additivity by showing how it depends on the geometry of the space which we have preferences over. This is achieved through fruitfully connecting rationality with the Hahn-Banach Theorem. The theory presented here can be viewed as a formalization and extension of the betting odds approach to probability of Ramsey and De Finetti.
* 16 LaTeX pages
A Philosophical Treatise of Universal Induction
May 28, 2011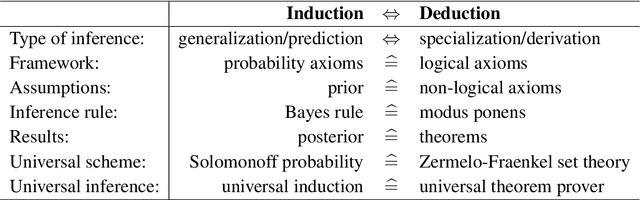
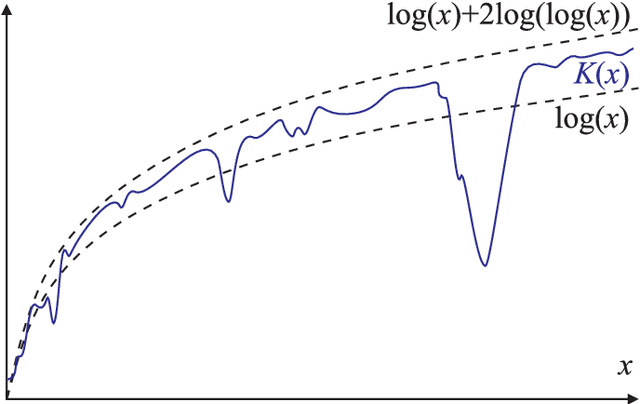
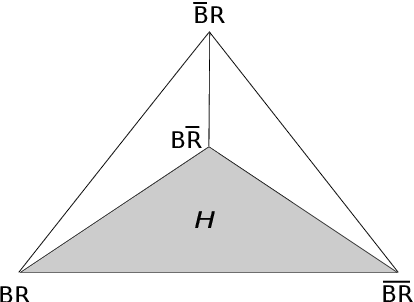
Understanding inductive reasoning is a problem that has engaged mankind for thousands of years. This problem is relevant to a wide range of fields and is integral to the philosophy of science. It has been tackled by many great minds ranging from philosophers to scientists to mathematicians, and more recently computer scientists. In this article we argue the case for Solomonoff Induction, a formal inductive framework which combines algorithmic information theory with the Bayesian framework. Although it achieves excellent theoretical results and is based on solid philosophical foundations, the requisite technical knowledge necessary for understanding this framework has caused it to remain largely unknown and unappreciated in the wider scientific community. The main contribution of this article is to convey Solomonoff induction and its related concepts in a generally accessible form with the aim of bridging this current technical gap. In the process we examine the major historical contributions that have led to the formulation of Solomonoff Induction as well as criticisms of Solomonoff and induction in general. In particular we examine how Solomonoff induction addresses many issues that have plagued other inductive systems, such as the black ravens paradox and the confirmation problem, and compare this approach with other recent approaches.
* 72 pages, 2 figures, 1 table, LaTeX
Algorithmic Randomness as Foundation of Inductive Reasoning and Artificial Intelligence
Feb 12, 2011This article is a brief personal account of the past, present, and future of algorithmic randomness, emphasizing its role in inductive inference and artificial intelligence. It is written for a general audience interested in science and philosophy. Intuitively, randomness is a lack of order or predictability. If randomness is the opposite of determinism, then algorithmic randomness is the opposite of computability. Besides many other things, these concepts have been used to quantify Ockham's razor, solve the induction problem, and define intelligence.
* 9 LaTeX pages
Universal Learning Theory
Feb 12, 2011This encyclopedic article gives a mini-introduction into the theory of universal learning, founded by Ray Solomonoff in the 1960s and significantly developed and extended in the last decade. It explains the spirit of universal learning, but necessarily glosses over technical subtleties.
* 12 LaTeX pages
A Monte Carlo AIXI Approximation
Dec 26, 2010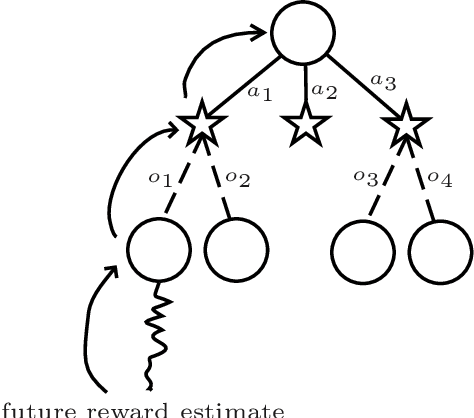
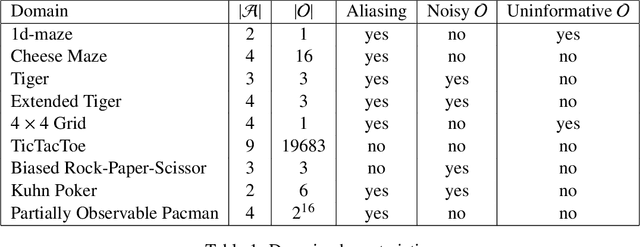
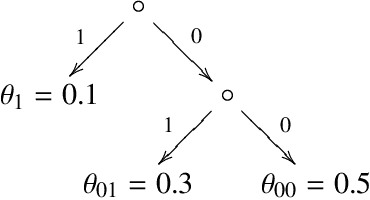
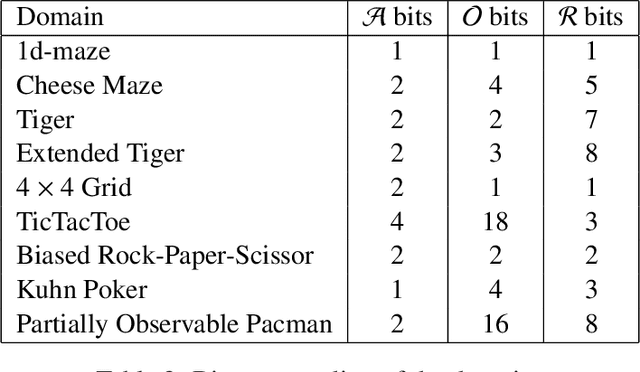
This paper introduces a principled approach for the design of a scalable general reinforcement learning agent. Our approach is based on a direct approximation of AIXI, a Bayesian optimality notion for general reinforcement learning agents. Previously, it has been unclear whether the theory of AIXI could motivate the design of practical algorithms. We answer this hitherto open question in the affirmative, by providing the first computationally feasible approximation to the AIXI agent. To develop our approximation, we introduce a new Monte-Carlo Tree Search algorithm along with an agent-specific extension to the Context Tree Weighting algorithm. Empirically, we present a set of encouraging results on a variety of stochastic and partially observable domains. We conclude by proposing a number of directions for future research.
Model Selection by Loss Rank for Classification and Unsupervised Learning
Nov 05, 2010
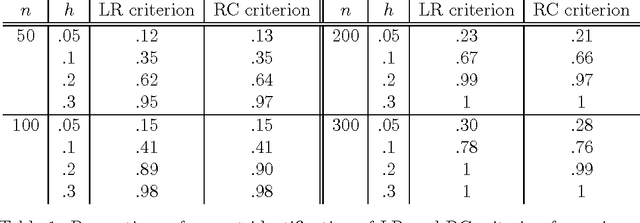
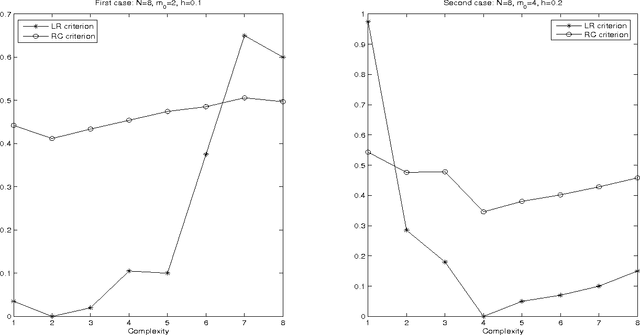
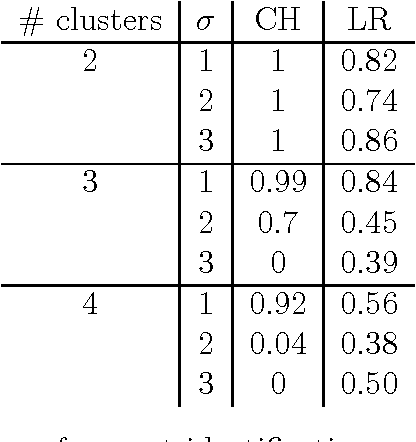
Hutter (2007) recently introduced the loss rank principle (LoRP) as a generalpurpose principle for model selection. The LoRP enjoys many attractive properties and deserves further investigations. The LoRP has been well-studied for regression framework in Hutter and Tran (2010). In this paper, we study the LoRP for classification framework, and develop it further for model selection problems in unsupervised learning where the main interest is to describe the associations between input measurements, like cluster analysis or graphical modelling. Theoretical properties and simulation studies are presented.
Featureless 2D-3D Pose Estimation by Minimising an Illumination-Invariant Loss
Nov 03, 2010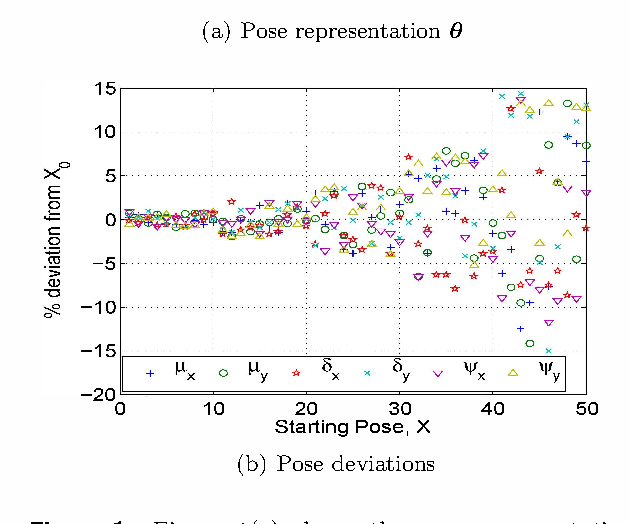
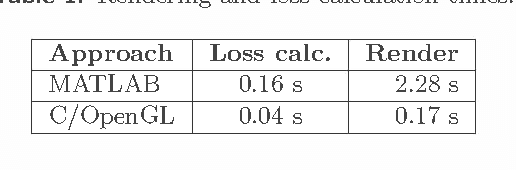
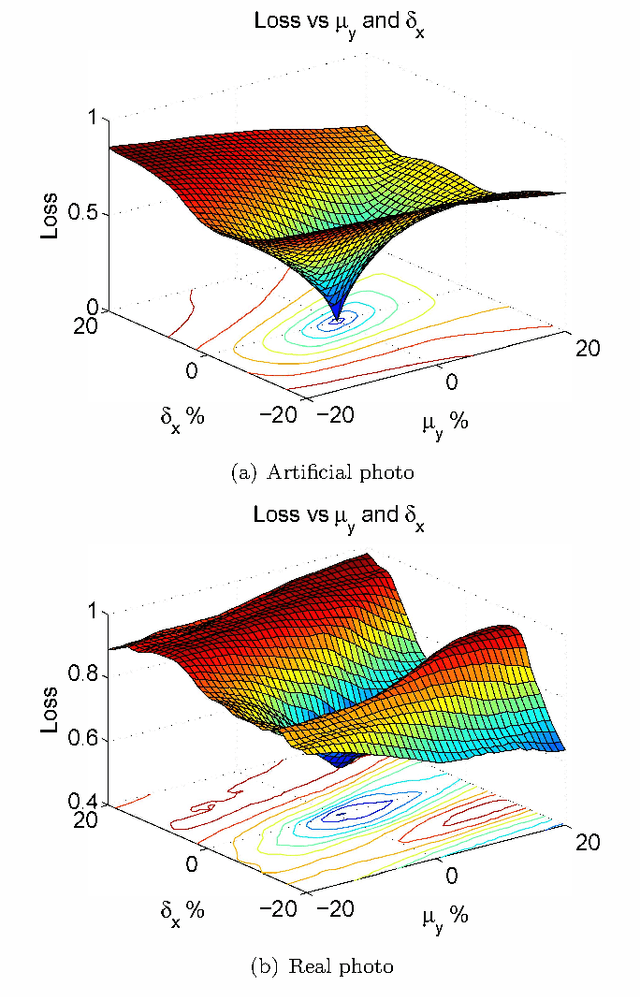

The problem of identifying the 3D pose of a known object from a given 2D image has important applications in Computer Vision ranging from robotic vision to image analysis. Our proposed method of registering a 3D model of a known object on a given 2D photo of the object has numerous advantages over existing methods: It does neither require prior training nor learning, nor knowledge of the camera parameters, nor explicit point correspondences or matching features between image and model. Unlike techniques that estimate a partial 3D pose (as in an overhead view of traffic or machine parts on a conveyor belt), our method estimates the complete 3D pose of the object, and works on a single static image from a given view, and under varying and unknown lighting conditions. For this purpose we derive a novel illumination-invariant distance measure between 2D photo and projected 3D model, which is then minimised to find the best pose parameters. Results for vehicle pose detection are presented.
* 18 LaTeX pages, 7 figures
Consistency of Feature Markov Processes
Jul 13, 2010We are studying long term sequence prediction (forecasting). We approach this by investigating criteria for choosing a compact useful state representation. The state is supposed to summarize useful information from the history. We want a method that is asymptotically consistent in the sense it will provably eventually only choose between alternatives that satisfy an optimality property related to the used criterion. We extend our work to the case where there is side information that one can take advantage of and, furthermore, we briefly discuss the active setting where an agent takes actions to achieve desirable outcomes.
* 16 LaTeX pages
Reinforcement Learning via AIXI Approximation
Jul 13, 2010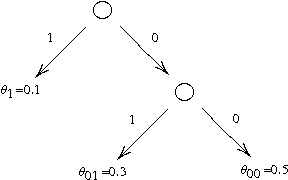
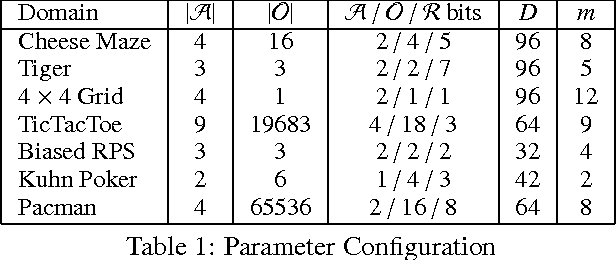
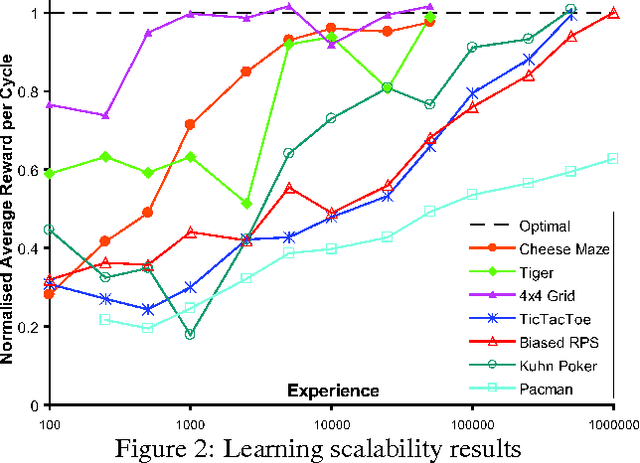

This paper introduces a principled approach for the design of a scalable general reinforcement learning agent. This approach is based on a direct approximation of AIXI, a Bayesian optimality notion for general reinforcement learning agents. Previously, it has been unclear whether the theory of AIXI could motivate the design of practical algorithms. We answer this hitherto open question in the affirmative, by providing the first computationally feasible approximation to the AIXI agent. To develop our approximation, we introduce a Monte Carlo Tree Search algorithm along with an agent-specific extension of the Context Tree Weighting algorithm. Empirically, we present a set of encouraging results on a number of stochastic, unknown, and partially observable domains.
* 8 LaTeX pages, 1 figure